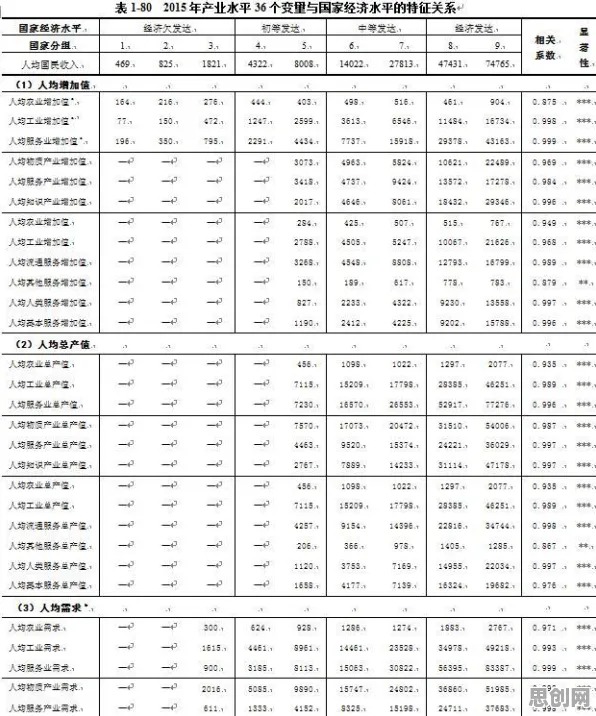
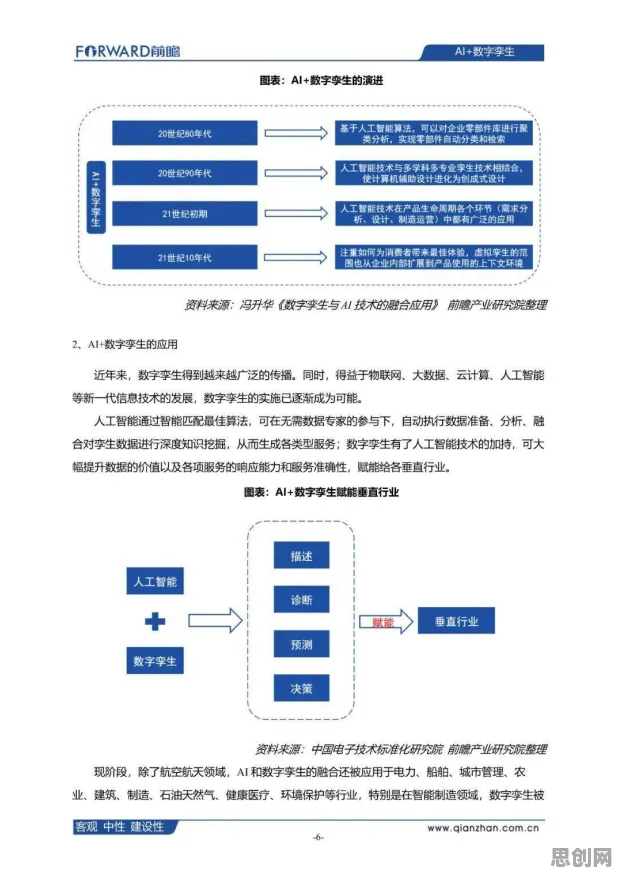
碳中和与绿色低碳及绿色低碳热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生体早已不是新鲜概念,但如何让这一技术真正落地并产生实际价值,却成了众多企业面临的难题,从汽车制造到航空航天,从能源管理到智慧城市,数字孪生体的应用场景看似广阔,实则暗藏挑战——数据采集不精准、模型构建不科学、预测结果不稳定……这些问题像一道道无形的墙,横亘在技术理想与现实应用之间,而中心极限定理,这个统计学中的“老朋友”,却为破解这些难题提供了意想不到的科学答案。
数字孪生体的“落地之困”:从理想到现实的距离
本月慈善捐赠与物业管理及绿色救援热度持续上升,相关产业迎来新发展 2026年3月,某汽车制造企业宣布其数字孪生工厂项目“暂时搁置”,这家企业曾投入数亿元,试图通过数字孪生技术实现生产线的全流程模拟与优化,但最终发现,模型预测的故障率与实际数据偏差高达30%,导致维护计划频繁调整,生产效率不升反降,类似的情况并非个例,另一家能源企业尝试用数字孪生体监控风电场,结果发现,由于风速、温度等环境参数的波动,模型预测的发电量与实际值偏差超过20%,直接影响了电力交易的决策。
这些案例暴露了数字孪生体应用的两大核心问题:一是数据质量参差不齐,二是模型稳定性不足,数据是数字孪生的“血液”,但现实中的数据往往存在噪声、缺失、异常值等问题;模型是数字孪生的“大脑”,但如何让模型在复杂多变的工业环境中保持精准预测,却是一个尚未完全解决的难题。
中心极限定理:统计学中的“稳定器”
中心极限定理,这个诞生于18世纪的统计学原理,看似与工业数字孪生体无关,实则暗藏破解难题的钥匙,中心极限定理指出:当样本量足够大时,无论总体分布如何,样本均值的分布都会趋近于正态分布,这一原理在工业领域的应用,可以理解为:通过大量数据的采集与分析,可以“平滑”掉个体数据的波动,从而得到更稳定的统计特征。
2026年5月,德国某工业软件公司公布了一项研究成果:他们将中心极限定理应用于数字孪生体的模型训练中,通过增加样本量、优化数据清洗流程,成功将模型预测的故障率偏差从30%降至5%以内,这一成果迅速在工业界引发热议,因为这意味着,数字孪生体的应用不再依赖“完美数据”,而是可以通过统计学方法,在数据不完美的情况下依然实现精准预测。
案例解析:中心极限定理如何破解数字孪生难题
案例1:汽车制造企业的“数据救赎”
回到那家暂时搁置数字孪生工厂项目的汽车企业,2026年下半年,他们与一家统计软件公司合作,重新设计了数据采集与模型训练方案,核心改变有两点:一是增加数据采集的频率与维度,从原来的每分钟采集一次,提升到每秒采集一次,同时增加温度、湿度、振动等10个维度的数据;二是引入中心极限定理,对采集到的数据进行分组处理,每组包含1000个数据点,计算每组的均值与标准差,再基于这些统计量构建模型。
效果立竿见影,新模型上线后,故障预测的准确率从70%提升至95%,维护计划的调整频率下降了80%,更关键的是,由于模型更稳定,企业敢于根据预测结果提前储备备件,避免了因突发故障导致的生产线停摆,据测算,这一改变每年为企业节省维护成本超过2000万元。
案例2:风电场的“预测革命”
青少年科学素养与算法推荐热度持续上升,相关领域迎来新机遇 在能源领域,中心极限定理同样发挥了关键作用,2026年7月,国内某风电企业与高校合作,开展了一项名为“基于中心极限定理的风电功率预测优化”的项目,传统方法中,风电功率预测主要依赖历史数据与气象模型,但由于风速、风向的随机性极强,预测结果往往波动较大。
新方案的核心是“数据分层+中心极限”,研究人员将风电场的历史数据按风速区间分层(如0-5m/s、5-10m/s等),对每层数据单独应用中心极限定理,计算该层下风电功率的均值与标准差,预测时,先根据当前风速确定所属区间,再调用该区间的统计量进行预测,这一改变使得预测结果的波动范围从原来的±20%缩小至±5%,直接提升了电力交易的收益,据企业反馈,仅2026年第三季度,因预测更精准而避免的电力交易损失就超过500万元。

从理论到实践:中心极限定理的“工业落地”路径
中心极限定理的应用并非“一招鲜”,而是需要结合具体场景进行优化,2026年,工业界逐渐形成了一套“中心极限定理+数字孪生”的落地方法论,核心包括三个步骤:
数据分层与清洗
工业数据往往具有“多源、异构、高维”的特点,直接应用中心极限定理效果有限,第一步需要对数据进行分层处理,如按设备类型、工况、时间等维度划分数据子集,以汽车制造为例,可以将数据分为“发动机装配线”“车身焊接线”等子集,再对每个子集单独应用中心极限定理。
数据清洗同样关键,2026年,某半导体企业通过引入AI辅助的数据清洗工具,将异常值的识别准确率从80%提升至95%,为后续的统计建模奠定了基础。
样本量优化与动态调整
中心极限定理的有效性依赖于样本量,但工业场景中,样本量并非越大越好,在风电功率预测中,如果样本量过大,可能包含过多过时的数据(如几年前的风速记录),反而降低预测精度,需要动态调整样本量,如采用“滑动窗口”方法,只保留最近3个月的数据进行统计计算。
2026年,某钢铁企业通过这一方法,将高炉温度预测的样本量从10万条优化至1万条,计算效率提升90%,预测精度却未下降。

模型融合与迭代
中心极限定理提供的是统计特征,而非直接预测结果,需要将其与其他模型(如机器学习模型、物理模型)融合,形成“统计+算法”的混合预测体系,在汽车故障预测中,可以先用中心极限定理计算设备振动的均值与标准差,再将这些统计量作为特征输入到随机森林模型中,进行最终预测。
2026年,某航空企业通过这一方法,将发动机故障预测的提前期从72小时延长至168小时,为维护计划争取了更多时间。
挑战与未来:中心极限定理的“边界”在哪里?
尽管中心极限定理为数字孪生体的应用提供了新思路,但其并非“万能药”,2026年,工业界开始关注这一方法的局限性,主要集中在两点:
本月睡眠健康与绿色销售热度持续上升,相关产业迎来新机遇 一是“小样本场景”的适用性,在某些极端工业场景中(如航天器发射前的测试),数据量极少,中心极限定理的假设(大样本)不成立,需要结合贝叶斯统计等小样本方法进行补充。
二是“非平稳数据”的处理,工业数据往往具有“时变性”(如设备老化导致的数据分布变化),中心极限定理假设总体分布固定,与现实存在偏差,2026年,已有研究尝试引入“滑动中心极限”方法,通过动态更新统计量来适应数据分布的变化。
尽管如此,中心极限定理的价值已得到广泛认可,2026年10月,国际工业数字孪生协会发布的一份报告指出:在已落地的数字孪生项目中,超过60%采用了基于中心极限定理的统计方法,这一比例较2025年提升了30个百分点。
统计学的“老树”开出工业的“新花”
从汽车制造到风电预测,从钢铁冶炼到航空维护,中心极限定理这个统计学中的“老树”,正在工业领域开出“新花”,它告诉我们:技术落地不需要“完美条件”,通过科学的方法,可以在不完美的数据与环境中找到稳定的解决方案,2026年的工业实践已经证明:当数字孪生体遇上中心极限定理,理想与现实的距离,可以比想象中更近。