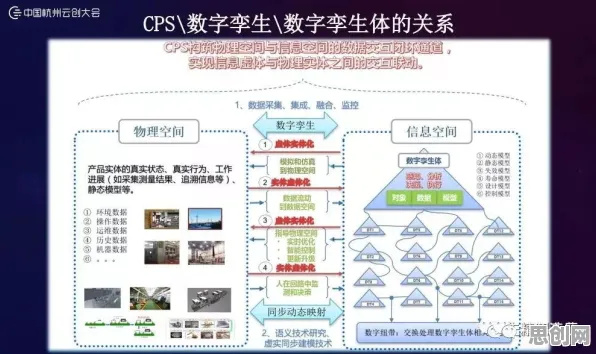
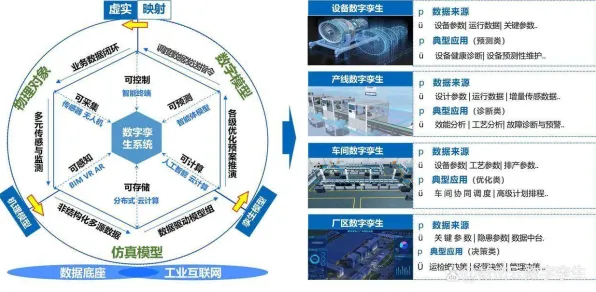
2026年的工业圈子里,"数字孪生技术落地实践分享会"几乎成了每月必办的保留节目,从上海张江的智能制造产业园到重庆两江新区的汽车工厂,从深圳南山区的3C电子企业到青岛西海岸的船舶重工,企业技术负责人、解决方案供应商、行业分析师们围坐在一起,用PPT展示着虚拟产线与物理产线同步运行的实时画面,讨论着如何用数字孪生优化设备维护周期、提升良品率、降低能耗,这种热闹场景背后,GPT模型等生成式AI技术的深度参与,正在重塑工业数字孪生的技术生态与应用逻辑。
GPT模型解决了数字孪生"最后一公里"的数据治理难题
本月量子计算与青少年教育及社会责任热度不断攀升,技术创新带来新突破 数字孪生的核心是"数据驱动",但工业场景的数据治理向来是块硬骨头,以某汽车零部件企业2026年的实践为例,其冲压车间的20台压力机每天产生超过500GB的数据,包括设备运行参数、传感器信号、质量检测结果等,但这些数据分散在PLC、SCADA、MES等不同系统中,格式不统一、时间戳不同步、缺失值处理规则混乱,直接导致数字孪生模型训练时出现"数据中毒"——模型学到的不是真实工况,而是数据噪声。
GPT模型的出现改变了这一局面,以西门子2026年推出的Industrial GPT为例,它不是简单的自然语言处理工具,而是专门针对工业数据优化的多模态大模型,该模型能自动识别不同系统的数据格式(如OPC UA、Modbus、Profinet),通过预训练的工业知识图谱理解"压力机主轴温度"与"模具磨损"之间的关联,用生成式能力补全缺失值(比如根据历史趋势预测未来5分钟的温度值),甚至能检测数据中的异常值(如某台设备突然出现的超高温信号可能是传感器故障而非真实工况)。
在青岛某船舶重工的实践中,Industrial GPT将原本需要2周的数据清洗工作缩短至2天,数据可用率从65%提升至92%,更关键的是,它让数字孪生模型能"理解"数据背后的物理意义——当模型检测到某台焊接机器人的电流波动时,不再只是报警,而是能结合历史数据推断"可能是焊丝直径变化导致",并建议检查送丝机构,这种从"数据报警"到"根因分析"的跨越,正是GPT模型带来的质变。
生成式AI降低了数字孪生的建模门槛
传统数字孪生的建模需要机械、电气、自动化、计算机等多学科交叉团队,建模周期长、成本高,某3C电子企业2026年的案例很典型:其手机组装线的数字孪生项目,仅建模就花了8个月,投入300万元,包括聘请外部咨询公司、购买专业软件、培训内部团队等,更头疼的是,当产线升级(如新增一台检测设备)时,原有模型需要重新校准,又得花2-3个月。 2026年绿色消费圈与绿色营销链及气候行动热度持续上升,相关产业迎来新发展
GPT模型推动了"低代码/无代码"建模的普及,以华为2026年发布的Digital Twin GPT为例,它内置了2000+个工业场景的预训练模型(如机械臂运动学模型、传送带动力学模型、热处理工艺模型),用户只需用自然语言描述需求(如"我需要一个模拟手机屏幕贴合过程的数字孪生,包含温度、压力、速度三个参数"),模型就能自动生成初始版本,再通过拖拽式界面调整参数、连接设备。
深圳某智能硬件企业的实践很有说服力:其新产线的数字孪生建模从原来的8个月缩短至2周,成本降至50万元,更惊喜的是,当产线需要调整时,一线工程师(非专业建模人员)自己就能修改模型——比如将检测设备的采样频率从100Hz改为200Hz,只需在界面上输入"将设备3的采样频率提高一倍",模型会自动重新计算数据同步逻辑,这种"人人可建模"的能力,让数字孪生从"专家工具"变成了"生产一线标配"。

GPT模型推动了数字孪生从"静态模拟"到"动态优化"的升级
早期的数字孪生多是"离线模拟":在产线建设前,用数字模型验证布局合理性;在设备维护前,用数字模型预测故障影响,但工业场景是动态变化的——原材料批次不同、环境温度波动、操作人员习惯差异,都会导致实际工况与模型预设的"理想状态"产生偏差,2026年,这种"静态模拟"已无法满足企业需求。
GPT模型赋予了数字孪生"实时学习"能力,以某化工企业的实践为例,其反应釜的数字孪生原本基于固定的工艺参数(温度、压力、搅拌速度),但实际生产中,不同批次的原料纯度差异会导致反应速率变化,2026年,该企业引入了基于GPT的动态优化系统:模型实时采集原料检测数据(如纯度、水分含量),结合历史生产数据,用生成式能力预测"在当前原料条件下,最优的反应温度是多少",然后自动调整加热装置的输出功率。
这种"模型-现实"的闭环反馈,让数字孩生从"模拟工具"变成了"优化引擎",在重庆某汽车工厂的实践中,基于GPT的数字孪生系统将冲压车间的良品率从92%提升至96%——模型实时分析每块钢板的厚度、硬度数据,动态调整压力机的压力参数,确保冲压后的零件尺寸精度始终在公差范围内,更关键的是,这种优化是"自学习"的:随着生产数据的积累,模型的预测精度会越来越高,优化效果也会越来越好。
GPT模型促进了数字孪生的跨企业协同
工业供应链是典型的"网络化生产":一家主机厂需要配套数百家零部件供应商,任何一家的交付延迟或质量波动都会影响整条链的效率,2026年,数字孪生的跨企业协同成为新趋势,但技术壁垒很高——不同企业的数据格式、通信协议、安全标准差异大,如何实现"数据互通、模型共享"是难题。
本月母婴用品与体育赛事及绿色湿地保护热度持续上升,相关产业迎来新发展 
GPT模型提供了"翻译器"功能,以某新能源汽车企业的实践为例,其电池供应商分布在全国10个城市,每家供应商的检测设备、数据格式各不相同,2026年,该企业联合供应商部署了基于GPT的供应链数字孪生平台:各供应商的本地模型(如电池电芯的缺陷检测模型)通过GPT转换为标准格式,上传至云端;主机厂的数字孪生系统(如整车装配线模型)直接调用这些模型,实现"从电芯到整车"的全链条模拟。 2026年边缘计算与绿色低碳热度持续上升,相关产业迎来新机遇
这种协同带来的效率提升显著,在某次新车型试制中,原本需要3个月的供应链协同测试(包括电池与电机的匹配测试、底盘与车身的装配测试),通过数字孪生平台缩短至1个月——各供应商的模型在云端并行运行,主机厂能实时看到任何一家的参数变化对整车性能的影响,提前调整设计方案,更关键的是,这种协同是"安全"的:GPT模型对数据进行脱敏处理,供应商的核心工艺参数(如电池的电解液配方)不会被泄露,只共享"对协同必要"的信息(如电芯的尺寸精度)。
GPT模型推动了数字孪生的"平民化"应用
2026年的工业圈有个现象:数字孪生不再只是大企业的"专利",中小企业也开始广泛应用,这背后是GPT模型带来的成本下降与易用性提升,以某中小型机械加工企业为例,其2025年还觉得数字孪生"太贵、太复杂",但2026年通过购买基于GPT的SaaS服务(如阿里云的工业数字孪生平台),仅花5万元/年就实现了关键设备的数字孪生监控。
这种"平民化"应用的核心是"开箱即用",中小企业无需自建数据中心、购买专业软件、培训建模团队,只需在云端选择适合的模板(如"数控机床数字孪生模板"),上传设备数据,就能快速生成数字孪生模型,更贴心的是,这些模板内置了行业最佳实践——比如数控机床的模板已经预设了"主轴温度-刀具磨损"的关联规则,中小企业直接用就行,无需自己摸索。
在苏州某电子元件企业的实践中,这种"平民化"数字孪生带来了意外收获:原本用于设备监控的模型,被一线员工"玩"出了新花样——他们发现模型能预测设备的"疲劳点"(即连续运行多少小时后效率开始下降),于是主动调整排班计划,将设备维护从"固定周期"改为"动态周期",既减少了停机时间,又延长了设备寿命,这种"自下而上"的创新,正是数字孪生普及的真正价值。
GPT模型与工业知识的深度融合是关键
值得注意的是,GPT模型在工业数字孪生中的成功,并非单纯因为"技术先进",而是