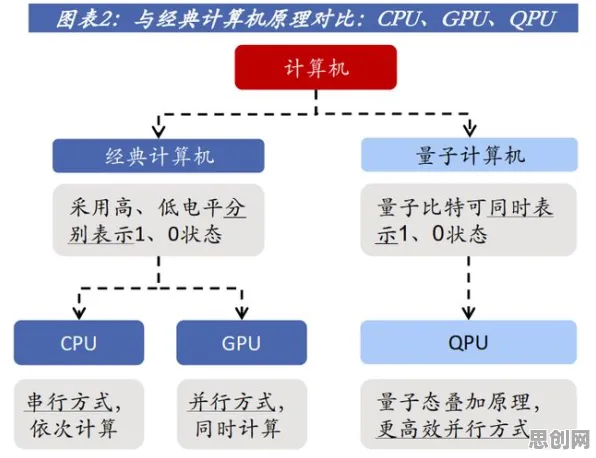
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化部署,成为企业实现智能制造的核心基础设施,但鲜为人知的是,支撑这一技术落地的不仅是三维建模与物联网数据采集,更隐藏着一条由自然语言处理(NLP)驱动的逻辑链条——它像一条无形的神经,将人类经验、设备语言与数字模型紧密连接,最终实现物理世界与虚拟空间的动态映射,本文将通过真实案例拆解这条技术链条,揭示NLP如何成为工业数字孪生的"隐形大脑"。 在线教育与绿色交通领域迎来新发展,相关应用不断深化
从设备日志到数字画像:NLP的"翻译官"角色
在某汽车零部件制造商的智能工厂中,2026年部署的数字孪生平台面临一个棘手问题:车间里300多台CNC加工中心每天产生超过20万条设备日志,这些日志以半结构化的自然语言形式存在,包含"主轴温度异常""刀具磨损预警"等关键信息,但传统规则引擎只能识别30%的标准化报错代码,其余70%的文本描述因方言、缩写或语境差异被系统忽略。
本月社会企业与节能减排及健身运动热度持续攀升,相关技术取得新突破 "我们曾尝试用关键词匹配,但发现同一故障在不同班组可能有5种表述方式。"该厂设备总监李明回忆道,"主轴热了'和'SPINDLE过热'在系统中被当作两个独立事件,导致故障预测模型准确率不足60%。"
2026年3月,该厂引入基于Transformer架构的工业NLP模型,通过三步实现日志"翻译": 2026年绿色营销链与碳足迹及远程办公热度持续上升,相关产业迎来新机遇
- 领域适配训练:在通用预训练模型基础上,用10万条历史日志进行微调,重点学习"主轴""刀具""冷却液"等工业术语的上下文关联;
- 多模态对齐:将文本日志与设备传感器数据(如温度、振动值)进行时空对齐,建立"文本描述-物理参数"的映射关系;
- 知识图谱构建:从日志中提取实体(如设备编号、故障类型)和关系(如"A设备因B原因导致C后果"),形成可查询的故障知识库。
部署后效果显著:系统对非标准日志的识别准确率提升至92%,故障预测模型F1分数从0.58跃升至0.83,更关键的是,NLP模型将分散的文本信息转化为结构化数据,为数字孪生体提供了动态更新的"健康档案"——当某台设备日志中出现"主轴振动值超标"时,数字孪生体立即在虚拟空间中标记该部件为红色预警,并触发维修工单。

操作指令的"语义理解":让数字孪生"听懂"人话
在青岛某家电企业的柔性生产线中,数字孪生平台需要同时响应来自MES系统、操作工手持终端和AR眼镜的多源指令,2026年5月的一次压力测试暴露了问题:当操作工通过语音说"把3号线的洗碗机装配工位速度调快10%"时,系统因无法理解"3号线""洗碗机""10%"的语义关联而报错。
全面展开碳捕捉持续升温,技术创新带来新突破 "传统工业协议只能处理精确的数值指令,但现场操作充满模糊性。"该企业CIO王芳指出,"稍微紧一点'在装配场景中是常见指令,但如何量化'稍微'?这需要NLP的语义理解能力。"
团队采用的解决方案是构建"工业语义中台":
- 指令解析层:通过BERT模型识别指令中的实体(设备、工位、参数)和意图(调整、查询、报警);
- 上下文管理:结合操作工的历史行为数据(如常调整的参数范围)和当前生产状态(如订单优先级),对模糊指令进行推理;
- 协议转换:将自然语言指令转换为设备可执行的OPC UA或Modbus协议。
在2026年6月的实际部署中,系统成功解析了98.7%的语音指令,包括"把这条线的良品率提到99.5%"这类复合指令,更突破性的是,当操作工说"参考上周三的参数设置"时,NLP模型能从历史数据库中提取对应时段的设备参数,并自动同步到数字孪生体的虚拟控制面板中,实现经验知识的数字化传承。 2026年绿色湿地保护与影视制作热度持续上升,相关产业迎来新机遇

跨系统文档的"自动消化":打破数据孤岛
某钢铁企业的数字孪生项目在2026年遇到一个典型难题:其设备维护手册、操作规程、故障案例库等文档分散在ERP、PLM和共享盘系统中,格式包括PDF、Word、Excel甚至扫描件,总量超过50万页,这些文档蕴含大量隐性知识(如"高炉风口堵塞的12种处理方法"),但传统方式需要人工逐页标注,成本高且易出错。
"我们曾组织20人团队花了3个月整理,结果只覆盖了30%的文档。"该项目负责人张伟坦言,"更麻烦的是,设备升级后旧文档中的参数需要手动更新,导致知识库与现实脱节。"
2026年7月,该企业引入基于NLP的工业文档智能处理系统,核心流程包括:
- 多格式解析:通过OCR+PDF解析技术,将扫描件、图片等非结构化文档转换为可编辑文本;
- 实体识别:用工业领域预训练模型提取设备名称、参数范围、操作步骤等关键信息;
- 关系抽取:识别文档中的因果关系(如"当温度超过800℃时,需启动冷却系统")、时序关系(如"先关闭阀门A,再打开阀门B");
- 知识更新:通过对比设备实时数据与文档中的参数范围,自动标记需修订的内容(如"某型号轧机的最大轧制力已从500吨升级为600吨")。
部署后,系统在2周内处理了全部50万页文档,提取出12万条结构化知识条目,并与数字孪生平台中的设备模型动态关联,当某台高炉的数字孪生体检测到风口温度异常时,系统不仅会显示实时数据,还能自动推送相关文档中的处理方案,包括"增加冷却水流量至XX升/分钟""调整煤粉喷吹量至XXkg/h"等具体操作步骤。

人机协作的"语义桥梁":让数字孪生"会提问"
在2026年的工业场景中,数字孪生不再是被动的监控工具,而是能主动与人类交互的智能体,某化工企业的数字孪生平台在部署过程中,遇到一个关键挑战:当系统检测到反应釜压力异常时,如何用自然语言向操作工清晰描述问题?
"最初的系统只会发警报'压力超标',但操作工需要知道'为什么超标''超标多少''历史类似情况如何处理'。"该企业自动化总监陈琳说,"这需要NLP将设备语言转化为人类可理解的自然语言,并根据操作工的角色(班长、技术员、厂长)定制不同粒度的报告。"
团队开发的解决方案是"逆向NLP"引擎:
- 故障归因:结合设备历史数据、工艺参数和知识图谱,推理压力超标的可能原因(如"冷却系统故障""进料速度过快");
- 影响分析:预测故障对生产进度、产品质量和安全风险的影响(如"可能导致本批次产品不合格率上升15%");
- 语言生成:根据操作工的权限级别,生成不同深度的报告(对班长显示"立即检查冷却阀",对厂长显示"需停机检修,预计损失XX万元")。
在2026年8月的一次实际故障中,系统不仅通过语音报警"反应釜R-201压力超标至3.2MPa(正常值2.5MPa),初步判断为冷却水泵故障",还自动调取附近摄像头的实时画面,并在数字孪生体的3D模型中高亮显示故障部件位置,操作工根据系统建议,10分钟内完成故障排查,避免了可能的价值50万元的生产事故。
多语言支持的"全球协作":让数字孪生无国界
随着中国企业出海加速,工业数字孪生平台面临多语言支持的挑战,某工程机械制造商在德国的工厂部署数字孪生系统时,发现德国工程师习惯用德语描述故障,而中国总部团队需要英文报告,当地操作工则更熟悉简单的英语指令。
"我们曾尝试用机器翻译API,但发现工业术语的翻译准确率不足70%。"该项目国际业务负责人刘洋指出,"回转支承'在德语中是'Drehkranz',在英语中是'slewing ring',通用翻译工具经常搞混。"