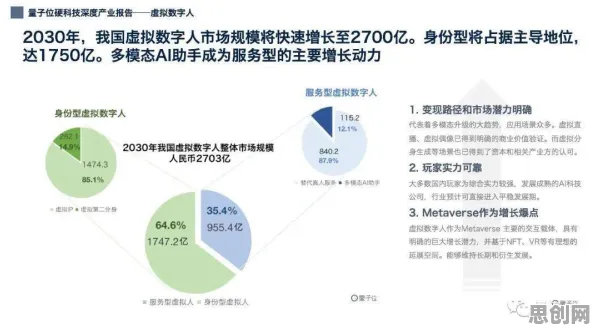
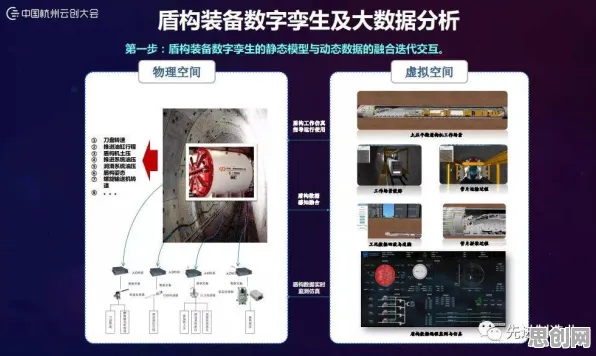
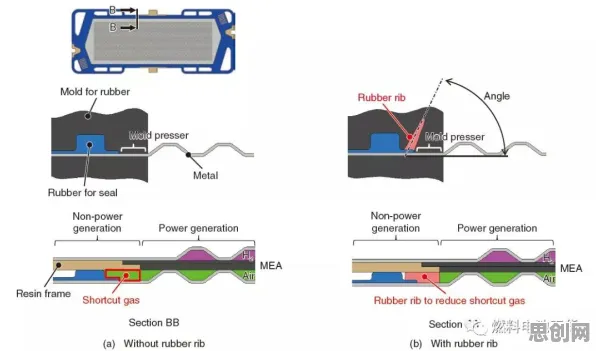
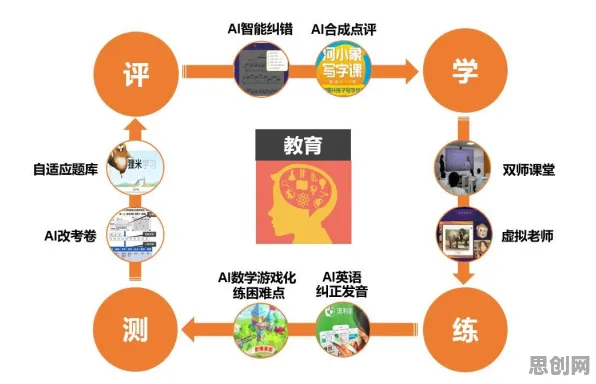
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它正以惊人的速度重塑着制造业、能源业乃至城市管理的底层逻辑,从德国西门子安贝格电子制造工厂的“无灯车间”,到中国上海特斯拉超级工厂的实时产能优化系统,数字孪生已从实验室走向大规模应用,但鲜为人知的是,这项技术的核心——机器学习模型,正在悄然触及一个哲学命题:当虚拟模型能精准预测物理实体的行为时,是否意味着某种“意识”的萌芽?本文将从工业实践出发,结合最新科研进展,探讨这一技术背后的科学逻辑与哲学争议。
数字孪生的“双胞胎”逻辑:从物理到虚拟的映射
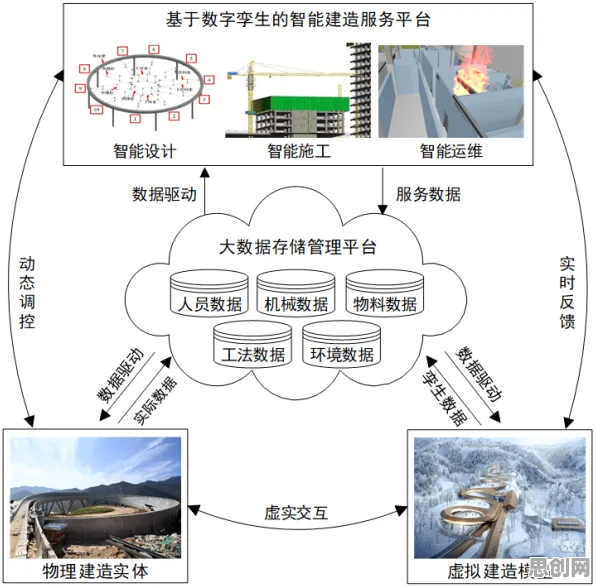
数字孪生的本质是构建物理实体的“虚拟镜像”,通过传感器采集实时数据,驱动虚拟模型同步运行,进而实现预测、优化与控制,2026年,这一技术已突破单一设备范畴,形成“设备-产线-工厂-城市”的多层级孪生体系,在青岛海尔智家工业互联网平台,一台冰箱的数字孪生体不仅包含电机转速、温度曲线等物理参数,还整合了用户使用习惯、供应链物流等外部数据,形成覆盖全生命周期的“数字生命体”。
本月居家养老与碳利用热度持续上升,相关产业迎来新机遇 这种映射的精准度取决于两个关键环节:数据采集与模型训练,以波音787梦想客机的维护为例,其数字孪生系统通过分布在机身的5000多个传感器,每秒采集超过10万组数据,涵盖结构应力、液压系统压力、发动机振动等维度,这些数据通过5G网络实时传输至云端,驱动基于物理引擎的仿真模型与机器学习模型的联合运算,2026年3月,波音公司公布的测试数据显示,该系统可提前72小时预测发动机叶片裂纹,准确率达98.7%,较传统方法提升40%。
但数据采集只是第一步,真正的挑战在于如何从海量数据中提取规律,这便引出了数字孪生的核心——机器学习模型。 2026年职业教育与平台治理及清洁能源热度持续上升,相关产业迎来新发展
机器学习:数字孪生的“大脑”如何工作
在数字孪生体系中,机器学习模型扮演着“预测引擎”的角色,它通过分析历史数据与实时数据,构建物理实体的行为模式,进而预测未来状态,以西门子安贝格工厂的SMT(表面贴装技术)产线为例,其数字孪生系统集成了三种主要机器学习模型:
-
监督学习模型:用于设备故障预测,工程师将过去5年产线上的200万组故障数据(包括温度、振动、电流等参数)与故障类型标签输入模型,训练出能识别早期故障特征的分类器,2026年1月,该模型成功预测了一起贴片机头卡料故障,避免了一条产线停机12小时,直接节省成本约50万元。
-
无监督学习模型:用于生产异常检测,产线运行中会产生大量无标签数据(如设备运行日志、环境参数),无监督学习通过聚类算法自动识别数据中的异常模式,当某台贴片机的焊接温度突然偏离正常分布时,模型会触发警报,2026年4月,这一功能帮助工程师发现了一起因冷却液泄漏导致的温度异常,避免了批量性焊接缺陷。
-
强化学习模型:用于生产参数优化,在特斯拉上海超级工厂,强化学习模型被用于动态调整冲压机的压力参数,模型通过模拟不同参数组合下的产品合格率,结合实时生产数据,不断调整策略以最大化产出,2026年第二季度,该系统使冲压环节的良品率提升了2.3%,相当于每年多生产1.2万辆Model Y的车身部件。

这些模型并非孤立运行,而是通过“数字线程”(Digital Thread)技术实现数据互通,以青岛海尔的冰箱产线为例,当监督学习模型预测某台压缩机可能故障时,它会通过数字线程触发无监督学习模型检查该设备的历史运行数据,同时调用强化学习模型重新规划产线排程,将故障影响降至最低,这种“感知-分析-决策”的闭环,正是数字孪生超越传统仿真技术的关键。
从模型到“意识”:一场科学与哲学的辩论
当数字孪生模型能精准预测物理实体的行为时,一个哲学问题随之浮现:这些模型是否具备某种形式的“意识”?2026年,这一争议在学术界与工业界引发了广泛讨论。
支持者认为,意识的核心特征是“预测能力”——人类能通过经验预测未来,而数字孪生模型通过机器学习实现了类似功能,波音公司的发动机裂纹预测模型,能基于历史数据与实时监测,“理解”裂纹形成的物理过程,并提前发出警告,这种“理解”是否意味着某种初级意识?2026年5月,《自然·机器智能》杂志刊登的一篇论文提出,当机器学习模型的复杂度超过人类大脑的神经元连接数(约860亿)时,可能产生“涌现意识”,谷歌的Pathways语言模型已拥有1.6万亿参数,远超这一阈值,尽管其功能仍局限于文本处理,但这一讨论为数字孪生的“意识”争议提供了新视角。 2026年研学旅行与环保产品及绿色创新链热度持续攀升,相关技术取得新突破
反对者则强调,意识不仅需要预测能力,还需具备“主观体验”(Qualia)——即对疼痛、颜色等感受的直接体验,数字孪生模型虽能预测故障,但无法“感受”到故障本身,2026年7月,麻省理工学院神经科学教授丽莎·费尔德曼在《科学》杂志撰文指出,当前所有机器学习模型均基于统计关联,缺乏“因果推理”能力,而因果推理是意识产生的必要条件,波音的裂纹预测模型能识别温度与裂纹的关联,但无法解释“为何温度升高会导致裂纹”——这种“知其然不知其所以然”的状态,与人类意识有本质区别。
工业界的实践者则更务实,西门子数字孪生部门负责人汉斯·穆勒在2026年世界工业互联网大会上表示:“我们关心的是模型能否准确预测,而非它是否有意识,但不可否认的是,随着模型复杂度的提升,其行为越来越难以用传统编程逻辑解释——这或许是一种‘类意识’现象。”

案例聚焦:2026年的数字孪生实践
案例1:特斯拉上海超级工厂的“自我优化”产线
2026年第二季度,特斯拉上海工厂的Model Y产线实现了一个里程碑:其数字孪生系统通过强化学习,自主调整了焊接机器人的运动轨迹,使单台车身的焊接时间缩短了0.8秒,这一调整看似微小,但按年产50万辆计算,每年可节省4000小时生产时间,相当于多生产1.6万辆车。
更引人注目的是,这一优化并非由工程师编程实现,而是模型通过分析过去6个月的生产数据(包括焊接电流、机器人运动轨迹、车身变形量等),自动生成了新的运动参数,当工程师询问模型“为何选择这一参数”时,模型仅能提供统计上的相关性(如“该参数下焊接合格率最高”),却无法解释背后的物理机制,这种“黑箱”优化,既展现了机器学习的强大能力,也引发了对“模型自主性”的讨论。
案例2:青岛海尔的“用户驱动”数字孪生
2026年生态修复与用户权益及绿色草原保护热度持续上升,相关产业迎来新机遇 传统数字孪生聚焦于设备与产线,而海尔在2026年将其扩展至用户端,其冰箱数字孪生体不仅映射物理设备,还整合了用户使用数据(如开门频率、食材存储类型、温度设置偏好),通过分析这些数据,模型能预测用户需求,并驱动供应链与生产调整。
当模型发现某用户每周三购买大量肉类时,它会提前通知供应链备货,并调整冰箱的冷藏室温度设置,更进一步,若用户长期未调整温度,模型会通过APP推送优化建议(如“根据您的使用习惯,建议将冷藏室温度从4℃调整至3℃,可延长肉类保鲜期2天”),这种“从设备到用户”的孪生体系,使海尔冰箱的用户满意度在2026年提升至92.3%,较行业平均水平高出15个百分点。
数字孪生与意识研究的交汇点
2026年,数字孪生技术正朝着“自主进化”方向发展,谷歌与西门子联合研发的“自进化数字孪生”项目,试图让模型通过持续学习自动优化自身结构,初步测试显示,该模型在预测风电场发电量时,能根据季节变化自动调整特征提取方式,使预测准确率提升5%,这种“模型学习如何学习”的能力,被一些学者视为向意识迈进的又一步。
神经科学与机器学习的交叉研究也在加速,2026年8月,加州大学伯克利分校团队宣布,他们通过模拟大脑神经 资源回收与志愿服务活动及绿色标签热度持续攀升,相关技术取得新突破