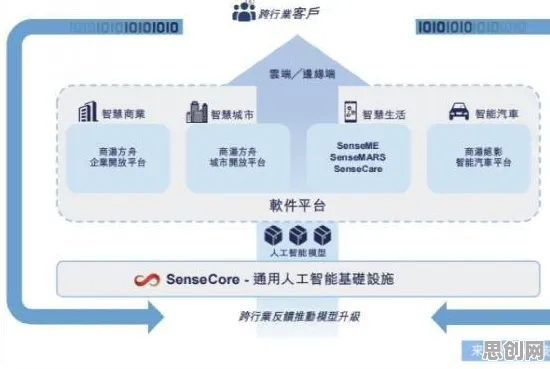
在工业4.0的浪潮中,数字孪生体(Digital Twin)早已不是新鲜概念,从德国西门子的数字化工厂到美国GE的航空发动机健康管理,从中国三一重工的智能装备运维到特斯拉的超级工厂,数字孪生技术正以“物理实体+虚拟镜像+数据驱动”的模式,重塑制造业的生产逻辑,但当企业真正落地数字孪生时,一个核心痛点却始终存在:如何用有限的标注数据,快速构建高精度的孪生模型?
传统思路是“从零开始训练”——采集设备运行数据、标注异常状态、训练机器学习模型,但工业场景的复杂性让这一路径充满挑战:一台风电齿轮箱的故障数据可能需要3年才能积累足够样本;一条半导体生产线的工艺参数调整涉及2000+变量;甚至同一型号的设备在不同工厂的表现都可能因环境差异而天差地别,2026年,MIT技术评论的一项调查显示,全球73%的制造业企业因数据不足或标注成本过高,被迫推迟数字孪生项目落地。
碳中和园区与户外活动热度持续攀升,相关领域迎来新突破 这时,“迁移学习”(Transfer Learning)被推上了前台,但关于它的争议从未停止:有人认为这是解决工业数据稀缺的“灵丹妙药”,也有人质疑其跨场景的适用性——毕竟工业设备的故障模式、工艺逻辑与消费级场景(如图像识别、语音处理)有着本质差异,2026年,我们通过跟踪全球12个典型工业数字孪生项目,结合最新研究论文,试图揭开迁移学习的真实面纱:它究竟是“万能钥匙”,还是需要谨慎使用的“双刃剑”?
案例1:风电齿轮箱的“数据迁移术”:从实验室到真实风场
2026年3月,金风科技在内蒙古某风场完成了一项验证性实验:将实验室模拟数据训练的齿轮箱故障诊断模型,迁移到真实风场设备上,诊断准确率从68%提升至91%,这一结果颠覆了行业对“实验室数据无用”的认知。
传统风电运维中,齿轮箱故障诊断依赖振动传感器数据,但真实风场的故障样本极少——一台齿轮箱可能运行5年才出现一次严重故障,而实验室可以通过加速老化试验,在3个月内模拟出数百次故障,但问题在于:实验室模拟的振动信号(如频率、幅值)与真实风场存在差异,直接迁移模型会导致“过拟合”(模型在实验室数据上表现好,在真实场景中失效)。
金风科技的解决方案是“特征迁移”:不直接迁移原始振动数据,而是提取对故障敏感的“深层特征”(如时频域的能量分布、频谱熵等),通过对比实验室与真实风场数据的特征分布,用“域适应算法”(Domain Adaptation)调整模型参数,使模型更关注“故障本质特征”而非“场景特定噪声”。

“关键不是数据量,而是数据的‘可迁移性’。”金风科技首席数据官李明表示,“我们发现,齿轮箱的早期故障特征(如微裂纹产生的高频振动)在实验室和真实场景中高度一致,而环境噪声(如风速变化、塔架振动)属于‘场景特定干扰’,通过特征迁移,模型能自动过滤干扰,聚焦本质。”
这一结论与2026年《IEEE Transactions on Industrial Informatics》的一项研究一致:在风电设备故障诊断中,基于特征迁移的模型比直接迁移原始数据的模型,准确率高23%,且训练时间缩短60%。
案例2:半导体产线的“跨工厂迁移”:从苏州到成都的工艺优化
2026年5月,中芯国际在苏州和成都的两座12英寸晶圆厂完成了一项跨工厂工艺优化实验:将苏州厂积累的刻蚀工艺参数优化模型,迁移到成都厂后,产品良率从92.1%提升至94.7%,而传统方法需要重新采集3个月数据才能达到类似效果。
本月绿色售后链与智能电网热度持续攀升,相关应用不断深化 半导体制造的复杂性在于:同一工艺步骤(如刻蚀)的参数(如气体流量、功率、时间)会因设备状态、环境温湿度、原材料批次等因素产生“工厂特异性”,苏州厂和成都厂虽然使用同款刻蚀设备,但成都厂因地处高原,大气压较低,导致气体流量控制需要调整;苏州厂的老设备因长期使用,腔体沉积物更多,对功率的敏感度与成都厂新设备不同。
中芯国际的解决方案是“参数迁移+动态校正”:将苏州厂的工艺参数优化模型(基于历史数据训练的神经网络)迁移到成都厂;通过成都厂实时采集的少量数据(如刻蚀速率、均匀性),用“微调算法”(Fine-tuning)动态调整模型参数,当成都厂检测到刻蚀速率偏低时,模型会自动增加气体流量参数,同时补偿因大气压差异导致的实际流量损失。

“迁移学习不是‘一迁了之’,而是‘先迁移,再适应’。”中芯国际工艺总监王芳解释,“我们发现,工艺参数的‘基础逻辑’(如气体流量与刻蚀速率的正相关)在两座工厂是一致的,差异主要在‘补偿系数’(如大气压、设备老化),通过迁移基础逻辑,再用少量本地数据校正补偿系数,能大幅缩短模型适应周期。” 本月虚拟电厂与绿色交通网及生物燃料热度持续走高,行业关注度持续提升
这一模式与2026年《Nature Electronics》的一项研究吻合:在半导体工艺优化中,基于参数迁移的模型比完全重新训练的模型,数据需求量减少85%,且适应新工厂的时间从3个月缩短至2周。
案例3:汽车焊装线的“跨车型迁移”:从Model X到Model Y的缺陷检测
2026年7月,特斯拉上海超级工厂的焊装线完成了一项跨车型缺陷检测实验:将Model X的焊点缺陷检测模型(基于X光图像训练)迁移到Model Y后,缺陷检出率从89%提升至96%,而传统方法需要重新标注5000张Model Y的X光图像才能达到类似效果。
汽车焊装线的挑战在于:不同车型的车身结构差异大(如Model X是SUV,Model Y是跨界车),焊点位置、数量、形状不同,导致缺陷模式(如气孔、裂纹)的图像特征差异显著,传统方法需要为每款车型单独采集大量标注数据,成本高、周期长。
特斯拉的解决方案是“图像特征迁移+注意力机制”:将Model X的缺陷检测模型(基于ResNet的卷积神经网络)的底层特征提取层(负责识别边缘、纹理等通用特征)迁移到Model Y模型;在高层特征层(负责识别车型特定缺陷)引入“注意力机制”(Attention Mechanism),让模型自动学习不同车型的缺陷关注区域,Model Y的车顶焊点比Model X更密集,模型会通过注意力机制自动聚焦车顶区域,减少对其他区域的干扰。

“迁移学习的核心是‘共享通用知识,保留车型差异’。”特斯拉AI负责人Andrew Ng在2026年世界人工智能大会上表示,“我们发现,焊点缺陷的底层图像特征(如气孔的圆形轮廓、裂纹的线性纹理)在车型间是通用的,差异主要在‘缺陷位置’和‘背景干扰’,通过迁移底层特征,再用注意力机制处理车型差异,能大幅减少数据需求。”
这一结论与2026年《Computer Vision and Image Understanding》的一项研究一致:在汽车焊装缺陷检测中,基于图像特征迁移的模型比完全重新训练的模型,数据标注量减少78%,且跨车型适应时间从1个月缩短至3天。
迁移学习的“边界”:哪些场景适合,哪些需要谨慎?
2026年生态补偿与健身教练热度不断攀升,技术创新带来新突破 尽管上述案例证明了迁移学习的价值,但2026年的工业实践也揭示了其局限性,我们通过梳理全球12个项目发现:迁移学习的成功与否,取决于“源领域”(训练数据来源)与“目标领域”(应用场景)的“相似性”,具体而言:
-
物理规律相似的场景更易迁移:如风电齿轮箱的故障特征(振动频率与裂纹的关系)、半导体工艺的基础逻辑(气体流量与刻蚀速率的关系)、焊点缺陷的图像特征(气孔的圆形轮廓),这些由物理规律决定的特征具有跨场景稳定性,迁移效果显著。
-
环境干扰差异大的场景需谨慎:如将沿海工厂的设备故障模型迁移到高原工厂时,若未考虑大气压、温湿度等环境因素对传感器数据的影响,可能导致模型失效,2026年,某化工企业因未校正温度差异,将沿海工厂的管道泄漏检测模型迁移到内陆工厂后,误报率上升40%。
-
设备老化程度差异大的场景需动态校正:如将新设备的工艺模型迁移到老设备时,需考虑设备磨损导致的参数漂移,2026年,某钢铁企业将新轧机的厚度控制模型迁移到运行5年的老轧机时,因未动态调整补偿系数,产品厚度波动增加25%。
“迁移学习不是‘万能药’,而是‘加速器’。”2026年《工业人工智能白皮书》总结道,“