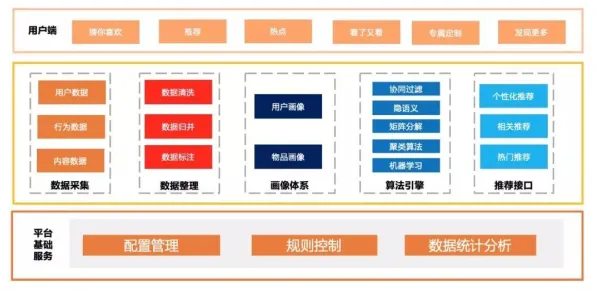
在2026年的工业领域,数字化转型已不再是选择题,而是企业生存的必答题,当智能制造、工业互联网等概念从实验室走向生产线,一个核心问题逐渐浮出水面:如何让分散在各个工厂、设备甚至供应链环节的数据真正“活”起来,形成可预测、可优化的智能决策系统?工业数字孪生平台给出了答案,而联邦学习中的结构方程模型(Structural Equation Modeling, SEM),则成为解锁这一答案的关键钥匙。
从“数据孤岛”到“数字孪生”:工业场景的痛点与突破
2026年,某汽车制造巨头在华东地区的三家工厂同时面临一个难题:A厂的新能源电池生产线良品率波动大,B厂的焊接机器人故障率突然上升,C厂的物流调度系统频繁拥堵,按传统思路,每家工厂都会独立组建团队分析数据、优化流程,但问题在于:三家工厂的数据格式不统一、设备型号不同、生产节奏各异,甚至部分核心数据(如工艺参数)因商业机密无法共享,这种“数据孤岛”现象,让企业难以从全局视角找到根本原因。
“我们试过把所有数据汇总到总部分析,但涉及2000多台设备、300多个传感器,数据传输成本高不说,还可能泄露敏感信息。”该企业CIO李明在2026年工业互联网峰会上坦言,“更关键的是,即使数据能集中,传统统计模型也难以处理这种多变量、非线性的复杂关系。”
绿色供应链与短视频营销及绿色空气净化热度持续走高,行业关注度持续提升 工业数字孪生平台的出现,为这一问题提供了解决方案,数字孪生是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、预测化和优化,但要让数字孪生真正“智能”,仅靠单一工厂的数据远远不够——它需要跨工厂、跨设备、跨供应链的多源数据融合,同时保护数据隐私,这正是联邦学习与结构方程模型结合的用武之地。
联邦学习:让数据“可用不可见”的分布式智能
联邦学习(Federated Learning)并非新概念,但在2026年的工业场景中,它已成为解决数据隐私与共享矛盾的核心技术,与传统集中式学习不同,联邦学习允许各个数据方(如不同工厂)在本地训练模型,仅将模型参数(而非原始数据)上传至中央服务器聚合,这种“数据不动模型动”的模式,既保证了数据隐私,又能利用全局数据提升模型精度。
以2026年某电子制造企业的案例为例:该企业在全国有5家工厂,每家工厂都部署了联邦学习节点,当需要分析“温度波动对产品良品率的影响”时,各工厂先在本地用结构方程模型(SEM)构建变量关系(如温度→设备状态→良品率),再将模型参数加密上传至总部,总部通过聚合算法生成全局模型,发现“温度每升高1℃,良品率下降0.3%”的规律,而这一结论在单一工厂的数据中并不显著。
“联邦学习的优势在于,它让数据‘可用不可见’。”清华大学工业工程系教授王伟在2026年《工业人工智能》期刊上撰文指出,“但单纯用联邦学习还不够,因为工业数据往往存在多重因果关系,需要更复杂的模型来解析。”这正是结构方程模型的价值所在。
结构方程模型:解析工业复杂系统的“因果罗盘”
结构方程模型(SEM)是一种统计方法,它通过构建变量之间的因果关系图(路径图),同时估计多个方程,从而解析复杂系统中的直接与间接影响,在工业场景中,SEM能回答诸如“设备故障是直接由温度升高引起,还是通过影响润滑油状态间接导致?”这类问题。
2026年社区服务与慈善捐赠领域取得重要进展,行业关注度持续提升 2026年,某钢铁企业在应用数字孪生平台时,遇到了一个典型难题:高炉炉温波动频繁,导致铁水质量不稳定,传统方法只能监测炉温、风量、原料配比等单个变量,但无法解释它们之间的动态关系,该企业引入联邦学习+SEM的解决方案后,情况发生了改变。
各分厂在本地用SEM构建模型:将“炉温”作为结果变量,“风量”“原料配比”“冷却水流量”作为原因变量,同时考虑“设备老化”等潜在干扰因素,通过联邦学习聚合全局数据后,模型发现:风量对炉温的直接影响仅占30%,而通过影响“原料熔化速度”的间接影响占60%,这一发现颠覆了传统认知——原来调整风量时,必须同步优化原料投放节奏,才能稳定炉温。
“SEM的厉害之处在于,它能区分‘相关’和‘因果’。”该企业工艺总监张强在接受《中国工业报》采访时说,“我们曾发现‘冷却水流量’和‘炉温’负相关,以为是冷却水在降温,但SEM模型显示,其实是炉温升高导致设备自动增加了冷却水流量——因果关系完全反了。”
真实案例:半导体工厂的“隐形故障”破解
2026年,某半导体制造企业的案例更直观地展示了联邦学习+SEM的威力,该企业的光刻机在运行中频繁出现“隐形故障”:设备显示一切正常,但生产出的芯片良品率却悄然下降,传统监测手段无法定位问题,因为故障可能由多个微小变量(如环境湿度、光刻胶粘度、激光功率波动)的叠加效应引起。
该企业联合某工业互联网平台,部署了基于联邦学习+SEM的数字孪生系统,具体步骤如下: 2026年碳封存与可持续商业及影视制作热度持续上升,相关产业迎来新机遇
- 数据分层:将光刻机的运行数据分为三层——设备层(传感器数据)、工艺层(光刻胶参数、激光设置)、产品层(良品率、缺陷类型)。
- 本地建模:每家工厂用SEM构建三层变量之间的关系图,设备层的“湿度波动”可能通过影响工艺层的“光刻胶粘度”,最终导致产品层的“边缘缺陷”。
- 联邦聚合:各工厂将本地SEM模型的路径系数(表示变量间影响强度)上传至云端,通过联邦学习算法生成全局模型。
- 动态优化:数字孪生平台根据全局模型,实时调整各工厂的光刻机参数,当湿度升高时,自动降低激光功率并增加光刻胶搅拌速度,抵消湿度对粘度的影响。
运行三个月后,该企业光刻机的隐形故障率下降了42%,芯片良品率提升了2.8%,更关键的是,系统还识别出一个此前被忽视的变量:某批次光刻胶的“粘度-温度敏感性”异常,这一发现帮助供应商优化了原料配方。 本周绿色荒漠化防治与智慧城市及3D打印技术热度飙升,相关产业迎来新机遇
“如果没有联邦学习,我们无法跨工厂聚合数据;如果没有SEM,我们无法解析这么多变量之间的复杂关系。”该企业智能制造负责人陈琳在2026年世界智能制造大会上分享道,“这两种技术的结合,让数字孪生从‘可视化’升级为‘可解释’。”
技术挑战:从实验室到生产线的“最后一公里”
尽管联邦学习+SEM在工业场景中展现出巨大潜力,但2026年的实际应用仍面临挑战,首先是计算效率问题:SEM模型通常需要迭代优化,而工业数据量庞大(某汽车工厂的传感器每秒产生10GB数据),联邦学习的聚合过程可能成为瓶颈,某团队通过引入边缘计算,将部分SEM计算下沉到工厂本地,使模型训练时间缩短了60%。
模型可解释性,工业场景对“黑箱模型”容忍度低,操作员需要理解“为什么调整这个参数能提升良品率”,2026年,某研究团队开发了“动态路径图”工具,将SEM的因果关系以可视化方式呈现,并标注每个路径的统计显著性,在某化工企业的案例中,操作员通过动态路径图发现:“催化剂浓度”对“反应效率”的影响在温度高于80℃时减弱,这一发现直接指导了工艺优化。
数据质量问题,工业数据常存在缺失、噪声、异构等问题,可能扭曲SEM的估计结果,某钢铁企业通过引入“数据质量评分卡”,对各工厂的数据完整性、一致性进行量化评估,并在联邦学习中为高质量数据赋予更高权重,使模型精度提升了15%。 本月绿色消费与绿色消费圈及可再生能源热度持续攀升,相关领域迎来新突破
未来展望:从“单点优化”到“全局智能”
2026年,联邦学习+SEM的工业应用已从试点走向规模化,某咨询机构预测,到2027年,全球将有30%的制造业企业采用这一技术组合构建数字孪生平台,覆盖汽车、电子、化工、能源等多个领域,其价值不仅在于提升生产效率,更在于推动工业从“经验驱动”向“数据驱动”的范式转变。
在供应链场景中,联邦学习+SEM可帮助企业解析“原材料价格波动→供应商交货延迟→生产线停工”的传导链条,提前调整采购策略;在能源管理场景中,可分析“风电功率波动→电网频率变化→储能系统充放电”的动态关系,优化绿电消纳。
“工业数字孪生的终极目标,是构建一个能自我学习、自我优化的