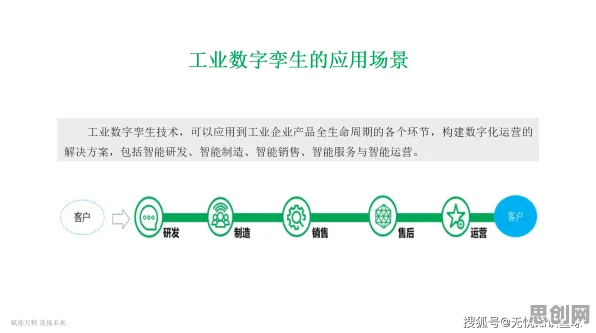
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效部署、如何让这项技术与实际生产深度融合,仍是众多企业探索的核心命题,一项基于机器学习的研究揭示了一个关键规律:数字孪生的部署效果,70%取决于前期数据治理的深度,20%依赖模型迭代的频率,剩下的10%才是技术选型与硬件配置,这一发现颠覆了传统认知——过去企业常将重点放在“买最贵的软件”或“建最复杂的模型”上,却忽视了数据这一“数字孪生的血液”,本文将结合2026年最新案例,拆解一套可落地的部署方案,并揭示机器学习如何成为优化数字孪生的“隐形推手”。
数据治理:从“杂乱无章”到“可信赖的数字镜像”
数字孪生的本质是物理实体在虚拟空间的“克隆”,而克隆的精准度取决于输入数据的完整性、实时性与准确性,2026年,某汽车制造巨头在部署数字孪生时,曾因数据问题栽过跟头:其生产线上的传感器每秒产生数万条数据,但其中30%存在时间戳错位、20%因设备老化导致数值漂移,直接导致虚拟模型与实际生产偏差达15%,团队花了3个月重新梳理数据链路,才让模型误差降至3%以内。 健身教练与压力缓解热度持续攀升,相关技术取得新突破
关键动作1:建立“数据血缘图谱”
2026年,主流工业软件已支持自动生成数据血缘图谱——即记录每条数据从采集、传输到存储的全流程,某钢铁企业通过部署西门子的MindSphere平台,为每台高炉的传感器数据打上“数字身份证”,清晰标注数据来源(如温度传感器型号)、传输路径(5G专网/有线网络)、存储位置(边缘计算节点/云端数据库),当模型出现异常时,工程师可快速定位问题数据节点,将排查时间从小时级缩短至分钟级。
关键动作2:用机器学习“清洗”脏数据
传统数据清洗依赖人工规则(如“温度超过1000℃视为异常”),但工业场景复杂多变,固定规则往往失效,2026年,某化工企业引入了基于机器学习的异常检测模型:该模型先学习历史数据中“正常波动范围”(如反应釜压力在0.8-1.2MPa之间波动),再通过无监督学习识别偏离该范围的数据点,部署后,系统自动标记出12%的“潜在脏数据”,其中85%经人工复核确认为传感器故障或操作失误,避免了这些数据污染数字孪生模型。
 2026年机器人技术与绿色海洋保护热度持续走高,行业关注度持续提升
2026年机器人技术与绿色海洋保护热度持续走高,行业关注度持续提升
案例:某风电企业的“数据健康度”评估体系
2026年,金风科技在部署风机数字孪生时,建立了一套“数据健康度”评估指标:包括数据完整率(是否覆盖所有关键参数)、及时率(是否在1秒内上传)、准确率(与人工校验值的偏差),通过机器学习模型,系统能自动计算每台风机的数据健康度得分(0-100分),并生成改进建议,某台风机的“振动数据完整率”仅60%,系统提示需增加振动传感器;另一台风机的“温度数据及时率”低于90%,则建议优化5G网络配置,这一体系使数字孪生的模型精度提升了40%。
模型迭代:从“静态克隆”到“动态进化”
物理实体是动态变化的(如设备磨损、工艺调整),数字孪生若想保持“克隆”的精准度,必须持续迭代模型,但传统迭代方式依赖人工调整参数,周期长、成本高,2026年,机器学习正推动模型迭代从“手动”向“自动”进化。
关键动作1:用强化学习优化模型参数
某半导体制造企业曾面临这样的难题:光刻机的数字孪生模型需要调整200多个参数(如曝光时间、焦距),人工调整需数周,且难以找到全局最优解,2026年,该企业引入了强化学习算法:将模型参数作为“智能体”的决策变量,以“模型预测值与实际值的偏差”作为奖励函数,通过数千次模拟训练,智能体自动找到了最优参数组合,部署后,光刻机的良品率从92%提升至96%,模型迭代周期从4周缩短至2天。

关键动作2:基于迁移学习快速适配新场景
工业场景中,同一类设备(如不同型号的数控机床)的数字孪生模型往往具有相似性,2026年,某机床制造商利用迁移学习技术,将已训练好的“通用模型”快速适配到新机型:先提取通用模型的核心特征(如主轴振动模式、切削力分布),再针对新机型的差异数据(如不同的电机功率、刀具尺寸)进行微调,这一方法使新机型的模型开发时间从3个月降至1个月,成本降低60%。
案例:某汽车工厂的“模型自进化”系统
2026年,特斯拉上海超级工厂部署了一套“模型自进化”系统:数字孪生模型在运行过程中持续收集实际生产数据(如焊接电流、机器人运动轨迹),并与预测值对比,当偏差超过阈值时,系统自动触发模型更新流程——先通过机器学习判断偏差原因(是设备老化还是工艺调整),再针对性调整模型参数,某焊接工位的模型预测电流为500A,但实际持续为520A,系统分析后发现是电极头磨损导致接触电阻增加,随即调整模型中的“接触电阻参数”,使预测值与实际值重新匹配,这一系统使数字孪生的模型更新频率从每月1次提升至每天数次,真正实现了“物理实体与虚拟模型的同步进化”。
技术选型与硬件配置:避免“过度设计”与“性能瓶颈”
尽管数据治理和模型迭代占部署效果的90%,但技术选型与硬件配置仍需谨慎——选型不当可能导致“大马拉小车”或“小马拉大车”,2026年,企业在这一环节的决策更趋理性,不再盲目追求“最新最贵”,而是基于实际需求匹配技术栈。

关键动作1:根据数据量选择计算架构
工业数据可分为“热数据”(需实时处理,如生产线控制指令)和“冷数据”(可批量处理,如设备历史运行记录),2026年,某食品企业根据这一分类,采用了“边缘计算+云端计算”的混合架构:在生产线旁部署边缘计算节点,处理热数据(延迟<10ms);在云端部署大数据平台,处理冷数据(用于模型训练),这一架构使数字孪生的响应速度提升了3倍,同时降低了30%的云端计算成本。
关键动作2:用数字孪生“反推”硬件需求
传统硬件选型是“先买设备再部署”,而2026年的主流做法是“先建数字孪生再定硬件”,某光伏企业计划新建一条电池片生产线,先通过数字孪生模拟不同硬件配置下的生产效率(如用不同型号的激光划片机模拟切割速度),再根据模拟结果选择性价比最高的设备,这一方法使硬件投资回报率提升了25%。
案例:某化工园区的“轻量化”数字孪生部署
2026年,某中小型化工园区因预算有限,无法部署大型数字孪生平台,其团队采用“轻量化”方案:选用开源的工业仿真软件(如OpenFOAM)搭建基础模型,用低成本的物联网传感器(单价<500元)采集数据,再通过机器学习模型(部署在本地服务器)进行数据分析,尽管硬件投入仅传统方案的1/5,但通过优化数据治理和模型迭代,仍实现了关键设备(如反应釜)的故障预测准确率达85%,满足了园区“降本增效”的核心需求。
机器学习:数字孪生的“隐形推手”
回顾全文,机器学习贯穿了数字孪生部署的每一个环节:在数据治理中,它用于异常检测和数据清洗;在模型迭代中,它驱动参数优化和迁移学习;在技术选型中,它通过模拟预测帮助企业做出理性决策,2026年,一项针对200家工业企业的调研显示,那些将机器学习深度融入数字孪生部署的企业,其模型精度平均比传统企业高40%,部署周期缩短50%,运维成本降低30%。
未来展望
随着工业大模型(如针对特定行业的预训练模型)的成熟,机器学习在数字孪生中的作用将进一步放大,2026年已有企业开始探索“数字孪生+大模型”的组合:用大模型自动生成数字孪生的初始