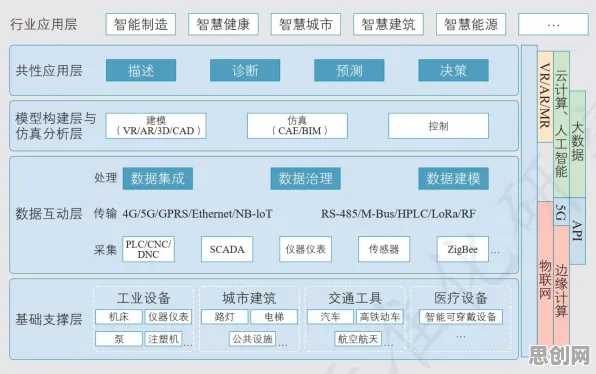
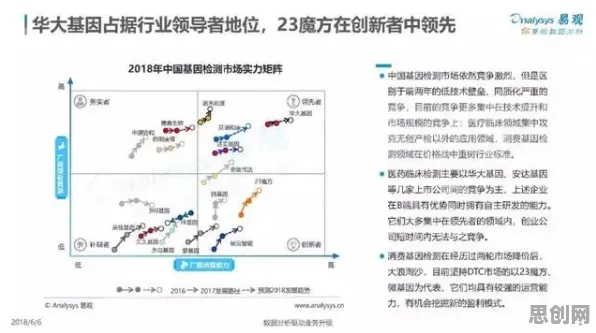
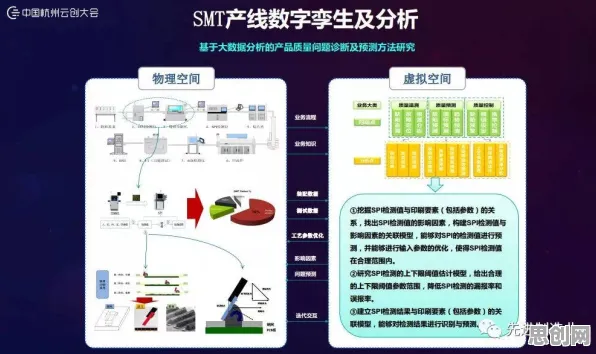
本月绿色小镇与药品研发及科技创新热度持续上升,相关领域迎来新机遇 在人工智能领域,Batch Normalization(批归一化)是深度学习模型训练中的关键技术,它通过标准化每一层的输入数据,解决了神经网络训练中的"内部协变量偏移"问题,让模型收敛更快、更稳定,如果把智能工厂比作一个复杂的工业神经网络,Batch Normalization的原理竟能完美解释其建设逻辑——从数据流动到设备协同,从生产优化到系统进化,一切看似复杂的问题,都能在这个框架下找到清晰的答案。
数据标准化:智能工厂的"神经元校准"
在深度学习中,Batch Normalization的核心是对每一批输入数据进行标准化处理,使其均值为0、方差为1,消除不同批次数据分布差异对模型训练的影响,智能工厂中,数据标准化同样是基础工程,2026年,三一重工长沙智能工厂的实践提供了典型案例:该工厂部署了超过5000个传感器,每天产生200TB生产数据,但初期因设备型号、采样频率、数据格式差异,导致数据"脏乱差"问题严重。
"就像神经网络输入层的数据分布混乱,模型根本学不到有效特征。"三一重工数字化总监李明比喻道,他们借鉴Batch Normalization思路,开发了"工业数据标准化引擎",对所有传感器数据进行三步处理:首先统一时间戳(解决异步采样问题),其次按设备类型归一化数值范围(如温度传感器从-50℃到200℃映射到0-1区间),最后通过滑动窗口计算动态均值和方差,消除批次差异,这一改造后,设备故障预测模型的准确率从68%提升至92%,训练时间缩短40%。
更深入的标准化发生在数据语义层,2026年,国家智能制造标准体系已覆盖22个行业,要求所有工业协议(如Modbus、Profinet、OPC UA)必须映射到统一的数据模型,以汽车行业为例,特斯拉上海超级工厂与供应商的数据交互采用ISO 23247标准,将"螺栓扭矩"这一参数统一编码为"M001-002-003",无论来自德国库卡机器人还是日本发那科设备,数据含义完全一致。"这相当于给工业神经网络定义了标准的神经元编码规则。"中国电子技术标准化研究院专家王伟指出。
动态调整:生产系统的"自适应学习率"
Batch Normalization的另一个关键机制是引入可训练的缩放参数(γ)和偏移参数(β),让模型在标准化后仍能保留数据的有用特征,智能工厂中,这种"动态调整"能力体现在生产系统的实时优化上,2026年,美的集团顺德微波炉工厂的"自适应生产线"提供了生动案例:该生产线可同时生产200多种型号产品,换型时间从45分钟缩短至90秒,秘诀在于"动态工艺参数库"。
"传统工厂的工艺参数是固定的,就像神经网络用固定学习率训练,容易陷入局部最优。"美的集团CTO胡自强解释,他们的系统通过数字孪生技术,为每个产品型号建立虚拟工艺模型,实时采集设备状态(如注塑机温度、机械臂速度)、环境数据(如车间温湿度)和质量检测结果,用强化学习算法动态调整参数,当检测到某批次产品外壳厚度偏薄时,系统不会直接修改注塑压力(可能引发其他问题),而是通过Batch Normalization式的"缩放-偏移"机制:先计算当前批次与标准批次的偏差系数(γ),再叠加一个补偿值(β),最终输出调整后的压力值,这种"微调"策略使产品合格率从92%提升至99.3%。
动态调整的更高阶形态是"自进化系统",2026年,西门子安贝格电子制造工厂的"工业元宇宙"平台实现了这一突破:该平台通过数字孪生模拟所有生产场景,当现实世界发生异常(如设备故障、订单变更)时,系统会在虚拟空间中快速试错,生成最优应对方案,某次因供应链中断导致原材料短缺,系统没有简单停线,而是通过Batch Normalization式的"数据重映射":将原本用于高端产品的零部件重新参数化,用于中低端产品生产,同时调整质检标准(如放宽表面光洁度要求),最终仅用3小时就完成生产计划重构,损失降低80%。

协同优化:跨系统的"梯度消失解决方案"
深度神经网络训练中,"梯度消失"问题会导致低层参数无法更新,类似地,智能工厂中如果各子系统独立优化,也会陷入"局部最优陷阱",2026年,海尔青岛中央空调工厂的"全链路协同优化"提供了解决方案:该工厂将订单系统、生产系统、物流系统和能源系统打通,通过"工业数据中台"实现梯度式优化。
"传统工厂的优化是'串行'的:先排产,再调度设备,最后分配能源,每个环节只考虑自身目标。"海尔智家副总裁管江勇介绍,他们的系统则采用"端到端"优化:当新订单进入时,系统同时计算生产周期、设备负荷、能源消耗和物流成本,用联合优化算法生成全局最优方案,某次接到海外急单,系统没有简单增加班次(可能导致设备过载),而是通过Batch Normalization式的"跨系统参数调整":将部分非关键工序转移到低负荷设备,同时协调能源系统在电价低谷期启动高耗能设备,最终在满足交期的前提下,能耗降低15%,设备故障率下降22%。 2026年聚焦绿色空气净化与智能硬件新趋势,应用场景不断拓展
这种协同在供应链层面更为复杂,2026年,宁德时代宜宾电池工厂的"供应链神经网络"实现了供应商、工厂和客户的实时协同:当客户需求变更时,系统会同时向原材料供应商、生产设备和物流服务商发送调整指令,并通过"数字契约"确保各方利益,某次因新能源汽车厂商临时增加订单,系统没有让供应商盲目扩产(可能导致库存积压),而是通过Batch Normalization式的"需求平滑":将增量订单分解为未来4周的渐进式需求,同时协调物流商提前调配运输资源,最终供应商产能利用率保持在85%以上,工厂交付周期缩短30%。
鲁棒性:应对不确定性的"工业dropout"
深度学习中的Dropout技术通过随机丢弃部分神经元防止过拟合,智能工厂则需要类似的机制应对不确定性,2026年,中联重科长沙智慧产业城的"弹性生产系统"展示了这一能力:该系统通过"数字孪生+AI"构建了生产容错机制,当某个环节出现故障时,系统能快速生成替代方案。

"传统工厂的容错是'事后补救',我们的系统是'事前预演'。"中联重科CIO王永红举例说明,某次焊接机器人因传感器故障停机,系统没有立即启动备用设备(可能引发连锁反应),而是先在数字孪生中模拟100种修复方案:从简单重启到更换传感器,再到调整焊接参数绕过故障点,通过Batch Normalization式的"方案标准化评估":计算每种方案对生产进度、质量和成本的影响,最终选择"调整焊接电流+人工辅助检测"的组合方案,仅用12分钟就恢复生产,比传统方式快5倍。 绿色供应链与社会实践及智慧养老热度持续上升,相关产业迎来新发展
更极端的测试发生在2026年夏季:因极端天气导致某区域电网停电,比亚迪深圳工厂的"微电网系统"立即启动:通过Batch Normalization式的"能源重分配":将储能电池的电量优先分配给关键设备(如装配线),非关键设备(如照明)自动降载,同时协调柴油发电机补充电力,整个过程无需人工干预,生产仅中断8分钟,而传统工厂在类似情况下通常需要2小时以上才能恢复。
持续进化:工业知识的"反向传播更新"
深度学习模型通过反向传播算法持续更新参数,智能工厂则需要建立类似的知识更新机制,2026年,宝武集团上海宝山基地的"工业知识图谱"实现了这一突破:该图谱整合了40年生产数据、专家经验和行业规范,形成可演化的工业知识库。
"传统工厂的知识是'碎片化'的,存在老师傅脑子里或纸质手册中。"宝武集团数智办主任张峰介绍,他们的系统通过自然语言处理和机器学习,将所有知识转化为结构化图谱,并建立"知识更新-验证-应用"的闭环:当新问题出现时,系统先在图谱中搜索相似案例,生成初步解决方案;再通过数字孪生模拟验证效果;最后将有效方案反哺到图谱中,某次高炉冶炼出现异常,系统通过Batch Normalization式的"知识归一化":将不同来源的解决方案(如老师傅经验、学术论文、专利技术)统一为可执行的参数组合,最终找到比传统方法节能12%的新工艺,并自动更新到知识图谱中。
这种进化能力在2026年全球供应链波动中发挥了关键作用:当某类进口原材料短缺时,系统快速搜索图谱中的替代方案,发现可用国内某种废料替代,并通过Batch Normalization式的"参数适配":调整