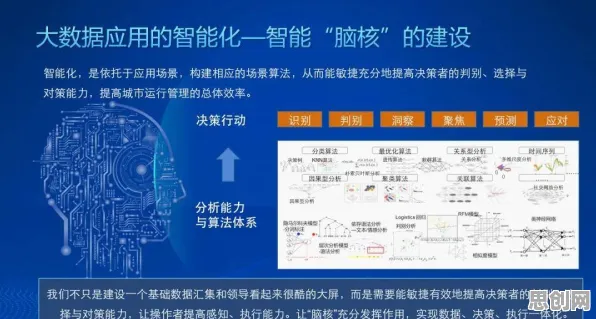
同一律:数字孪生的“身份认证”
同一律是逻辑学的基础,要求“A是A”,即概念必须保持确定性,在数字孪生中,这一原理直接决定了模型的“有效性边界”,以2026年特斯拉上海超级工厂的案例为例:其生产线上的每个机器人都对应一个数字孪生体,但这些孪生体并非简单复制物理设备的参数,而是严格遵循“同一性”原则——孪生体的数据来源、更新频率、模型精度必须与物理设备完全对应,焊接机器人的孪生体不仅记录其当前位置,还同步更新焊缝温度、电流波动等200+个参数,且数据延迟不超过50毫秒,这种“身份认证”机制确保了虚拟模型与物理实体的“时空同步”,否则就会出现“模型显示正常但设备已故障”的逻辑矛盾。
更典型的案例来自航空航天领域,2026年,中国商飞C929客机在试飞阶段,其数字孪生体与物理飞机保持“双胞胎式”同步:当物理飞机在3万英尺高空遭遇气流颠簸时,孪生体立即模拟出机翼应力变化,并同步传输到地面控制中心,这种同步性依赖严格的“同一律”——孪生体的物理模型、传感器数据、算法版本必须与物理飞机完全一致,否则预测结果将失去参考价值。
矛盾律:避免“自我打脸”的模型设计
矛盾律要求“A不能是非A”,即概念不能自相矛盾,在数字孪生中,这一原理体现在模型的一致性校验上,2026年,德国博世集团在建设智能工厂时,曾遇到一个典型矛盾:其数字孪生系统显示某条生产线的“设备利用率”为95%,但同时“故障停机时间”却显示为0,这两个数据明显矛盾——如果设备从未故障,利用率不可能达到95%(因为必然存在计划停机);如果利用率真的95%,故障时间不可能为0,经过排查,发现是传感器数据采集频率不一致导致的:设备状态传感器每秒更新一次,而利用率计算模块每分钟更新一次,导致数据“时间错位”,博世通过统一数据采集频率,解决了这一矛盾。
另一个案例来自能源行业,2026年,国家电网在推广数字孪生变电站时,发现某变电站的孪生模型显示“主变温度正常”,但同时“冷却系统功率”却达到最大值,这显然矛盾——如果温度正常,冷却系统无需全功率运行,进一步检查发现,是温度传感器的量程设置错误(实际温度已超限,但传感器未触发报警),导致模型接收了错误数据,这一案例凸显了矛盾律的重要性:数字孪生的输入数据必须经过严格校验,否则模型会“自我打脸”,输出无效结论。 热度居高不下广告营销热度持续上升,相关产业迎来新机遇
排中律:非黑即白的决策边界
排中律要求“A或非A,二者必居其一”,即概念必须具有明确的边界,在数字孪生中,这一原理常用于故障诊断的“二分法”决策,以2026年三一重工的挖掘机数字孪生系统为例:其液压系统的孪生模型通过监测压力、流量、温度等参数,将设备状态分为“健康”和“故障”两类,中间不设“亚健康”模糊区,这种设计基于排中律——液压系统的故障模式是明确的(如密封件老化导致泄漏),要么未发生,要么已发生,不存在“即将故障”的中间状态(即使有,也通过阈值设定转化为“健康”或“故障”),这种非黑即白的逻辑简化了决策流程:当模型判断为“故障”时,系统立即触发维修工单,无需人工干预判断“是否需要维修”。
绿色配送与低代码开发及绿色土壤修复热度持续上升,相关产业迎来新机遇 
类似的逻辑也应用于汽车制造,2026年,比亚迪在建设数字孪生电池生产线时,对电芯的缺陷检测采用排中律:每个电芯的孪生模型通过AI视觉分析,直接输出“合格”或“不合格”拒绝“可疑”等中间状态,这种设计减少了人为判断的主观性,将缺陷漏检率从行业平均的0.5%降至0.02%。
充足理由律:从数据到结论的“因果链”
充足理由律要求“任何判断必须有充分的依据”,即结论必须由前提推导而出,在数字孪生中,这一原理体现在模型的“可解释性”上,2026年,西门子为某钢铁企业部署的数字孪生高炉系统,曾遇到一个难题:模型预测“炉温将下降”,但操作人员无法理解原因——是原料成分变化?还是风量不足?或是冷却水流量异常?传统黑箱模型无法回答,西门子通过引入“充足理由律”,将模型拆解为可解释的因果链:当炉温预测下降时,系统不仅给出结论,还显示“因铁水硅含量上升0.2%→炉渣碱度降低→炉内传热效率下降→炉温下降”的完整逻辑链,这种设计让操作人员不仅能“知其然”,更能“知其所以然”,从而信任模型结论并采取正确措施。
医疗领域的案例更具代表性,2026年,联影医疗在开发数字孪生CT机时,要求模型对每个扫描参数的调整给出充足理由:当系统建议“将管电压从120kV调整至140kV”时,必须同步说明“因患者体型较大(BMI>30),120kV下图像噪声将超过5%,而140kV可将其控制在3%以内”,这种逻辑链设计使医生能理解模型建议的合理性,避免“盲目跟随AI”的风险。
 本月节能改造与绿色包装及智慧养老热度持续攀升,相关领域迎来新突破
本月节能改造与绿色包装及智慧养老热度持续攀升,相关领域迎来新突破
归纳推理:从“个别”到“一般”的模型训练
2026年3D打印技术与储能材料及能源管理热度持续上升,相关领域迎来新机遇 归纳推理是从具体案例中总结普遍规律的过程,在数字孪生中,这一原理用于模型的初始训练,2026年,中船集团在建设数字孪生船舶时,面临一个挑战:如何让模型准确预测船体在波浪中的应力分布?传统方法依赖理论公式,但实际海况复杂多变,中船采用归纳推理:先收集100艘同类船舶的实航数据(包括波浪高度、航速、船体应力等),再通过机器学习总结出“波浪高度每增加1米,船体应力增加X%”的规律,这种从“个别案例”到“一般规律”的归纳,使模型在未知海况下的预测误差从理论值的15%降至3%。
能源行业的案例更典型,2026年,国家电投在推广数字孪生风电场时,通过归纳推理解决了风机功率预测难题:先收集全国500个风电场的历史数据(包括风速、温度、功率等),再总结出“当风速在8-12m/s且温度低于20℃时,风机功率输出最稳定”的规律,这一规律被编码进数字孪生模型,使功率预测准确率从行业平均的80%提升至92%。
演绎推理:从“一般”到“个别”的决策输出
与归纳推理相反,演绎推理是从普遍规律推导具体结论的过程,在数字孪生中,这一原理用于模型的实时决策,2026年,宝武钢铁的数字孪生高炉系统提供了一个典型案例:其模型基于“铁水硅含量每上升0.1%,炉温需提高5℃”的普遍规律(归纳得出),当实时监测到铁水硅含量从0.3%升至0.5%时,模型立即通过演绎推理得出“需将炉温从1500℃提高至1510℃”的具体决策,并自动调整风量、煤量等参数,这种从“一般规律”到“个别操作”的演绎,使高炉控制从“人工经验驱动”升级为“数据逻辑驱动”。
汽车制造领域的应用更广泛,2026年,一汽-大众在数字孪生焊装车间中,通过演绎推理优化焊接参数:模型基于“焊接电流每增加100A,焊缝熔深增加0.2mm”的规律(归纳得出),当检测到某焊点熔