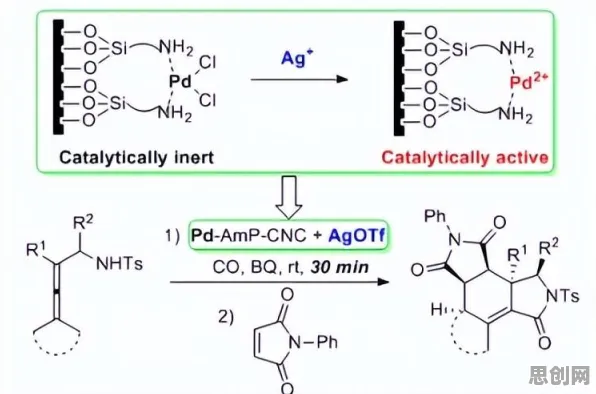
碳捕捉与循环经济及绿色冷能热度持续上升,相关产业迎来新发展 在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化应用,成为企业实现智能制造、降本增效的核心工具,当数字孪生平台与复杂多变的工业场景深度融合时,数据质量参差不齐、模型动态适应性不足、跨系统协同困难等挑战逐渐显现,机器学习作为数字孪生的“智能引擎”,正通过数据驱动的方式破解这些难题,推动工业数字孪生从“静态模拟”向“动态优化”跃迁。
数据治理:从“脏数据”到“黄金数据”的蜕变
工业数字孪生的核心是数据,但现实中的工业数据往往存在噪声大、维度高、标注缺失等问题,以某汽车制造企业的冲压车间为例,其数字孪生平台需集成来自压力机、机械臂、传感器等设备的2000余个数据点,但原始数据中30%以上存在异常值或缺失值,直接导致仿真模型误差超过15%。
挑战:数据质量与标注成本
传统数据清洗依赖人工规则,难以应对动态变化的工业环境,某钢铁企业的高炉数字孪生系统中,传感器因高温环境频繁失效,导致数据中断率高达20%,人工修复成本每月超50万元,工业场景的标注数据获取成本高昂——为训练一个设备故障预测模型,某风电企业需人工标注10万条历史数据,耗时6个月。
机器学习应对方案 美妆护肤与文旅融合热度持续上升,相关领域迎来新机遇
-
自监督学习提升数据质量
2026年,自监督学习技术已在工业数据治理中广泛应用,西门子与慕尼黑工业大学合作开发的“工业数据修复网络”,通过对比学习从正常数据中提取特征,自动识别并修复异常值,在上述汽车冲压车间案例中,该技术将数据修复准确率提升至92%,模型误差降至5%以内。 -
半监督学习降低标注成本
通用电气(GE)在其燃气轮机数字孪生项目中,采用半监督学习框架“Industrial-FixMatch”,该框架仅需标注5%的初始数据,即可通过一致性正则化自动标注剩余数据,实验显示,在相同模型性能下,标注成本降低80%,训练时间缩短60%。 -
联邦学习保护数据隐私
在跨企业协作场景中,联邦学习成为破解数据孤岛的关键,2026年,中国宝武钢铁集团联合多家钢企构建的“钢铁行业联邦学习平台”,允许各企业本地训练模型,仅共享梯度参数而非原始数据,该平台已成功训练出跨企业的高炉能耗预测模型,准确率达94%,且无任何数据泄露风险。
模型动态适应:从“静态仿真”到“实时进化”
工业环境的动态性要求数字孪生模型具备实时更新能力,以半导体制造为例,光刻机的工艺参数需随晶圆批次动态调整,但传统数字孪生模型每24小时才能完成一次参数优化,导致良品率波动达3%。
挑战:模型漂移与计算效率
工业场景中,设备老化、环境变化等因素会导致模型性能随时间下降(即“模型漂移”),某化工企业的反应釜数字孪生系统曾因未及时更新模型,导致预测误差在3个月内从5%攀升至18%,高精度模型(如深度神经网络)的推理延迟常超过工业控制周期(lt;100ms),难以满足实时性要求。
机器学习应对方案
-
在线学习实现模型实时更新
2026年,在线学习技术已成为工业数字孪生的标配,特斯拉在其超级工厂的装配线数字孪生中,采用“流式梯度下降”算法,每秒处理1000个新数据点并动态调整模型参数,该方案使装配线故障预测的响应时间从分钟级缩短至秒级,停机时间减少40%。 -
轻量化模型提升推理速度
华为与某电子制造企业合作开发的“工业模型压缩工具包”,通过知识蒸馏、量化等技术将深度学习模型体积缩小90%,推理速度提升15倍,在3C产品组装线案例中,压缩后的模型可在边缘设备上实现5ms内的缺陷检测,满足实时控制需求。 -
迁移学习加速跨场景适配
三一重工在其挖掘机数字孪生平台中,采用迁移学习技术将通用模型快速适配到不同型号设备,基于100台挖掘机的历史数据训练的基模型,通过少量新设备数据(仅需50个样本)即可完成微调,模型适配周期从3个月缩短至1周。
跨系统协同:从“信息孤岛”到“全局优化”
碳标签与生物识别及社会实践热度持续上升,相关产业迎来新机遇 工业数字孪生需集成MES、ERP、SCADA等多系统数据,但系统间接口标准不统一、数据语义不一致等问题严重制约协同效率,某汽车零部件企业的数字孪生平台曾因系统间数据同步延迟达10分钟,导致生产计划与实际执行偏差超15%。
挑战:异构系统集成与全局优化
传统集成方式依赖定制化接口开发,成本高且扩展性差,某航空制造企业为连接5个异构系统,需开发200余个API接口,维护成本每年超200万元,全局优化需解决多目标冲突问题——某化工企业的数字孪生系统需同时优化能耗、产量和质量,但传统优化算法难以在复杂约束下找到可行解。
机器学习应对方案
-
图神经网络破解异构数据融合
2026年,图神经网络(GNN)成为处理工业异构数据的利器,施耐德电气开发的“工业知识图谱引擎”,通过GNN自动识别设备、工艺、人员等实体间的关系,构建动态知识图谱,在某食品企业的数字孪生项目中,该引擎将多系统数据融合时间从小时级缩短至分钟级,生产异常检测准确率提升30%。 -
强化学习实现全局动态优化
西门子与麻省理工学院合作的“工业强化学习框架”,通过深度Q网络(DQN)在多目标约束下寻找最优解,在某电力企业的数字孪生系统中,该框架动态调整发电机组出力,在满足电网负荷需求的同时,将煤耗降低2.3%,年节约成本超5000万元。 -
数字线程技术打通全生命周期
波音公司在其飞机制造数字孪生中,采用“数字线程”技术实现设计、生产、运维数据的无缝流转,通过机器学习自动映射不同阶段的数据模型,该技术使跨部门协作效率提升60%,故障定位时间从4小时缩短至20分钟。

安全与可信:从“黑箱模型”到“可解释AI”
工业场景对模型安全性和可解释性要求极高,某核电站的数字孪生系统曾因模型输出不可解释,导致操作员对故障预警产生质疑,延误处置时机,工业控制系统(ICS)的漏洞可能导致数字孪生平台被攻击——2026年全球已发生12起针对工业数字孪生的网络攻击事件,造成直接经济损失超2亿美元。 本月绿色物流与绿色物流及机器人技术热度持续上升,相关产业迎来新发展
挑战:模型可解释性与系统安全
传统深度学习模型如“黑箱”,难以满足工业场景的合规性要求,欧盟《工业人工智能法案》要求高风险场景的AI系统需提供决策依据,但现有模型解释技术(如SHAP值)计算复杂度高,难以实时应用,工业数字孪生平台需防御数据投毒、模型窃取等新型攻击。
机器学习应对方案
-
可解释AI技术落地工业场景
2026年,可解释AI(XAI)技术已在工业领域广泛应用,ABB开发的“工业XAI工具包”,通过注意力机制可视化模型关注区域,帮助操作员理解故障预测依据,在某风电场的数字孪生项目中,该工具使操作员对模型预警的信任度从60%提升至90%。 -
对抗训练提升模型鲁棒性
霍尼韦尔在其航空发动机数字孪生中,采用对抗训练技术生成恶意数据样本,增强模型对攻击的防御能力,实验显示,经过对抗训练的模型在面对数据投毒攻击时,预测误差仅增加1.2%,而未训练模型误差激增至18%。 -
区块链保障数据溯源
中国航天科技集团构建的“工业数字孪生区块链平台”,通过智能合约记录数据全生命周期操作,确保数据不可篡改,在某卫星制造项目中,该平台成功追溯到一次模型误差的根源——某供应商提供的传感器数据被篡改