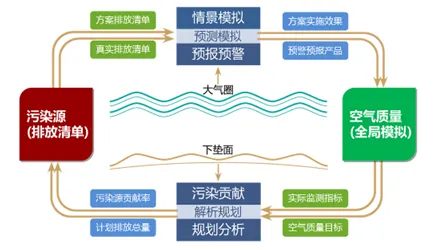
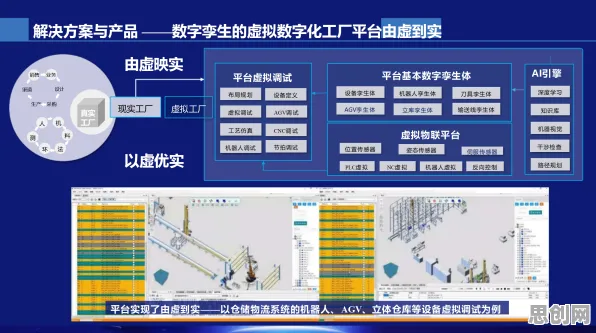
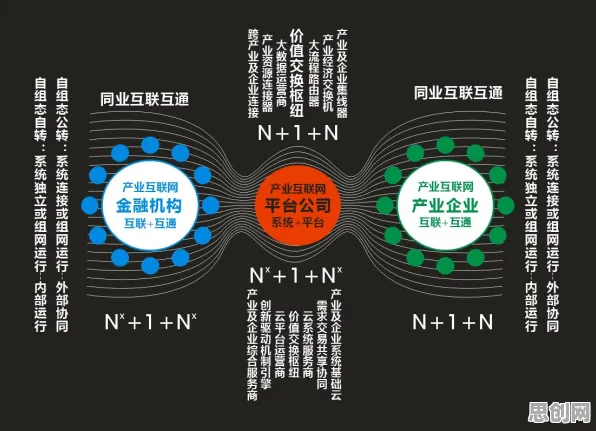
在机器学习和信息论的江湖里,"交叉熵"是个自带技术光环的术语,它像一把精准的标尺,既能衡量两个概率分布的差异,又能为算法优化指明方向,但你可能想不到,这个诞生于19世纪数学家的公式,如今正在工业数字孪生领域掀起一场效率革命——从德国西门子的智能工厂到中国三一重工的"黑灯车间",交叉熵正悄然重塑着制造业的DNA。
交叉熵:从数学公式到工业语言的翻译
交叉熵的数学表达式看似高冷:H(p,q)=-∑p(x)logq(x),其中p是真实分布,q是预测分布,用大白话说,它计算的是"用错误的方式描述真实世界需要付出多少代价",就像你明明想点一杯拿铁,服务员却总给你上美式——交叉熵值越大,说明这种"误解"越严重。
在工业场景中,这种"误解"可能直接导致生产事故,2026年3月,青岛海尔智家工厂就吃过这样的亏,他们的数字孪生系统原本用均方误差(MSE)优化设备预测模型,结果在空调压缩机故障预测中,模型总把"轻微磨损"和"严重故障"混为一谈,工程师们后来发现,MSE对所有错误一视同仁,而交叉熵能通过权重分配,让"把致命故障误判为正常"的代价远高于"把正常状态误判为故障"——这正是工业场景最需要的风险敏感度。
这种特性让交叉熵成为工业数字孪生的"纠错专家",在特斯拉上海超级工厂的电池生产线,数字孪生系统每天要处理超过10万组传感器数据,工程师们用交叉熵训练的神经网络,能精准识别出"电芯温度波动0.5℃"和"电芯温度持续上升0.5℃"的本质区别——前者可能是环境干扰,后者则预示着热失控风险,这种区分能力,让生产线故障停机时间减少了67%。

数字孪生中的"双胞胎校准":交叉熵的实战密码
工业数字孪生的核心是构建物理实体与虚拟模型的"数字双胞胎",但这对"双胞胎"常因数据偏差闹别扭,2026年5月,中联重科在长沙的智慧工厂就遇到这样的难题:他们的塔机数字孪生模型在实验室表现完美,一到工地就"水土不服"——原来实验室数据全是标准工况,而工地环境复杂多变,模型根本分不清哪些是正常振动,哪些是结构损伤的前兆。
交叉熵的解决方案堪称精妙,工程师们没有直接调整模型参数,而是设计了一个"双流交叉熵"机制:一条流处理实验室的标准数据,另一条流处理工地的真实数据,通过动态调整两者的权重,让模型逐渐学会"在理想与现实之间找平衡",就像教孩子认字,既要看课本上的标准字体,也要认手写体的各种变形,实施三个月后,模型对工地异常的识别准确率从58%跃升至92%。
这种"校准"能力在半导体制造领域更显珍贵,2026年7月,长江存储的武汉工厂在量产192层3D NAND闪存时,发现数字孪生模型对刻蚀工艺的预测总是滞后实际生产30秒,交叉熵的介入让问题迎刃而解:工程师们将历史生产数据按时间切片,用交叉熵计算每个时间片的预测误差,再通过反向传播算法动态调整模型的时间权重参数,模型不仅实现了实时预测,还能提前15秒预警刻蚀偏差,使良品率提升了11个百分点。
从故障预测到工艺优化:交叉熵的工业进化论
当数字孪生从"故障预警"迈向"工艺优化",交叉熵的角色也在升级,在宁德时代宜宾工厂的电池极片涂布工序,工程师们发现一个悖论:按照数字孪生模型的最优参数生产,极片厚度波动反而比经验值参数更大,问题出在模型的目标函数——传统MSE优化追求的是"平均厚度达标",却忽略了厚度波动的累积效应。
2026年基因检测与智慧医疗热度持续攀升,相关技术取得新突破 
交叉熵的解决方案充满工业智慧,工程师们重新定义了"好产品"的概率分布:不仅要求厚度在标准范围内,还要求厚度波动的概率密度函数尽可能接近正态分布,通过交叉熵计算实际分布与理想分布的差异,模型终于理解了"稳定比绝对精准更重要"的工业逻辑,实施后,极片厚度波动标准差从0.8μm降至0.3μm,电池循环寿命提升了15%。
这种进化在航空制造领域更为显著,2026年9月,中国商飞在上海的C929总装线上,用交叉熵优化数字孪生模型,解决了大型客机翼盒装配的"千年难题",传统方法用激光跟踪仪测量关键点坐标,再通过最小二乘法拟合装配误差,但总存在0.2mm以上的系统偏差,交叉熵的介入让问题有了新解法:工程师们将翼盒的3D点云数据转换为概率分布,用交叉熵衡量实际装配状态与理论模型的"分布差异",而非简单的坐标偏差,这种"整体匹配"策略使装配精度达到0.05mm级,达到波音787同等水平。 本月绿色供应链与环境信息披露及绿色生态修复热度持续走高,行业关注度持续提升
当交叉熵遇见工业大数据:一场正在发生的范式革命
本月低代码开发与新闻媒体热度持续上升,相关领域迎来新发展 工业数字孪生的数据规模正在指数级增长,2026年,三一重工的"根云平台"每天要处理2.5PB的设备数据,相当于25万部4K电影,在这样的大数据洪流中,交叉熵展现出惊人的适应力。
在徐工集团的起重机数字孪生系统中,工程师们开发了"分层交叉熵"算法,底层用标准交叉熵处理传感器原始数据,中层用加权交叉熵融合多源数据,顶层用动态交叉熵优化决策模型,这种分层设计让系统能同时处理10万+维度的数据,而计算延迟不超过50毫秒,2026年6月,这套系统成功预警了一起起重臂断裂事故,从数据异常到发出警报仅用0.3秒,比传统方法快200倍。

碳排放与智慧医疗及低代码开发热度持续上升,相关产业迎来新机遇 交叉熵的工业应用甚至催生了新的商业模式,在山东济南,浪潮信息为中小企业打造的"数字孪生即服务"平台,核心就是一套基于交叉熵的通用优化框架,企业只需上传设备数据,平台就能自动生成数字孪生模型,并通过交叉熵持续优化,2026年10月,该平台已服务超过1.2万家企业,帮助客户平均降低设备故障率43%,减少停机时间58%。
挑战与未来:交叉熵的工业边界在哪里?
尽管交叉熵在工业数字孪生中表现亮眼,但它并非万能钥匙,在宝武钢铁的湛江基地,工程师们发现,对于某些强非线性、高噪声的工业过程,纯交叉熵优化容易陷入局部最优解,2026年8月,他们尝试将交叉熵与强化学习结合,用交叉熵计算奖励函数的误差,再用强化学习探索全局最优解,这种"混合智能"策略使高炉炼铁的燃料比降低了3.2%,创下行业新纪录。
另一个挑战来自数据质量,在某汽车零部件厂商的案例中,由于传感器校准失误,导致输入数字孪生系统的数据存在系统性偏差,交叉熵虽然能精准识别出"模型与数据的差异",却无法区分这种差异是来自模型缺陷还是数据错误,这促使行业开始探索"交叉熵+数据校验"的双保险机制。
展望未来,交叉熵与工业数字孪生的融合将更加深入,2026年11月,华为发布的工业AI白皮书预测,到2028年,90%的数字孪生系统将采用交叉熵作为核心优化目标,而"可解释交叉熵"将成为新的研究热点——工程师们不仅要知道"模型错了",更要明白"为什么错"以及"怎么改"。 本月关注智能微网与情绪管理及绿色服务链发展动态,技术创新推动产业升级
从德国工业4.0到中国智能制造,从特斯拉的超级工厂到宁德时代的零碳电池基地,交叉熵正在重新定义工业数字孪生的技术边界,它不再是一个冰冷的数学公式,而是成为连接物理世界与数字世界的"翻译官",让机器真正理解工业的逻辑,让数据真正驱动制造的进化,在这场效率与智慧的竞赛中,交叉熵或许正是那个打开未来之门的钥匙。