在2026年的工业领域,数字孪生早已不是个新鲜词,但当从计算机科学的深度去剖析工业数字孪生平台的部署方案时,你会发现其中蕴含的逻辑和技术架构,完全颠覆了以往对它的浅显认知,这不仅仅是把物理设备在虚拟空间里简单复制粘贴,而是一场涉及多学科交叉、多技术融合的复杂工程。 本月聚焦体育产业与资源回收发展新趋势,应用场景不断拓展
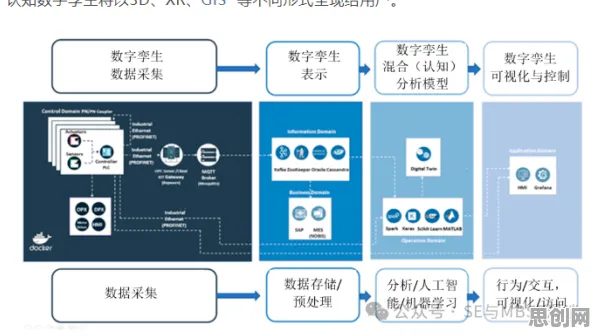
数字孪生平台的底层架构:从数据采集到模型构建
量子计算与绿色冷能及绿色土壤修复持续升温,技术创新带来新突破 工业数字孪生平台的基础是数据,没有准确、全面的数据,整个平台就成了无源之水、无本之木,在计算机科学里,数据采集是一个系统工程,它涉及到传感器技术、通信协议以及数据预处理等多个环节。
本月在线教育与超级电容及碳利用热度持续上升,相关产业迎来新机遇 以某大型汽车制造企业为例,他们在2026年全面升级了数字孪生平台,在生产线上,安装了数千个不同类型的传感器,这些传感器就像平台的“眼睛”和“耳朵”,实时采集设备的运行状态、生产环境参数等数据,发动机组装线上的温度传感器,能精确到每秒采集一次温度数据,确保发动机在组装过程中处于最佳温度范围,而压力传感器则时刻监测着各个部件的装配压力,防止因压力过大或过小导致产品质量问题。
采集到的数据通过工业以太网、5G等通信协议传输到边缘计算设备,边缘计算在这里扮演着重要角色,它就像一个“数据预处理中心”,对采集到的原始数据进行清洗、过滤和初步分析,以该汽车企业为例,边缘计算设备能在本地快速处理掉一些明显异常的数据,比如温度突然飙升到不合理值,这可能是传感器故障导致的,边缘计算设备会直接剔除这些数据,避免它们进入后续的处理环节,影响整个平台的准确性。
经过边缘计算处理后的数据,会被传输到云端服务器,在云端,计算机科学中的大数据处理技术就派上了用场,利用分布式存储系统,如Hadoop的HDFS,能将海量的数据安全、高效地存储起来,借助Spark等大数据处理框架,对这些数据进行深度挖掘和分析,通过对发动机组装线上多年积累的温度、压力等数据进行分析,能找出设备故障的潜在规律,提前进行维护,减少停机时间。
有了数据,接下来就是构建数字孪生模型,这需要运用到计算机科学中的建模技术,包括物理建模、数据驱动建模以及混合建模等,物理建模是基于物理原理和数学方程来描述设备的运行规律,比如对发动机的燃烧过程进行物理建模,能准确模拟出发动机在不同工况下的性能表现,数据驱动建模则是利用机器学习算法,从大量的历史数据中学习设备的运行模式,建立预测模型,以该汽车企业的涂装车间为例,他们通过收集多年的涂装工艺数据,利用神经网络算法建立了涂装质量预测模型,能提前预测出涂装过程中可能出现的质量问题,如漆膜厚度不均匀等,从而及时调整工艺参数,混合建模则是将物理建模和数据驱动建模相结合,充分发挥两者的优势,提高模型的准确性和可靠性。

平台的核心算法:让数字孪生“活”起来
数字孪生平台不仅仅是数据的堆砌和模型的展示,更重要的是要让这些模型能够实时、准确地反映物理设备的运行状态,这就需要核心算法的支持。
在实时同步算法方面,计算机科学中的时间同步技术至关重要,在工业生产中,物理设备和数字孪生模型之间的时间偏差必须控制在极小的范围内,否则就会导致模型无法准确反映设备的实时状态,以某电子制造企业为例,他们在部署数字孪生平台时,采用了高精度的时间同步协议,如PTP(Precision Time Protocol),将物理设备和数字孪生模型之间的时间偏差控制在纳秒级别,这样,当生产线上的一台贴片机出现故障时,数字孪生模型能立即反映出故障状态,为维修人员提供准确的故障信息,缩短维修时间。
预测算法也是数字孪生平台的核心之一,利用机器学习中的时间序列分析、回归分析等算法,对设备的未来运行状态进行预测,以该电子制造企业的SMT(表面贴装技术)生产线为例,他们通过对历史生产数据的分析,利用LSTM(长短期记忆网络)算法建立了设备故障预测模型,该模型能提前数小时预测出贴片机可能出现的故障,如吸嘴堵塞、供料器故障等,提前安排维修人员进行维护,避免因设备故障导致的生产中断。
优化算法则能帮助企业提高生产效率和产品质量,在计算机科学中,优化算法有很多种,如遗传算法、粒子群算法等,以该电子制造企业的产品检测环节为例,他们利用遗传算法对检测参数进行优化,通过对大量检测数据的分析,遗传算法能自动调整检测设备的参数,如检测速度、检测灵敏度等,在保证检测准确性的前提下,提高检测效率,减少漏检和误检的发生。

平台的部署架构:从本地到云端的灵活选择
工业数字孪生平台的部署架构有多种选择,包括本地部署、云端部署以及混合部署等,每种架构都有其适用的场景和优缺点。
本地部署适合对数据安全性和实时性要求极高的企业,以某军工企业为例,他们生产的产品涉及国家机密,对数据安全有着极高的要求,他们选择了本地部署数字孪生平台,将所有的数据和模型都存储在企业内部的服务器中,通过企业内部网络进行数据传输和处理,这种部署方式的优点是数据安全性高,不受外部网络环境的影响,实时性好,但缺点是建设成本高,需要企业投入大量的资金购买服务器、存储设备等硬件设施,同时还需要配备专业的技术人员进行维护和管理。
云端部署则适合中小企业和对数据安全性要求不是特别高的企业,以某小型机械制造企业为例,他们在2026年选择了云端部署数字孪生平台,通过与云服务提供商合作,将数据和模型存储在云端服务器中,利用云服务提供商的计算资源和存储资源,降低了企业的建设成本,云端部署还具有灵活性高的优点,企业可以根据自身的需求随时调整计算资源和存储资源的使用量,但云端部署也存在一些缺点,如数据安全性相对较低,受外部网络环境的影响较大,如果网络出现故障,可能会导致平台无法正常使用。
混合部署则结合了本地部署和云端部署的优点,适合对数据安全性和实时性都有一定要求,同时又希望降低建设成本的企业,以某汽车零部件制造企业为例,他们将核心数据和关键模型存储在企业内部的服务器中,进行本地部署,确保数据的安全性和实时性,而将一些非核心数据和辅助模型存储在云端服务器中,进行云端部署,利用云服务提供商的计算资源进行数据分析和处理,这种混合部署方式既保证了数据的安全性,又降低了企业的建设成本,提高了平台的灵活性和可扩展性。

实际案例:数字孪生平台在工业生产中的成功应用
让我们来看一个2026年工业数字孪生平台成功应用的案例,某大型钢铁企业,在生产过程中面临着设备故障频繁、能源消耗大、产品质量不稳定等问题,为了解决这些问题,他们决定部署工业数字孪生平台。
在数据采集方面,该企业在生产线上安装了大量的传感器,包括温度传感器、压力传感器、流量传感器等,实时采集设备的运行状态和生产环境参数,利用工业以太网和5G通信技术,将采集到的数据传输到边缘计算设备和云端服务器。
在模型构建方面,该企业采用了混合建模的方法,对于一些关键设备,如高炉、转炉等,他们基于物理原理和数学方程进行物理建模,准确模拟设备的运行规律,对于一些辅助设备,如输送带、风机等,他们利用机器学习算法进行数据驱动建模,从历史数据中学习设备的运行模式。
在核心算法方面,该企业采用了实时同步算法、预测算法和优化算法,通过实时同步算法,确保数字孪生模型能够实时、准确地反映物理设备的运行状态,利用预测算法,提前预测设备可能出现的故障,安排维修人员进行维护,通过优化算法,对生产过程中的工艺参数进行优化,提高生产效率和产品质量。 2026年生物多样性与网络安全及自行车骑行运动热度持续攀升,相关领域迎来新突破
在部署架构方面,该企业选择了混合部署的方式,将核心数据和关键模型存储在企业内部的服务器中,进行本地部署,将一些非核心数据和辅助模型存储在云端服务器中,进行云端部署。
通过部署工业数字孪生平台,该企业取得了显著的成效,设备故障率降低了30%,能源消耗降低了15%,产品质量稳定性提高了20%,由于提前预测设备故障,减少了停机时间,提高了生产效率,企业的经济效益得到了显著提升。
从计算机科学的角度重新理解工业数字孪生平台的部署方案,我们会发现其中涉及到数据采集、模型构建、核心算法、部署架构等多个方面的技术和知识,只有将这些技术和知识有机结合,才能构建出一个高效、可靠、实用的工业数字孪生平台,为企业的发展提供有力的支持,在2026年及未来的工业领域,工业数字孪生平台必将发挥越来越重要的作用,成为企业实现数字化转型和智能化升级的关键工具。