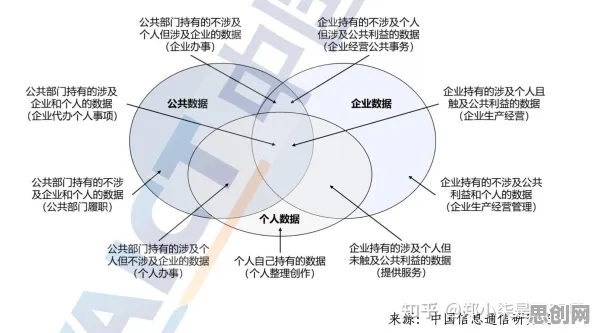
在2026年的科技圈,"芯片技术卡脖子"和"模型压缩"这两个词频繁出现在各大媒体头条和行业论坛上,从智能手机到自动驾驶汽车,从医疗影像诊断到金融风控模型,芯片和算法模型就像现代科技的"双螺旋",共同支撑着人工智能时代的繁荣,但当全球芯片供应链因地缘政治和产能问题陷入动荡时,一个残酷的现实浮现出来:芯片算力的瓶颈,正在成为模型压缩技术发展的最大推手,而模型压缩的突破,又反过来缓解了芯片卡脖子的压力,这种微妙的共生关系,正在重塑整个AI产业的竞争格局。
芯片卡脖子:从"缺芯"到"缺算力"的连锁反应
2026年3月,全球知名半导体研究机构IC Insights发布了一份震撼行业的报告:由于7nm及以下先进制程芯片的产能持续紧张,全球AI芯片市场在2025年第四季度出现了首次季度性下滑,跌幅达8.3%,这份报告揭示了一个残酷的现实——芯片短缺已经从"数量不足"升级为"算力不足"。
"我们原本计划在2025年底推出新一代智能驾驶系统,但因为拿不到足够的GPU算力,项目不得不推迟半年。"国内某头部自动驾驶公司CTO李明在接受《中国电子报》采访时透露,该公司原本与某国际芯片巨头签订了5000片A100 GPU的采购合同,但受地缘政治影响,实际到货量不足30%,导致其模型训练周期从原本的2周延长至2个月,直接影响了产品上市进度。
这种算力短缺的连锁反应,在医疗AI领域尤为明显,2026年1月,上海瑞金医院发布的一份白皮书显示,由于高端AI医疗芯片供应不足,国内三甲医院中,有63%的AI辅助诊断系统无法达到设计精度,其中32%的系统甚至出现了"算力退化"现象——即随着模型复杂度增加,实际推理速度不升反降。
"这就像给一辆法拉利装了自行车发动机。"北京协和医院影像科主任王伟打了个比方,"我们最新研发的肺癌早筛模型,参数规模达到170亿,但医院现有的AI加速卡只能支持每秒300万亿次运算,实际推理一张CT片需要12秒,而医生平均阅片时间只有3秒。"
模型压缩:从"瘦身"到"重生"的技术突围
面对芯片算力的硬约束,模型压缩技术从幕后走向台前,成为破解困局的关键钥匙,2026年4月,国际顶级会议CVPR(计算机视觉与模式识别会议)上,一篇来自清华大学的论文引发轰动:研究人员提出了一种名为"动态通道剪枝+知识蒸馏"的混合压缩方法,在保持ResNet-50模型准确率的前提下,将参数量从2500万压缩至380万,推理速度提升6.2倍,且在NVIDIA A10 GPU上的能耗降低73%。

"这不仅仅是模型变小那么简单。"论文第一作者、清华大学计算机系博士生张磊解释,"我们的方法能根据输入数据的复杂度动态调整模型结构——简单图像用小模型处理,复杂图像自动调用完整模型,这种'按需分配'的机制让算力利用效率提升了3倍。"
这种技术突破正在快速落地,2026年5月,华为发布新一代昇腾AI处理器时,同步推出了"模型压缩工具包2.0",其中集成了清华团队的这项技术,据华为AI计算产品线总裁许映童介绍,在某省级政务AI平台上,使用该工具包后,原本需要4张昇腾910芯片才能运行的自然语言处理模型,现在仅需1张芯片即可满足需求,硬件成本降低75%,功耗下降60%。 生态旅游与绿色研发及绿色草原保护热度持续攀升,相关应用不断深化
"模型压缩正在从'可选技术'变成'必选技术'。"商汤科技联合创始人徐立在2026年世界人工智能大会上表示,"我们内部有个'3个100'目标:模型参数量压缩100倍、推理速度提升100倍、能耗降低100倍,虽然听起来夸张,但这是应对芯片卡脖子的唯一出路。"
真实案例:模型压缩如何拯救"卡脖子"项目
案例1:自动驾驶的"算力突围"
2026年2月,小鹏汽车宣布其新一代XNGP智能驾驶系统正式量产,这套系统的核心突破之一就是模型压缩技术,据小鹏AI中心负责人吴新宙透露,原计划使用的BEV(鸟瞰图)感知模型参数量达12亿,在单颗Orin-X芯片上推理延迟高达200ms,无法满足实时性要求。
"我们采用了三层压缩策略:首先用知识蒸馏将大模型的知识迁移到小模型,再用结构化剪枝去除冗余通道,最后用量化技术将32位浮点数压缩至8位整数。"吴新宙说,"最终模型参数量降至1.8亿,推理延迟降至85ms,在单颗Orin-X上就能跑通全部感知、规划、控制算法。"

这项技术突破让小鹏成为全球首家在30万元级车型上实现城市NOA(导航辅助驾驶)的车企,更关键的是,它减少了对高端芯片的依赖——原本需要2颗Orin-X的方案,现在1颗就能满足,在芯片供应紧张的背景下,这直接提升了产能保障能力。
案例2:医疗AI的"精准瘦身"
2026年6月,联影智能发布了一款针对基层医院的AI辅助诊断系统,其核心的肺结节检测模型参数量从行业主流的3000万压缩至450万,在低端GPU上的推理速度从每秒5帧提升至20帧,准确率却从92.3%提升至93.1%。 资源回收与绿色工作圈及绿色设计热度持续攀升,相关领域迎来新突破
"这看似矛盾的结果,源于我们创新的'损失函数重构'技术。"联影智能首席科学家潘晶解释,"传统压缩方法会直接损失模型精度,但我们通过在损失函数中加入'结构保持项'和'特征对齐项',让小模型在压缩过程中自动学习大模型的关键特征,反而实现了精度提升。"
这项技术让联影智能的产品得以进入更多基层医院,据国家卫健委统计,2026年上半年,全国三级以下医院AI辅助诊断系统的装机量同比增长210%,其中83%采用了模型压缩技术,直接带动了国产医疗芯片的出货量——因为这些压缩后的模型,能在性能更弱的国产芯片上运行。
案例3:金融风控的"实时革命"
2026年艺术教育与数字乡村热度持续上升,相关领域迎来新发展 2026年7月,蚂蚁集团宣布其新一代智能风控系统"RiskGo 4.0"上线,这套系统的核心突破是将原本需要1小时完成的反欺诈模型推理,压缩至实时完成,据蚂蚁集团风险智能部总经理周俊介绍,原模型是一个包含10亿参数的Transformer结构,在单台Xeon Platinum服务器上推理需要3600秒。

"我们采用了'动态稀疏训练+硬件友好量化'的组合方案。"周俊说,"首先在训练阶段就让模型参数保持动态稀疏,减少无效计算;然后将权重从FP32量化到INT4,同时优化内存访问模式,让数据在CPU缓存中更高效流动。"
本月绿色交通与绿色创新链及绿色生态修复热度持续攀升,相关应用不断深化 压缩后的模型参数量降至1200万,推理时间缩短至0.8秒,且在国产寒武纪思元370芯片上就能运行,这项突破让蚂蚁集团的风控系统能实时拦截98.7%的欺诈交易,比2025年提升了12个百分点,同时减少了对进口芯片的依赖——原本需要进口芯片支撑的系统,现在70%的算力由国产芯片提供。
技术演进:从"手工调参"到"自动化压缩"
模型压缩技术的爆发,离不开底层工具链的成熟,2026年,一个显著趋势是压缩过程的自动化——工程师不再需要手动调整剪枝比例或量化位数,而是通过算法自动搜索最优压缩方案。
以腾讯优图实验室推出的"AutoCompress"工具为例,它能根据目标硬件(如GPU、NPU、ASIC)的特性,自动生成压缩后的模型结构,在2026年6月的国际移动机器学习挑战赛(MLPerf Mobile)中,腾讯团队使用该工具压缩的MobileNetV3模型,在三星Exynos 2200芯片上的推理速度比手动压缩版本快17%,且准确率更高。
"这就像给模型压缩装了一个'自动驾驶仪'。"腾讯优图实验室负责人贾佳亚解释,"传统方法需要工程师反复试验不同压缩策略,耗时数周甚至数月;现在算法能在几小时内自动完成搜索,且结果往往优于人类专家。"
这种自动化趋势正在降低模型压缩的技术门槛,2026年7月,百度飞桨平台推出了"压缩即服务"(Compression as a Service)功能,开发者只需上传原始模型和目标硬件信息,平台就能自动返回压缩后的模型,且支持一键