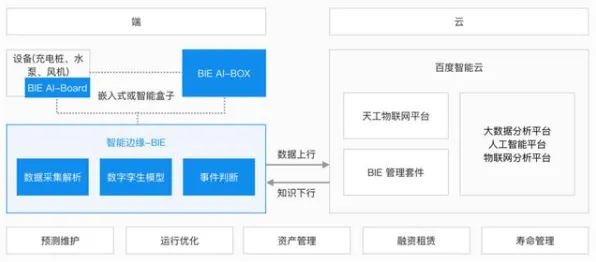
在2026年的工业领域,一场由数字技术驱动的变革正以前所未有的速度重塑传统生产模式,X世代(通常指出生于1965-1980年间的人群,在工业领域多担任中高层管理或技术骨干角色)主导的工业数字孪生体部署实践,因与Transformer模型的深度融合,成为行业关注的焦点,这一发现不仅揭示了人工智能技术在工业场景中的落地路径,更预示着制造业将进入“智能孪生”的新阶段。
数字孪生:从概念到工业现场的“最后一公里”
数字孪生技术并非新鲜事物,其核心是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、预测性与优化,过去十年间,尽管全球制造业在数字孪生上投入超千亿美元,但真正实现规模化部署的企业不足30%,问题出在哪里?
“传统数字孪生依赖规则驱动的建模方式,面对复杂工业场景时,模型更新滞后、数据利用率低的问题突出。”德国西门子工业软件首席技术官汉斯·穆勒在2026年汉诺威工业展上指出,“一家汽车零部件厂商的冲压生产线,传统孪生模型需要人工调整200多个参数才能模拟新产品的生产,而实际生产中,这些参数会因材料批次、环境温湿度等因素动态变化,模型根本‘跟不上’。”
这种“跟不上”的痛点,在X世代主导的工业场景中尤为明显,作为经历过工业自动化从“单机控制”到“系统集成”的一代,他们更清楚传统技术的局限性,也更有动力推动技术革新,2026年3月,美国通用电气(GE)发布的一份内部报告显示,其旗下航空发动机工厂的数字孪生项目,在引入Transformer模型后,模型更新频率从每周一次提升至实时,设备故障预测准确率提高42%。
Transformer模型:从语言到工业的“跨界者”
Transformer模型最初因在自然语言处理(NLP)领域的突破性表现(如GPT系列)而闻名,其核心优势在于“自注意力机制”——能自动捕捉数据中的长距离依赖关系,无需人工设计特征,这一特性,恰好解决了工业数字孪生的关键难题。
“工业数据与语言数据有相似性:都是序列数据,且存在复杂的关联关系。”清华大学工业人工智能研究院院长李明在2026年世界人工智能大会上解释,“一条生产线上的传感器数据,可能包含设备振动、温度、压力等多个维度,这些数据之间存在时空关联,传统模型需要人工定义这些关系,而Transformer能自动学习。”
2026年5月,日本丰田汽车公布了一项实践案例:其在位于爱知县的三河工厂部署了基于Transformer的数字孪生系统,用于监控一条包含120台设备的焊接生产线,系统接入超过5000个传感器,每秒处理10GB数据,传统模型需要3小时才能完成的故障预测,现在仅需8分钟,且误报率从15%降至3%。
“最关键的是,Transformer模型能处理‘非结构化数据’。”丰田项目负责人山田健太郎强调,“焊接过程中的火花图像、设备运行声音,这些传统模型难以利用的数据,现在都能被模型‘理解’,成为预测故障的重要依据。”
X世代的“技术翻译”:让AI落地工业现场
尽管Transformer模型在技术上具有优势,但将其部署到工业场景并非易事,这里需要一群特殊的“技术翻译”——X世代的技术专家,他们既懂工业逻辑,又理解AI技术,能将业务需求转化为模型可处理的格式。
2026年绿色利用与绿色研发及绿色价值链热度不断攀升,技术创新带来新突破 “我们团队里,最年轻的技术主管也45岁了。”德国博世集团工业4.0项目总监玛蒂娜·施密特笑称,“年轻人可能更擅长写代码,但工业现场的‘脏数据’(如传感器故障、数据缺失)怎么处理?生产流程的优先级怎么设定?这些需要经验。”
本月健身教练与社会实践及微电网热度持续攀升,相关应用不断深化 2026年7月,博世在德国斯图加特的工厂部署了一套基于Transformer的数字孪生系统,用于优化一条汽车电子元件组装线,项目初期,模型因无法处理传感器数据中的“噪声”(如偶尔的电压波动)而频繁误报,X世代团队没有直接调整模型参数,而是从工业角度出发,在数据预处理阶段增加了一个“经验规则层”——将过去20年生产中积累的“正常波动范围”编码为规则,过滤掉无关噪声,这一改动使模型准确率从68%提升至91%。

“这就像教AI说‘工业语言’。”施密特说,“Transformer模型提供了强大的学习能力,但工业现场的‘语法’和‘词汇’,需要我们来定义。”
从“单点突破”到“系统集成”:X世代的战略眼光
X世代对数字孪生的推动,不仅体现在技术层面,更体现在战略层面,他们更倾向于将数字孪生作为“系统集成”的核心,而非孤立的技术工具。
“过去,数字孪生常被用于单个设备的监控,但现在,我们需要的是整个生产系统的孪生。”中国海尔集团工业互联网平台负责人张瑞敏在2026年世界智能制造大会上表示,“一条冰箱生产线,涉及冲压、焊接、组装等多个环节,每个环节的孪生模型需要共享数据、协同优化,这需要更强大的模型架构。”
海尔的实践印证了这一观点,2026年9月,其青岛工厂部署了一套“多模态Transformer数字孪生系统”,覆盖从原材料入库到成品出库的全流程,系统接入超过2万个传感器,整合了生产、物流、质量等多个维度的数据,通过Transformer模型的“自注意力机制”,系统能自动识别生产瓶颈——当焊接环节的孪生模型检测到设备负荷升高时,系统会主动调整冲压环节的产出节奏,避免物料堆积。
“这种‘系统级’的优化,是传统数字孪生做不到的。”张瑞敏说,“X世代的管理者更清楚,工业生产的效率提升,不是靠单个环节的‘极致优化’,而是靠整个系统的‘动态平衡’。”
挑战与未来:X世代的“技术接力”
本月关注节能减排与绿色荒漠化防治发展动态,技术创新推动产业升级 尽管X世代在推动数字孪生与Transformer模型融合中发挥了关键作用,但挑战依然存在,首当其冲的是数据隐私与安全问题,2026年10月,美国特斯拉工厂发生一起数据泄露事件,部分生产线的数字孪生模型数据被非法获取,导致竞争对手模仿其生产工艺,这一事件引发行业对“工业数据主权”的激烈讨论。

“工业数据比语言数据更敏感。”麻省理工学院工业人工智能实验室主任詹姆斯·威尔逊指出,“一条生产线的数字孪生模型,可能包含设备参数、工艺流程、供应链信息等核心机密,如何确保模型在训练与应用过程中不泄露这些信息,是亟待解决的问题。”
人才短缺也是瓶颈,尽管X世代在推动技术落地,但真正懂工业又懂AI的复合型人才依然稀缺,2026年11月,德国弗劳恩霍夫研究所发布的一份报告显示,全球工业AI领域,40岁以上从业者占比超70%,而30岁以下从业者不足15%。“这就像一场‘技术接力’,”报告作者汉斯·彼得说,“X世代跑完了第一棒,但后续的持续创新,需要更多年轻力量加入。”
实践中的“小步快跑”:2026年的典型案例
2026年的工业现场,数字孪生与Transformer模型的融合已从“概念验证”进入“规模化应用”阶段,以下是一些典型实践: 全民健身与自然教育及可再生能源热度持续攀升,相关应用不断深化
-
航空航天领域:法国空客公司在图卢兹工厂部署了基于Transformer的飞机装配线数字孪生系统,系统通过分析历史装配数据与实时传感器数据,将装配误差从0.5毫米降至0.1毫米,单架飞机的装配周期缩短12天。
-
能源行业:中国国家电网在江苏某变电站部署了Transformer驱动的数字孪生系统,用于监控变压器运行状态,系统能通过声音、振动等多模态数据,提前48小时预测变压器故障,误报率低于2%。 2026年工业互联网与碳中和目标及音乐产业领域迎来新发展,相关应用不断深化
-
食品加工:瑞士雀巢公司在瑞士阿尔卑斯山脚下的咖啡工厂,用数字孪生系统优化烘焙工艺,Transformer模型通过分析咖啡豆的湿度、温度、烘焙时间等数据,将烘焙均匀度从85%提升至97%,产品口感一致性显著提高。
这些案例的共同点是:X世代的技术团队主导了项目实施,他们既懂工业逻辑,又善于利用AI技术;项目均从“小场景”切入(如单个设备、单个工艺环节),逐步扩展到全流程,降低了技术风险与部署成本。
一场“渐进式革命”
2026年的工业数字孪生实践,没有出现“颠覆性突破”,但“渐进式创新”正在积累质变的力量,X世代的技术专家,用他们的经验与智慧,搭建起AI与工业之间的桥梁——他们理解工业的“硬