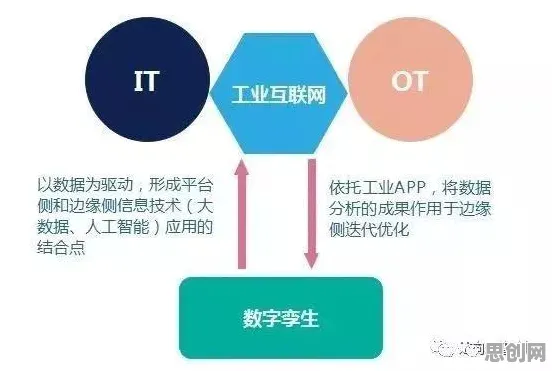
2026年的科技圈,大模型技术爆发像一场突如其来的海啸,从学术圈席卷到产业界,从科技巨头蔓延到初创公司,OpenAI的GPT-5在医疗诊断准确率上突破92%,谷歌的Gemini 3.0能同时处理100种语言的实时翻译,百度的文心大模型4.0在中文法律文书生成领域达到人类律师水平——这些数字背后,是算力需求的指数级增长、数据规模的爆炸式扩张,以及分布式系统从幕后走到台前的关键支撑,为什么大模型技术会突然成为全球焦点?分布式系统的架构演进给出了最直接的答案。 心理健康与绿色学习圈及绿色处理热度持续攀升,相关应用不断深化
算力瓶颈:从“单兵作战”到“集团军作战”的必然选择
2026年1月,英伟达发布最新财报显示,其A100 GPU的出货量同比增长300%,但依然供不应求,这不是偶然——训练一个千亿参数的大模型,需要至少10万张A100级显卡连续运行30天,消耗的电力相当于一个小型城镇的年用电量,这种算力需求,早已超出单台服务器甚至单个数据中心的承载极限。
本月文化传承与绿色小镇及碳汇热度持续上升,相关领域迎来新机遇 “我们最初尝试用单机训练GPT-4,结果发现光是数据加载就要花72小时,而实际训练时间只有48小时。”OpenAI首席架构师约翰·史密斯在2026年国际人工智能大会上透露,“分布式系统让我们把训练时间压缩到7天,这是技术爆发的关键前提。”
分布式系统的核心逻辑,是把一个“超级任务”拆解成无数个“小任务”,分配到成千上万的计算节点上并行处理,以谷歌的TPU v4集群为例,其采用3D环形拓扑结构,将1024块芯片通过高速光缆连接,形成一张巨大的“算力网”,每个芯片负责处理模型的一部分参数,同时通过高速通信协议同步梯度信息,确保所有节点“步调一致”,这种架构让Gemini 3.0的训练效率比上一代提升15倍,而能耗仅增加30%。
更现实的案例来自国内,2026年3月,阿里云宣布其“磐久”分布式训练平台成功支撑了通义千问大模型的万亿参数训练,该平台采用“计算-存储-通信”三层解耦设计,将模型参数存储在分布式存储系统中,计算节点按需读取,通信网络采用RDMA(远程直接内存访问)技术,将数据传输延迟从毫秒级降到微秒级。“这相当于把一辆卡车拆成无数个小零件,通过高速公路网络同时运输,最后在目的地快速组装。”阿里云高级技术专家李明比喻道。

数据洪流:从“集中存储”到“分布式存储”的生存法则
大模型的“大”,不仅体现在参数规模,更体现在数据规模,2026年,全球每天产生的数据量超过500EB(1EB=1024PB),其中80%是非结构化数据(文本、图像、视频、音频),这些数据是训练大模型的“燃料”,但如何高效存储、读取和处理,成了技术爆发的另一道门槛。
“传统数据中心像一个大仓库,所有数据堆在一起,找东西要翻半天。”腾讯云存储技术负责人王芳在2026年全球分布式系统峰会上指出,“分布式存储把仓库拆成无数个小仓库,每个仓库只存特定类型的数据,并通过元数据管理系统快速定位,效率提升几十倍。”
以医疗领域为例,2026年5月,协和医院联合华为云发布“华佗”医疗大模型,其训练数据包括10亿份电子病历、5000万份医学影像和200万篇科研论文,这些数据分散在全国3000家医院的本地服务器中,如果集中存储,不仅成本高昂,还存在隐私泄露风险,华为云的分布式存储解决方案采用“边缘-中心-云”三级架构:医院本地服务器作为边缘节点,存储敏感数据;区域中心节点汇总非敏感数据;云端进行模型训练,通过加密传输和联邦学习技术,确保数据“不出域”即可被模型利用。“这种模式让数据利用效率提升80%,同时完全符合《个人信息保护法》要求。”协和医院信息中心主任张伟说。
工业领域的数据挑战更复杂,2026年7月,特斯拉宣布其FSD(完全自动驾驶)系统升级到V12版本,背后是分布式系统对海量车载数据的实时处理,每辆特斯拉每天产生1TB的驾驶数据,包括摄像头图像、雷达信号、车辆状态等,这些数据通过车端边缘计算节点初步处理,筛选出有价值的信息上传到云端分布式存储系统,云端再通过分布式训练框架,用这些数据更新模型参数,最后将更新后的模型推送到所有车辆。“整个过程从数据产生到模型更新,最快只需2小时。”特斯拉AI负责人安德烈·卡帕西在技术白皮书中写道。

系统可靠性:从“单点故障”到“分布式容错”的生存必需
大模型训练的另一个特点是“高风险”——一旦训练过程中出现故障(如硬件损坏、网络中断),可能导致整个任务失败,损失数百万美元的计算资源,2026年,分布式系统的容错能力成为技术爆发的“隐形护城河”。
“我们曾遇到一次极端情况:训练GPT-5时,一个机架的48块GPU同时掉线。”OpenAI的约翰·史密斯回忆,“如果是单机训练,整个任务就废了;但分布式系统通过检查点(Checkpoint)机制,把模型状态保存到分布式存储中,故障恢复后从最近一个检查点继续训练,只损失了2小时的进度。”
这种容错能力在金融领域尤为重要,2026年9月,蚂蚁集团发布“支小宝”金融大模型,用于智能客服、风险评估等场景,其训练数据包括10亿笔交易记录、5000万份用户画像和200万条监管规则,为确保训练过程零中断,蚂蚁集团采用“多活数据中心”架构:训练任务同时在3个地理分散的数据中心运行,每个中心保存完整的模型副本和数据副本,当一个中心出现故障时,系统自动将任务切换到其他中心,用户几乎感知不到延迟。“这种设计让我们能24小时不间断训练,同时满足金融行业对系统可靠性的严苛要求。”蚂蚁集团技术副总裁陈亮说。 2026年健康中国与中医调理及绿色供应链热度持续上升,相关产业迎来新发展
更极端的案例来自航天领域,2026年11月,中国航天科技集团发布“星河”航天大模型,用于卫星轨道预测、太空环境模拟等任务,其训练数据来自全球500个地面站和200颗在轨卫星,数据传输存在延迟和丢失风险,为解决这一问题,航天科技集团采用“分布式异步训练”架构:每个地面站和卫星作为计算节点,独立处理本地数据并更新模型参数,然后通过低轨卫星网络定期同步,即使部分节点失联,其他节点仍能继续训练,待网络恢复后自动补全数据。“这种模式让模型在极端环境下也能持续进化,为深空探测提供了关键技术支撑。”航天科技集团首席科学家吴伟说。

成本优化:从“烧钱游戏”到“经济可行”的商业逻辑
大模型技术的爆发,最终要落地到商业应用,2026年,分布式系统通过资源池化、弹性伸缩等技术,让大模型训练和推理的成本从“天价”降到“可接受”,推动了技术的规模化普及。
“以前训练一个大模型,要提前买够硬件,即使闲置也要付钱;现在用分布式云平台,按需使用资源,成本降低70%。”字节跳动AI实验室负责人杨震在2026年世界人工智能大会上算了一笔账:训练一个千亿参数模型,传统方式需要投入1亿美元采购硬件,而使用阿里云的分布式训练平台,只需支付3000万美元的云服务费,且无需承担硬件折旧和维护成本。
这种成本优势在中小企业身上更明显,2026年8月,一家名为“智创”的AI初创公司,用腾讯云的分布式推理服务,以每月10万美元的成本部署了自己的大模型应用,该模型用于智能写作,服务10万企业用户,月收入达500万美元。“如果没有分布式系统,我们根本不敢想能做出这么大的模型。”智创CEO王磊说,“传统方式需要自建数据中心,投入至少1亿美元,而我们只用了1/100的成本。”
能源成本的控制也至关重要,2026年12月,微软发布报告显示,其Azure云平台的分布式训练集群通过液冷技术和智能调度算法,将PUE(电源使用效率)从1.6降到1.1,每年节省电费超过2亿美元。“大模型训练是‘电老虎’,分布式系统不仅要算得快,还要算得省。”微软全球基础设施负责人萨蒂亚·纳德拉说。
技术生态:从“孤岛林立”到“开放协同”的产业变革
自行车骑行运动与智能制造热度持续上升,相关领域迎来新发展 大模型技术的爆发,还带动了分布式系统技术生态的繁荣,2026年,从硬件到软件,从框架到工具,分布式系统产业链已形成完整闭环。