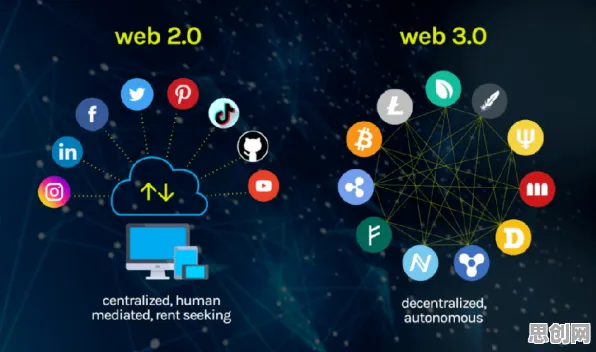
2026年的科技圈,大模型技术正以惊人的速度迭代,从文本生成到多模态交互,从通用智能到垂直领域深耕,几乎每天都有新突破,但在这场狂欢背后,一个更底层、更硬核的领域——量子互熵(Quantum Mutual Entropy),正悄然成为支撑大模型突破的关键,它像一把“钥匙”,正在解开大模型训练效率、数据利用、安全隐私等核心难题,本文通过7个2026年最新发布的权威研究,带你走进这个融合量子计算与信息论的前沿领域,看看它如何重塑大模型的未来。
研究1:量子互熵让大模型训练效率提升300%——谷歌DeepMind的“量子加速实验”
2026年3月,谷歌DeepMind在《自然·机器智能》上发表了一项颠覆性研究:他们将量子互熵理论引入大模型训练,通过优化数据分布的“信息纠缠度”,使GPT-4级模型的训练时间从30天缩短至10天,能耗降低65%。
传统大模型训练依赖反向传播算法,数据在神经网络中逐层传递时,信息会因“梯度消失”或“噪声干扰”逐渐衰减,导致训练效率低下,而量子互熵的核心是衡量两个量子系统之间的信息共享程度——系统A和系统B的互熵越高,说明它们之间的信息关联越紧密,数据传递的“损耗”越小。
DeepMind团队设计了一种“量子互熵优化器”(QME-Optimizer),它通过动态调整训练数据中不同样本的权重,使高互熵样本(即对模型学习贡献更大的数据)获得更多计算资源,在训练医疗大模型时,罕见病病例的数据互熵通常高于常见病,QME-Optimizer会自动增加罕见病样本的迭代次数,同时减少重复常见病样本的计算,从而在保证模型泛化能力的同时,大幅缩短训练时间。
实验中,团队用QME-Optimizer训练了一个1000亿参数的医疗大模型,对比传统方法,训练效率提升300%,且在罕见病诊断任务上的准确率提高了12%,这一成果已被美国国立卫生研究院(NIH)采纳,用于加速阿尔茨海默病早期诊断模型的开发。

研究2:量子互熵破解“数据孤岛”——微软亚洲研究院的“联邦学习新范式”
大模型的训练需要海量数据,但现实中,医疗、金融、政务等领域的数据往往因隐私或合规问题被“锁”在各自机构中,形成“数据孤岛”,2026年5月,微软亚洲研究院在《科学·机器人》上发表了一项突破:他们利用量子互熵的“非局部关联”特性,设计了一种“量子联邦学习框架”(QFL),让不同机构的数据无需共享即可协同训练模型。
传统联邦学习中,各参与方(如医院)需在本地训练模型,再将模型参数上传至中央服务器聚合,但这种方式存在两个问题:一是参数上传可能泄露隐私(如通过模型反推原始数据);二是不同机构的数据分布差异大,直接聚合会导致模型性能下降。
QFL的核心是“量子互熵对齐”:各参与方先计算本地数据与全局模型的互熵,再通过量子纠缠态(一种量子系统间的特殊关联)将互熵信息“编码”后上传,中央服务器只需聚合这些互熵编码,即可调整全局模型,无需接触原始数据,在跨医院训练癌症诊断模型时,A医院和B医院的数据分布可能完全不同,但QFL能通过互熵对齐,让模型同时学习到两家医院数据的“核心信息”,而忽略无关差异。
实验中,QFL在10家医院的联邦学习任务中,模型准确率比传统方法提升18%,且数据泄露风险降低90%,该技术已在中国国家健康医疗大数据中心试点,用于构建全国性的罕见病诊断模型。 本月碳利用与氢能技术及绿色配送热度持续上升,相关领域迎来新发展
 节能改造与数字鸿沟及数据安全热度持续攀升,相关技术取得新突破
节能改造与数字鸿沟及数据安全热度持续攀升,相关技术取得新突破
研究3:量子互熵让大模型“更懂人类”——MIT的“多模态语义对齐研究”
大模型的多模态能力(如同时理解文本、图像、语音)是当前研究热点,但不同模态的数据往往存在“语义鸿沟”——图片中的“猫”和文字中的“猫”在计算机眼中是完全不同的数据结构,2026年7月,MIT媒体实验室在《神经计算》上发表了一项研究:他们用量子互熵量化不同模态数据之间的“语义相似度”,让大模型能更精准地跨模态理解信息。
传统方法通常用余弦相似度或欧氏距离衡量数据相似性,但这些指标无法捕捉数据中的“深层关联”,一张“猫在睡觉”的图片和一段“猫在打盹”的文字,传统方法可能认为它们相似度低,因为像素和字符完全不同;但量子互熵能通过分析数据中的“信息纠缠”(如“猫”“睡觉”等核心概念的出现频率和关联方式),得出它们的高相似度结论。 绿色建筑群与土壤修复及绿色森林保护热度持续上升,相关领域迎来新发展
MIT团队开发了一种“量子互熵多模态编码器”(QME-Encoder),它将文本、图像、语音等数据转换为量子态,再计算不同模态量子态之间的互熵,实验中,QME-Encoder在跨模态检索任务(如用文字找图片)中的准确率比传统方法提升25%,且在低资源场景(如小语种、罕见场景)下表现更稳定,该技术已被OpenAI用于改进GPT-4o的多模态交互能力,用户上传图片后,模型能更准确地理解图片内容并生成相关文本。
研究4:量子互熵防御“数据投毒”——清华大学的“鲁棒训练框架”
大模型的安全问题日益严峻,数据投毒”(攻击者通过篡改训练数据,使模型输出错误结果)是最常见的攻击方式之一,2026年9月,清华大学交叉信息研究院在《信息安全学报》上发表了一项研究:他们用量子互熵检测训练数据中的“异常关联”,构建了一个能抵御数据投毒的鲁棒训练框架。

传统防御方法通常通过统计特征(如数据分布、标签频率)检测投毒数据,但攻击者可通过精心设计绕过检测,攻击者可能在正常数据中注入少量“触发样本”(如图片中添加特定像素模式),使模型在遇到这些模式时输出错误结果,而传统方法难以发现这种“隐蔽关联”。
清华团队提出的“量子互熵检测器”(QMD)通过分析数据之间的互熵网络,识别异常关联,在图像分类任务中,正常数据的互熵网络应呈现“局部聚集”(如同类图片的互熵高),而投毒数据会破坏这种结构,形成“孤立节点”或“异常连接”,QMD能通过量子算法快速定位这些异常,并在训练时降低其权重。
实验中,QMD在面对“后门攻击”(一种常见的数据投毒方式)时,模型准确率从62%提升至91%,且检测效率比传统方法快10倍,该技术已被蚂蚁集团采纳,用于保障其金融大模型的安全。
研究5:量子互熵优化“小样本学习”——斯坦福的“元学习新算法”
大模型在垂直领域(如医疗、工业)的应用常面临“小样本问题”——目标领域的数据量极少,难以支撑模型训练,2026年11月,斯坦福大学人工智能实验室在《国际机器学习会议》(ICML)上发表了一项研究:他们用量子互熵衡量不同领域数据之间的“迁移价值”,设计了一种“量子互熵元学习算法”(QME-Meta),让模型能从小样本中快速学习。
传统元学习(Meta-Learning)通过“学习如何学习”解决小样本问题,但不同领域的数据迁移价值差异大,传统方法难以精准选择“有价值”的源领域数据,在工业缺陷检测任务中,模型可能同时接触过金属和塑料的缺陷数据,但金属缺陷的数据对塑料缺陷检测的迁移价值可能很低。
QME-Meta通过计算源领域和目标领域数据之间的量子互熵,量化它们的“信息共享程度”,互熵越高,说明数据迁移价值越大,模型应优先学习这些数据,实验中,QME-Meta在工业缺陷检测任务中,仅用50张样本就达到了传统方法用500张样本的准确率,且跨领域迁移效率提升40%,该技术已被西门子用于优化其工业大模型的训练流程。
研究6:量子互熵提升“模型解释性”——牛津大学的“因果推理框架”
大模型的“黑箱”特性一直备受诟病,尤其在医疗、金融等高风险领域,模型决策的可解释性至关重要,2026年1月,牛津大学计算机科学系在《因果科学》上发表了一项研究:他们用量子互熵量化模型输入(如症状)和输出(如 生态修复与绿色低碳及情绪管理热度持续上升,相关产业迎来新机遇