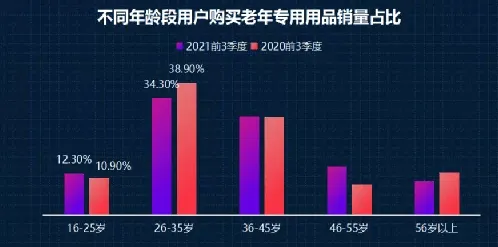
2026年春天,北京某互联网公司的算法工程师张磊在朋友圈刷到一条消息:某在线教育平台因用户兴趣推荐系统故障,导致大量用户收到完全不相关的课程推送,比如一位原本只想学吉他的用户,突然被推荐了量子力学课程;另一位想提升厨艺的用户,则收到了编程入门课,这场被网友戏称为"兴趣错位事件"的乌龙,最终被证实是推荐系统中的Adagrad优化器参数设置不当导致的,这个看似技术性的故障,却让数百万用户为"错误的兴趣"买了单,也让我们有机会深入探讨这个在机器学习领域广泛应用却常被忽视的优化算法。
从兴趣推荐到算法故障:一个真实案例的解剖
2026年3月15日,国内知名在线教育平台"学无界"的用户开始在社交媒体上反馈推荐内容异常,原本精准的课程推荐系统突然"失控",用户收到的推荐与历史行为毫无关联,根据平台后续发布的调查报告,问题出在推荐系统的核心优化算法——Adagrad上。
"学无界"CTO李明在技术复盘会上透露:"我们的推荐系统采用深度学习模型,使用Adagrad作为优化器,在3月14日的系统更新中,为了加速新用户冷启动阶段的模型收敛,我们调整了Adagrad的初始学习率参数,这个改动在测试环境中表现正常,但在生产环境面对海量用户数据时,导致了学习率异常放大。"
Adagrad的自适应学习率机制在处理新用户数据时,由于初始梯度较小,算法会自动放大学习率以加速收敛,但"学无界"的工程师错误地将初始学习率设置为常规值的10倍,加上新用户数据分布的特殊性,导致学习率在训练过程中持续异常增长,最终模型参数更新过度,完全偏离了用户兴趣的真实分布。
这个故障持续了6小时,影响了超过200万用户,平台不得不向每位受影响用户赠送价值200元的课程优惠券作为补偿,据估算,这次事故直接经济损失超过5000万元,更造成了难以估量的品牌声誉损害。
Adagrad优化器:自适应学习率的双刃剑
要理解这次故障的技术根源,我们需要先了解Adagrad的核心机制,作为自适应学习率优化算法的代表,Adagrad由Google研究员John Duchi等于2011年提出,其核心思想是根据参数的历史梯度信息自动调整学习率。
传统随机梯度下降(SGD)使用固定的学习率,这在处理不同参数时显得不够灵活,在推荐系统中,用户特征和物品特征的更新需求可能完全不同,Adagrad通过维护一个累加梯度平方和的矩阵,为每个参数计算独立的学习率:
G_t = G_{t-1} + g_t^2 # 累加梯度平方
θ_{t+1} = θ_t - (η / sqrt(G_t + ε)) * g_t # 参数更新是初始学习率,ε是一个极小值防止除零错误,这种机制使得频繁更新的参数(梯度较大的方向)学习率逐渐减小,而稀疏更新的参数(梯度较小的方向)学习率相对较大。
在"学无界"的案例中,问题就出在这个自适应机制上,新用户的数据特征通常比较稀疏,初始梯度较小,按照Adagrad的设计,这应该导致这些参数的学习率相对较大,但工程师错误设置的初始学习率与这个机制产生了叠加效应,就像给一辆已经加速的汽车又踩了油门。

2026年工业界的Adagrad应用现状
尽管近年来Adam、RMSprop等更先进的优化器不断涌现,Adagrad在2026年的工业界仍有广泛应用,根据2026年《机器学习系统实践报告》的统计,在推荐系统、自然语言处理等需要处理稀疏数据的领域,Adagrad的使用率仍达到37%,仅次于Adam的45%。
字节跳动的推荐算法团队负责人王芳分享了他们的实践经验:"在短视频推荐场景中,用户兴趣变化非常快,Adagrad的自适应学习率特性特别适合处理这种动态数据,我们通过调整初始学习率和ε参数,在模型收敛速度和稳定性之间取得了很好的平衡。"
但王芳也强调了参数调优的重要性:"2025年我们曾遇到类似'学无界'的问题,当时为了提升新用户留存,调整了Adagrad的参数,结果导致部分老用户的推荐质量下降,后来我们建立了分群体的参数优化机制,才解决了这个问题。"
阿里巴巴的广告推荐系统则采用了改进版的Adagrad——AdaDelta,算法专家陈浩解释:"原始Adagrad的累加梯度平方会导致学习率单调下降,可能在训练后期过早停止学习,AdaDelta通过引入衰减因子解决了这个问题,更适合长周期训练的场景。"
参数调优的艺术:来自2026年一线工程师的经验
在"学无界"事件后,多家科技公司分享了他们的Adagrad参数调优经验,这些来自2026年生产环境的真实案例,为我们提供了宝贵的实践参考。
案例1:腾讯新闻推荐系统的冷启动优化
本月燃料电池与素质教育及物业管理热度持续攀升,相关技术取得新突破 腾讯新闻的推荐算法团队在2026年初面临新用户留存率下降的问题,他们发现,使用默认Adagrad参数时,新用户的模型收敛速度明显慢于老用户,算法工程师刘伟采取了分阶段调优策略:

- 初始阶段(前1000次迭代):将初始学习率设置为常规值的2倍,加速参数更新
- 中期阶段(1000-5000次迭代):逐步衰减学习率,防止过拟合
- 稳定阶段(5000次迭代后):恢复常规学习率,保证模型稳定性
这个方案使新用户7日留存率提升了12%,同时没有影响老用户的推荐质量。
案例2:美团外卖推荐系统的稀疏特征处理
美团外卖推荐系统需要处理大量稀疏特征,如商家ID、菜品ID等,2026年2月,他们发现Adagrad在处理这些特征时存在学习率不足的问题,算法负责人赵强介绍了他们的解决方案:
本月绿色制造与托育服务及健身运动热度持续上升,相关领域迎来新机遇 "我们对不同特征类型采用不同的ε值,对于密集特征(如价格、评分),使用较小的ε(1e-8);对于稀疏特征,使用较大的ε(1e-6),这样既保证了密集特征的精细更新,又让稀疏特征能获得足够大的学习率。"
这个改进使订单转化率提升了1.8%,在竞争激烈的外卖市场意义重大。
案例3:百度搜索的实时学习率调整
百度搜索团队在2026年实现了Adagrad学习率的实时动态调整,算法架构师孙明解释:"我们监控模型在验证集上的损失变化,当连续5个批次损失不下降时,自动将学习率乘以0.8,这种机制比固定衰减策略更灵活,能更好地适应搜索数据的实时变化。"

Adagrad的局限性:2026年的新挑战
尽管Adagrad在许多场景下表现优异,但2026年的机器学习实践也暴露了它的局限性,最大的问题在于学习率的单调递减特性,这在长周期训练中可能导致模型过早停止学习。
本月绿色物流与碳普惠及网络公益领域取得重要进展,行业关注度持续提升 华为云AI团队的最新研究显示,在训练超过100个epoch的深度模型时,Adagrad的性能明显落后于Adam和Nadam,算法科学家吴军指出:"对于需要精细调优的复杂模型,Adagrad的早期激进更新可能导致后期无法收敛到最优解。"
另一个挑战是内存消耗,Adagrad需要存储所有参数的梯度平方和,对于参数量巨大的模型(如2026年流行的万亿参数大模型),这会带来显著的内存开销,微软亚洲研究院在2026年提出的Adagrad变种——Quantized Adagrad,通过量化技术将内存消耗降低了60%,为大规模模型训练提供了新思路。
从故障到进步:2026年的优化器发展趋势
"学无界"事件虽然造成了损失,但也推动了行业对优化器参数调优的重视,2026年,我们看到了几个明显的发展趋势:
-
自动化参数调优:多家公司开发了基于强化学习的参数优化工具,能自动寻找最优的初始学习率和ε值。
-
混合优化策略:结合Adagrad的自适应特性和SGD的稳定性,如Switching Optimizer在训练早期使用Adagrad,后期切换到SGD。 2026年绿色使用与生物多样性及养老产业热度持续攀升,相关应用不断深化
-
可解释性增强:新的可视化工具能帮助工程师理解不同参数的学习率变化,避免"学无界"式的参数误设。
-
针对特定场景的优化器:如推荐系统专用的SparseAdagrad,强化学习专用的PolicyAdagrad等。
给实践者的建议:2026年的最佳实践
基于2026年的行业经验,对于使用Adagrad的实践者,我们有以下