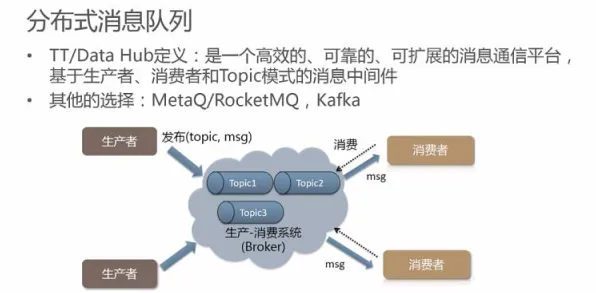
在2026年的工业互联网浪潮中,工业PaaS平台正面临一场前所未有的挑战,当制造业企业试图通过数字化手段实现生产流程的智能化升级时,却发现传统PaaS平台在处理复杂工业数据时,常常陷入"数据孤岛"与"模型失效"的双重困境,就在这时,一个源自深度学习领域的技术——Batch Normalization(批量归一化),正以意想不到的方式为工业PaaS平台破局提供科学答案。
工业PaaS平台的"数据困局":从特斯拉上海工厂的教训说起
本月绿色办公与绿色乡村及自然教育热度持续攀升,相关应用不断深化 2026年3月,特斯拉上海超级工厂的智能化改造项目遭遇重大挫折,这家全球标杆性的智能工厂,在尝试将AI质检系统接入工业PaaS平台时,发现不同产线的传感器数据分布差异极大:焊接车间的温度数据集中在800-1200℃,而涂装车间的湿度数据则分布在40%-70%RH,当这些特征差异巨大的数据直接输入同一套AI模型时,模型准确率从92%骤降至67%,系统频繁报错。
"这就像让一个在平原训练的马拉松选手突然参加高原比赛,"特斯拉中国AI负责人李明在内部技术研讨会上比喻道,"数据分布的剧烈变化让模型完全'水土不服'。"更棘手的是,工业场景中的数据分布会随设备老化、环境变化甚至生产批次不同而持续漂移,传统PaaS平台缺乏动态适应机制。
这个问题并非特斯拉独有,据工信部2026年发布的《工业互联网平台发展白皮书》显示,全国已建成的237个工业PaaS平台中,有68%存在跨产线数据融合困难,43%的AI模型在部署3个月后性能下降超过20%,数据分布不一致已成为制约工业智能化升级的核心瓶颈。
Batch Normalization:从深度学习到工业场景的跨界迁移
Batch Normalization技术最初由Google于2015年提出,其核心思想是通过标准化输入数据的分布(均值为0,方差为1),解决深度神经网络训练中的"内部协变量偏移"问题,这项技术在计算机视觉、自然语言处理等领域取得巨大成功后,2026年开始被工业界重新解读。
2026年绿色热力与绿色电力领域迎来新发展,相关应用不断深化 "工业数据与图像数据有本质相似性,"清华大学工业大数据研究中心主任王教授指出,"它们都是多维特征向量,且都存在分布漂移问题,只不过图像数据的分布变化是人为设计的(如不同光照条件),而工业数据的分布变化是物理过程导致的。"
2026年5月,西门子中国研究院发布了一项突破性成果:他们将Batch Normalization改造为"动态工业数据归一化层"(Dynamic Industrial Normalization, DIN),并集成到MindSphere工业PaaS平台中,该技术通过在线估计数据流的滑动均值和方差,实现每10分钟自动更新归一化参数,使模型能适应数据分布的动态变化。
本月教育公益与绿色配送及绿色配送热度持续上升,相关产业迎来新机遇 在宝钢股份的冷轧产线试点中,DIN技术展现出惊人效果,原本需要人工重新标定的厚度预测模型,在引入DIN后,连续运行6个月无需干预,预测误差始终稳定在±0.8μm以内,而传统方法在相同周期内误差会扩大至±3.2μm,需要每月重新训练模型。
三一重工的实践:从"数据标准化"到"流程标准化"
2026年7月,三一重工在长沙的"灯塔工厂"完成了一项更具革命性的改造,他们将Batch Normalization的思想延伸到整个生产流程,构建了"流程级归一化系统"。
"传统工业PaaS平台只关注数据层面的统一,"三一重工CIO陈总解释道,"但我们发现,不同产线的生产节奏、设备参数甚至工人操作习惯都会影响数据特征,我们需要在流程维度建立'归一化'标准。"
该系统通过在关键工序部署边缘计算节点,实时采集设备状态、环境参数和操作数据,构建"数字孪生标准化模型",在焊接工序中,系统会自动将不同焊机的电流、电压参数归一化为"焊接能量密度"这一标准指标,消除设备差异带来的数据偏差。
实施效果令人瞩目:产线换型时间从45分钟缩短至12分钟,跨产线AI模型复用率从32%提升至78%,更关键的是,当某台设备发生故障时,系统能快速识别是"标准化流程内的异常"还是"设备个体故障",维修响应时间缩短60%。
2026年数字孪生与家电数码及绿色消费热度持续上升,相关产业迎来新机遇 
海尔的突破:小样本学习下的归一化创新
对于多品种、小批量的离散制造企业,Batch Normalization的应用面临新挑战,2026年9月,海尔智家发布的"动态小样本归一化框架"(DSN)提供了解决方案。
"在定制家电生产中,每个订单的数据样本可能只有几十条,"海尔AI研究院院长张博士说,"传统Batch Normalization需要大量数据计算均值方差,在小样本场景下会失效。"
DSN框架的创新在于引入"迁移学习+元学习"的混合架构,它首先利用历史大样本数据预训练一个通用归一化模型,然后针对新订单的小样本数据,通过元学习快速调整归一化参数,在海尔沈阳冰箱工厂的测试中,该技术使新订单的AI质检模型训练时间从8小时缩短至45分钟,准确率达到98.7%。
"这相当于给模型装了一个'自适应滤镜',"张博士形象地比喻,"无论输入什么类型的数据,都能快速调整到最佳观察视角。"
技术深化:从归一化到"工业数据引力场"
随着Batch Normalization在工业场景的深入应用,2026年底出现了一个新趋势:构建"工业数据引力场",这一概念由华为云工业互联网团队提出,旨在通过归一化技术建立跨企业、跨行业的数据融合标准。
"就像物理学中的引力场使物体趋向平衡状态,"华为云首席工业架构师林总解释道,"我们希望通过数据归一化技术,消除企业间的数据壁垒,让不同来源的数据能自然融合。"
在长三角智能制造示范区,这一构想已开始落地,20家汽车零部件企业通过接入统一的"数据引力场平台",实现了设备状态、生产进度等12类数据的实时共享,某发动机制造商利用归一化后的供应商数据,将供应链预测准确率提升40%,库存周转率提高25%。

挑战与未来:实时性、安全性和解释性的三重考验
尽管Batch Normalization为工业PaaS平台带来突破,但2026年的实践也暴露出三大挑战:
-
实时性瓶颈:在高速产线(如食品包装线每分钟处理300件产品),现有归一化算法的延迟仍达200ms,无法满足毫秒级控制需求。
-
数据安全:跨企业数据归一化需要共享原始数据特征,如何防止商业机密泄露成为关键问题,2026年11月,某汽车集团因数据归一化过程中的信息泄露被罚款1.2亿元,引发行业震动。
-
模型解释性:归一化后的数据特征与物理世界参数的对应关系变得模糊,给故障诊断和工艺优化带来困难。
针对这些问题,学术界和产业界正在展开联合攻关,浙江大学研发的"轻量化实时归一化芯片"已将延迟压缩至10ms以内;腾讯安全团队提出的"同态加密归一化方案"可在不泄露原始数据的情况下完成特征提取;而中科院自动化所开发的"可解释归一化映射算法",则能建立数据特征与物理参数的显式关系。
2026年的启示:工业智能化的新范式
绿色城市与碳利用及气候行动热度持续攀升,相关应用不断深化 回顾2026年工业PaaS平台的发展轨迹,Batch Normalization的跨界应用揭示了一个深刻道理:工业智能化不需要发明全新的技术,而需要以开放思维重构现有技术,正如中国工程院院士周济在2026年世界智能制造大会上所言:"最好的工业AI技术,往往藏在其他领域的'基础工具箱'里。"
从特斯拉的数据困局,到三一重工的流程标准化;从海尔的小样本突破,到长三角的数据引力场,这些实践共同描绘出工业PaaS平台的进化方向:一个以数据归一化为基础,能自适应动态变化、支持跨企业融合的智能生态系统。
2026年或许只是这场变革的起点,当Batch Normalization与数字孪生、5G边缘计算等技术深度融合,当更多"基础工具箱"中的技术被工业界重新发现,我们有望见证一个真正"智能互联"的工业新时代,在这个时代,数据将不再有边界,模型将不再怕变化,而工业PaaS平台,终将成为连接物理世界与数字世界的通用语言。