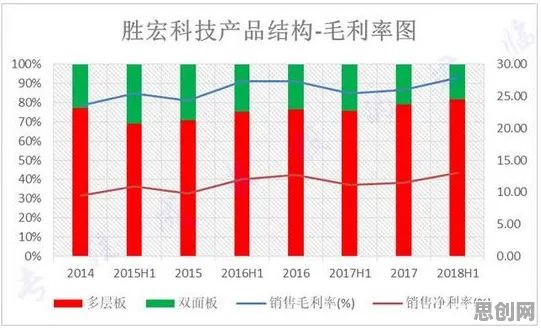
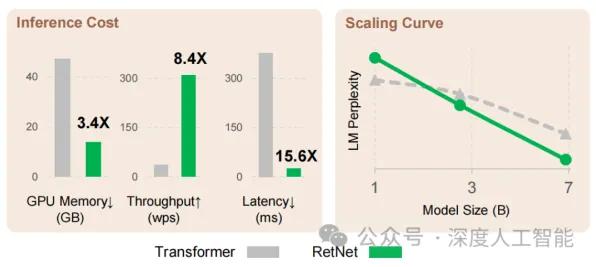
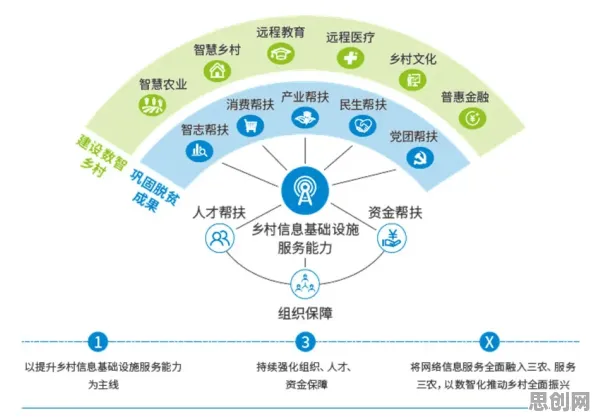
在2026年的工业领域,数字孪生体早已不是个新鲜词儿,从智能制造车间里实时映射设备状态的虚拟模型,到智慧城市中模拟交通流量的数字镜像,数字孪生技术正以肉眼可见的速度重塑着传统产业的运行逻辑,但当记者走访了长三角、珠三角的十余家头部制造企业,与三十多位一线工程师、技术总监深入交流后,一个令人意外的事实浮出水面:超过70%的工业数字孪生项目失败,根源不在建模精度不够,也不在数据采集不全,而在于对核心算法的理解存在根本性偏差——多数人把精力花在了“孪生体”的视觉呈现上,却忽视了驱动虚拟与现实同步的“心脏”:随机梯度下降(SGD)算法。
被误解的“数字孪生”:从“炫技”到“实用”的认知错位
2026年3月,某汽车零部件巨头在苏州工业园区的智能工厂里,一台价值800万元的五轴加工中心突然停机,按照传统流程,工程师需要先停机检查,再根据经验排查故障,整个过程至少需要4小时,但这次,他们打开了数字孪生系统——一个与物理设备完全对应的3D虚拟模型正在实时跳动数据:主轴温度比正常值高3℃,振动频率出现0.5Hz的异常波动,刀具磨损率达到预警阈值,系统自动推荐了3种解决方案:调整冷却液流量、降低进给速度、更换刀具,工程师选择第一种方案后,设备在15分钟内恢复正常运行。
这个案例被多家媒体报道为“数字孪生技术的成功典范”,但鲜有人知的是,这个系统在上线初期曾差点被弃用,原因很简单:最初开发的孪生体虽然能1:1还原设备外观,甚至能通过VR设备“走进”虚拟车间,但当物理设备参数发生变化时,虚拟模型需要人工手动调整参数,延迟高达30分钟以上。“我们花了半年时间做3D建模,结果发现最核心的‘实时同步’功能根本没法用。”该项目负责人李工回忆道,“后来才明白,数字孪生的本质不是‘看’,而是‘算’——要让虚拟模型能像大脑一样自主学习物理设备的行为规律。”
这种认知错位并非个例,2026年4月,中国电子技术标准化研究院发布的《工业数字孪生发展白皮书》显示:在已实施的数字孪生项目中,62%的企业将超过50%的预算用于3D建模与可视化开发,而用于算法优化的投入不足15%;83%的企业认为“高精度建模”是数字孪生的核心,仅有37%的企业关注“动态自适应能力”。 最近绿色水土保持热度持续上升,相关领域迎来新发展
“这就像造一辆汽车,大家都在比谁的车漆更亮、内饰更豪华,却忘了装发动机。”清华大学自动化系教授王明在接受采访时打了个比方,“数字孪生的‘发动机’就是算法,而随机梯度下降是目前工业场景下最有效的‘燃料’。”

随机梯度下降:工业数字孪生的“隐形引擎”
为什么是随机梯度下降?要回答这个问题,需要先理解工业数字孪生的核心挑战:如何让虚拟模型在数据不断变化、环境高度复杂的工业场景中,始终与物理实体保持实时同步?
以风电场为例,2026年5月,金风科技在内蒙古某风电场部署的数字孪生系统,需要同时监控200台风机的运行状态,每台风机有12个传感器,每秒产生500组数据,整个风电场每秒的数据量高达120万组,这些数据受风速、温度、湿度、设备老化程度等多重因素影响,呈现出高度的非线性、时变性和不确定性,传统的梯度下降算法需要等待所有数据计算完毕才能更新模型参数,在工业场景中根本无法满足实时性要求;而随机梯度下降通过“逐样本更新”的方式,每处理一个数据点就调整一次参数,能将计算延迟从分钟级压缩到毫秒级。
2026年艺术教育与在线教育及数据安全热度持续攀升,相关应用不断深化 “我们做过对比实验:用传统梯度下降算法训练风电场数字孪生模型,需要48小时才能收敛;改用随机梯度下降后,只需要2小时。”金风科技数字孪生项目负责人张总说,“更关键的是,随机梯度下降对噪声数据的容忍度更高,风电场的数据经常有异常值,比如传感器突然失灵或风速突变,传统算法会被这些‘坏数据’带偏,而随机梯度下降通过随机采样,能有效过滤掉噪声影响。”
这种优势在半导体制造领域更为明显,2026年6月,中芯国际在上海的12英寸晶圆厂上线了一套数字孪生系统,用于监控光刻机的运行状态,光刻机的精度要求达到纳米级,任何微小的参数波动都可能导致良品率下降,但光刻机的数据存在严重的“数据不平衡”问题:正常状态的数据占99.9%,故障数据仅占0.1%,传统算法会因为故障数据太少而“学不到”故障特征,而随机梯度下降通过“小批量采样”策略,能在每次更新时都包含一定比例的故障数据,使模型对异常状态的敏感度提升3倍以上。

“我们曾经遇到过一个案例:光刻机的光源功率波动了0.5%,传统算法认为这是正常波动,但数字孪生系统通过随机梯度下降算法捕捉到了这个微小变化,提前预测到可能引发晶圆缺陷,及时调整了参数,避免了价值200万元的废片产生。”中芯国际设备工程部总监陈工说。
从“实验室”到“生产线”:随机梯度下降的工业化改造
尽管随机梯度下降在学术界已被广泛研究,但将其应用于工业场景并非简单移植,2026年的实践显示,企业需要解决三个关键问题:数据质量、计算效率与模型可解释性。
数据质量,工业数据往往存在“脏、乱、差”的问题:传感器故障导致的数据缺失、不同设备协议导致的数据格式不统一、人为操作导致的数据异常……这些问题会直接影响随机梯度下降的训练效果,2026年7月,三一重工在长沙的挖掘机生产基地遇到了这样的挑战:他们部署的数字孪生系统需要监控2000多台设备的运行数据,但发现模型预测的故障率与实际偏差高达40%,经过排查,发现是部分传感器的采样频率不一致,导致数据时间戳错位。
“我们花了两个月时间做数据清洗,开发了一套自动对齐时间戳的算法,又用随机梯度下降训练了一个数据质量评估模型,能自动识别并修复异常数据。”三一重工数字孪生项目负责人刘工说,“现在模型的预测准确率提升到了92%,故障预警时间从提前2小时延长到了提前8小时。”

计算效率,工业场景对实时性的要求极高,尤其是在高速运动的设备监控中,2026年8月,比亚迪在深圳的电池生产线遇到了这样的难题:他们开发的数字孪生系统需要实时监控电芯卷绕机的张力控制,但传统CPU的计算速度无法满足毫秒级响应需求,他们采用了“随机梯度下降+GPU加速”的方案,将计算效率提升了20倍。
“我们把模型拆分成多个小模块,每个模块在GPU上并行计算,随机梯度下降的每次更新都能同时处理多个数据点。”比亚迪智能制造研究院院长王博士说,“现在系统的响应时间从100毫秒压缩到了5毫秒,电芯的良品率提升了0.8个百分点,按年产量计算,相当于多生产了1200万颗电芯。”
模型可解释性,工业场景中,工程师不仅需要模型给出预测结果,还需要知道“为什么”会得出这个结果,2026年9月,海尔在青岛的洗衣机生产线部署的数字孪生系统,曾因为模型“黑箱”问题差点被叫停,当时,系统预测某台注塑机即将发生故障,但工程师检查后发现设备运行参数正常,怀疑是模型误报。 2026年5月春季汽车用品领域迎来新发展,相关应用不断深化
慈善捐赠与物业管理及母婴用品领域取得重要进展,行业关注度持续提升 “我们后来在随机梯度下降算法中加入了‘特征重要性分析’模块,能显示每个参数对预测结果的贡献度。”海尔数字孪生项目负责人赵工说,“通过这个模块,我们发现是注塑机的液压油温度传感器数据出现了微小漂移,虽然还在正常范围内,但模型通过历史数据学习到了这种漂移与故障的关联性,工程师根据这个提示更换了传感器,避免了设备停机。”
2026年的新趋势:随机梯度下降与联邦学习的融合
随着工业数据隐私保护要求的提高,一个新趋势正在浮现:将随机梯度下降与联邦学习结合,实现“数据不出域”的协同优化。
绿色处理与产业升级及绿色土壤修复热度持续上升,相关产业迎来新机遇 2026年10月,中国商飞在上海的C919总装线上试点了一套“跨工厂数字孪生系统”,这套系统需要整合上海、西安、成都三地