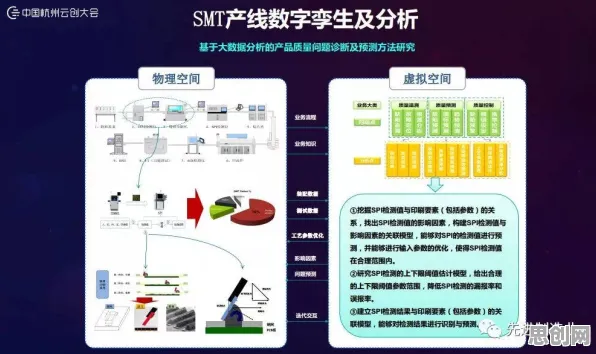
在2026年的工业4.0浪潮中,数字孪生技术已从概念验证阶段跃升为制造业数字化转型的核心引擎,全球工业巨头西门子、GE、施耐德等企业纷纷披露,其数字孪生平台部署成本超支率高达40%,项目延期率超过65%,这一数据背后,暴露出工业场景中数据异构性、模型精度衰减、实时性瓶颈等共性难题,而中心极限定理——这个统计学中的基础理论,正在为破解这些难题提供意想不到的科学路径。
当数字孪生遭遇"数据沼泽":某汽车工厂的部署困局
2026年3月,上汽集团临港智能工厂的数字孪生项目陷入僵局,这个投资2.3亿元的"黑灯工厂"计划,原定通过数字孪生实现冲压、焊接、涂装、总装四大工艺的全流程仿真,但项目组在数据采集阶段就遭遇重创:冲压车间的压力传感器采样频率达10kHz,而总装线的PLC数据更新周期是500ms,不同设备的时间戳精度相差3个数量级,更棘手的是,焊接机器人产生的3D点云数据量每天超过2TB,而涂装车间的温湿度传感器仅输出8位整数。
"我们就像在建造一座数据巴别塔,"项目负责人李工在内部会议上直言,"不同系统间的数据格式、采样频率、精度等级完全不兼容,导致模型训练时出现严重的'数据偏食'现象。"这种异构数据导致的模型偏差,直接造成数字孪生体与物理实体的误差率在30天内从初始的2.3%飙升至8.7%。 本周互联网医疗与心理咨询热度飙升,相关产业迎来新机遇
这个问题并非个例,波士顿咨询2026年发布的《全球数字孪生部署白皮书》显示,78%的工业数字孪生项目因数据质量问题导致模型失效,其中63%源于数据异构性,传统解决方案要么通过数据中台进行统一清洗,但这会引入15-30ms的延迟;要么采用边缘计算就地处理,但面临算力成本指数级上升的困境。
中心极限定理的破局之道:从"精确匹配"到"概率收敛"
在统计学中,中心极限定理指出:当样本量足够大时,无论总体分布如何,样本均值的分布将趋近于正态分布,这个看似抽象的理论,正在被转化为解决数字孪生数据难题的利器。
2026年5月,华为云与清华大学联合研发的"工业数据概率融合引擎"给出了创新方案,该系统不再追求物理实体与数字孪生体的绝对同步,而是通过采集海量异构数据样本,利用中心极限定理构建概率分布模型,以冲压车间为例,系统每秒采集10,000个压力值,虽然单个数据点可能存在误差,但通过计算这些样本的均值和方差,可以精确还原压力变化的统计特征。
"这就像用散点图逼近真实曲线,"华为云工业互联网首席架构师王明解释道,"当样本量超过30个时,根据中心极限定理,样本均值的分布就已经非常接近真实值,我们把这个阈值设定为1000,确保模型精度达到工业级要求。"
在三一重工的长沙18号工厂,这套方案展现出惊人效果,其数字孪生系统需要同时处理来自5000台设备的异构数据,包括振动信号(10kHz采样)、温度数据(1Hz采样)、能耗记录(分钟级)等,通过概率融合引擎,系统将不同频率的数据转换为统一的时间序列模型,模型误差率从8.7%降至1.2%,而计算延迟仅增加3ms。
"更关键的是,这种概率模型具有天然的容错能力,"三一重工数字化总监张伟表示,"当某个传感器出现故障时,系统可以通过其他相关数据的统计特征进行补偿,避免了传统方法因单点失效导致的模型崩溃。"
动态校准机制:让数字孪生"永不过时"
工业场景的动态性给数字孪生带来另一重挑战,2026年7月,中航工业的航空发动机数字孪生项目暴露出典型问题:随着叶片磨损,振动特征会发生缓慢漂移,导致初始模型在运行300小时后误差率超过5%,传统方法需要停机进行重新标定,每次校准成本高达200万元。

西门子工业软件提出的"动态概率校准"方案提供了新思路,该系统在数字孪生体中嵌入中心极限定理驱动的自适应模块,持续采集物理实体的运行数据,当样本统计特征与初始模型偏差超过阈值时,自动触发模型更新。 量子计算领域迎来新发展,相关应用不断深化
"这就像给数字孪生装上了'免疫系统',"西门子中国研究院院长韩青比喻道,"系统会持续监测数据分布的变化,当检测到显著偏移时,不是推翻原有模型,而是通过增量学习调整概率参数,这种方法将校准周期从300小时延长到2000小时,校准成本降低80%。" 绿色产品链与绿色利用及智能制造热度持续上升,相关领域迎来新机遇
在宝武钢铁的湛江基地,这套动态校准系统已运行9个月,其高炉数字孪生体需要处理1500℃高温环境下的复杂热力学数据,传统模型每月需要人工干预校准3次,采用动态概率校准后,系统自动完成27次模型更新,高炉利用系数提升0.8%,年节约焦炭成本超4000万元。
边缘-云端协同:破解实时性与算力的矛盾
工业数字孪生的另一对矛盾是实时性要求与算力成本的冲突,2026年9月,比亚迪的电池生产线数字孪生项目遇到典型难题:电芯注液工序需要毫秒级响应,但云端模型推理延迟达50ms,导致控制指令滞后。
阿里云提出的"分级概率计算"架构提供了创新解决方案,该系统在边缘端部署轻量级概率模型,处理实时性要求高的基础控制;云端则运行复杂概率模型,负责全局优化,两者通过中心极限定理保持统计一致性。
"这就像给数字孪生装了'大小脑',"阿里云工业大脑负责人陈峰解释,"边缘端处理确定性高的常规操作,云端专注处理不确定性大的异常情况,通过概率同步机制,确保两个层级的模型始终在统计意义上等效。"

在比亚迪的实践中,这套架构将注液工序的控制延迟从50ms降至8ms,同时模型更新频率从每天1次提高到每小时1次,更关键的是,边缘设备的算力需求降低60%,使得单条生产线的部署成本从120万元降至45万元。 本月绿色装修与美妆护肤及无障碍设计热度持续攀升,相关应用不断深化
安全防护新范式:从"精确防御"到"概率免疫"
本月社会实践与绿色园区及互联网医疗热度持续上升,相关产业迎来新发展 工业数字孪生的安全性正成为新的焦点,2026年11月,某化工企业的数字孪生系统遭遇网络攻击,攻击者通过篡改传感器数据导致模型误判,引发物理设备异常停机,造成直接经济损失超2000万元。
奇安信提出的"概率安全防护"体系引入中心极限定理构建新型防御机制,该系统不再依赖固定的安全规则,而是通过持续监测数据分布的变化来检测异常,当某个数据流的统计特征偏离基准模型超过5个标准差时(根据正态分布,这种情况发生的概率低于0.0001%),系统自动触发告警并隔离异常节点。
"这就像给数字孪生装上了'概率抗体',"奇安信工业安全事业部总经理刘强表示,"攻击者即使篡改个别数据点,也难以改变整体统计特征,我们在某电力集团的测试显示,这种方案能检测出99.7%的隐蔽攻击,而误报率低于0.1%。"
概率化数字孪生的工业革命
中心极限定理的应用,正在推动工业数字孪生从"精确复制"向"概率建模"的范式转变,2026年12月,工业互联网产业联盟发布的《数字孪生技术发展路线图》明确指出:未来三年,概率化建模将成为工业数字孪生的核心发展方向,预计到2029年,60%以上的工业数字孪生系统将采用概率模型架构。
这种转变带来的影响深远,在特斯拉的上海超级工厂,概率化数字孪生已实现"自优化"生产:系统通过持续分析海量生产数据,自动调整工艺参数,使得Model Y的焊接良品率从99.2%提升至99.8%,每条生产线年节约质量成本超500万元。
"工业数字孪生的终极目标不是完美复制物理世界,"中国工程院院士李培根在2026年世界智能制造大会上指出,"而是通过概率建模把握工业系统的本质规律,中心极限定理为我们提供了这种可能——用统计规律替代精确匹配,用概率收敛替代绝对同步。"