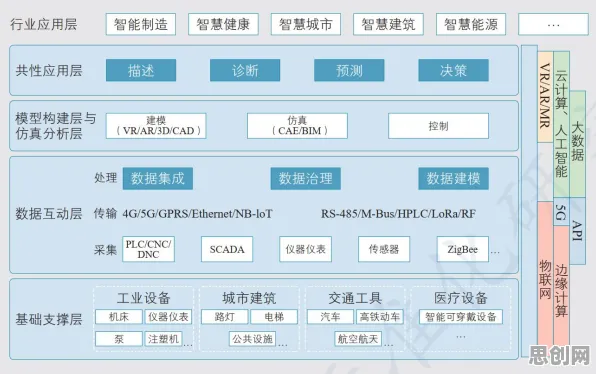
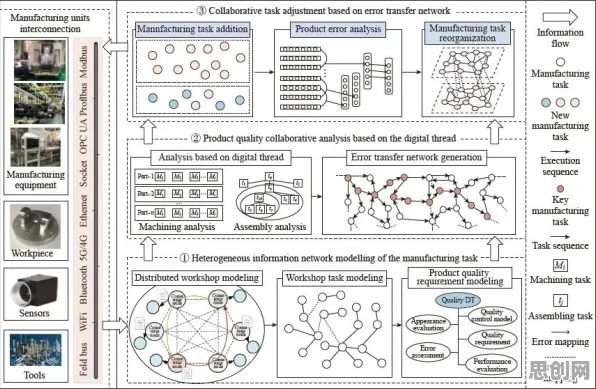
汽车制造巨头的跨工厂协同:联邦学习破解数据孤岛困局
2026年3月,全球知名汽车制造商“华宇汽车”宣布其位于长三角的三个生产基地实现数字孪生平台全链路打通,生产效率提升18%,设备故障预测准确率突破92%,这一成果的背后,是联邦学习技术对传统数据共享模式的颠覆。
华宇汽车此前面临一个典型难题:三个工厂分别部署了独立的数字孪生系统,每个系统都积累了大量生产数据(如设备振动频率、温度曲线、质量检测结果),但受限于数据安全合规要求(尤其是涉及商业机密的生产工艺参数),这些数据无法直接共享,若强行集中存储,不仅面临数据泄露风险,还可能因数据传输延迟影响模型实时性。
“我们试过用传统加密技术传输数据,但解密后的数据在云端处理时仍存在被截获的风险;也考虑过建立数据中台,但各工厂对数据主权非常敏感,协调成本极高。”华宇汽车工业大数据负责人李明回忆道。
2025年底,华宇汽车引入联邦学习框架后,问题迎来转机,联邦学习的核心逻辑是“数据不动模型动”——各工厂的数字孪生系统作为本地节点,在本地训练设备故障预测模型,仅将模型参数(而非原始数据)上传至中央服务器进行聚合,中央服务器通过加密算法对参数进行安全融合,生成全局优化模型后再下发至各工厂。
具体到实施层面,华宇汽车采用了“分层联邦学习”架构:第一层在单个工厂内部,将冲压、焊接、涂装、总装四大车间的数字孪生数据按设备类型划分节点,训练车间级模型;第二层在三个工厂之间,将同类型车间的模型参数进行跨厂聚合,生成覆盖长三角区域的生产优化模型,焊接车间的机器人臂振动数据模型,通过联邦学习融合后,能识别出某批次零件因材质差异导致的异常振动模式,这种模式在单个工厂的数据中可能因样本不足被忽略,但跨厂聚合后则成为关键特征。
“最直观的变化是,以前一个工厂发现设备故障模式后,需要人工整理报告分享给其他工厂,现在通过联邦学习,模型自动学习并推广优化方案,响应速度从‘天级’缩短到‘小时级’。”李明举例说,2026年1月,苏州工厂的涂装车间通过联邦学习模型提前48小时预测到喷漆机器人喷嘴堵塞风险,及时更换部件避免了生产线停机,而这一风险模式正是通过聚合上海工厂的历史数据学习到的。
能源企业的供应链韧性提升:联邦学习赋能跨企业协同
如果说华宇汽车的案例聚焦于企业内部数据协同,那么2026年5月公布的“中能集团供应链数字孪生项目”则展示了联邦学习在跨企业场景中的应用潜力,中能集团是国内领先的能源装备制造商,其供应链涉及上游300余家零部件供应商、中游15家物流服务商和下游5大电力集团客户,传统模式下,供应链数字孪生系统因数据分散在各企业,难以实现全局优化——供应商的生产进度数据、物流商的运输状态数据、客户的设备运行数据均独立存储,且涉及商业机密(如供应商的产能利用率、客户的设备故障率)无法直接共享。
“2025年我们曾尝试建立供应链数据中台,但供应商普遍担心数据泄露会影响其市场竞争力,尤其是那些同时为竞争对手供货的企业,拒绝提供核心数据。”中能集团供应链数字化总监王芳坦言。

2026年初,中能集团联合供应链伙伴引入联邦学习技术,构建了“供应链联邦数字孪生平台”,该平台的核心创新在于“数据可用不可见”——各企业保留数据所有权,仅通过加密接口与平台交互模型参数,当预测某批次零部件的交付延迟风险时,供应商的数字孪生系统在本地训练交付时间预测模型,输入数据包括原材料库存、生产线排程、员工出勤率等;物流商的模型则输入运输车辆位置、天气状况、交通管制信息;中能集团的模型输入客户需求优先级、库存缓冲水平,三方模型通过联邦学习聚合后,生成综合交付风险评分,而整个过程中,任何一方的原始数据均未离开其本地系统。
本月碳封存与绿色沙漠治理及绿色处理热度飙升,相关产业迎来新机遇 一个典型应用场景是2026年3月的“极端天气应对”,当时,长三角地区遭遇持续暴雨,多家物流商的运输路线受阻,通过联邦学习平台,中能集团实时聚合各物流商的运输状态模型(如某条路线的积水深度预测、车辆绕行时间计算)和供应商的生产调整模型(如因原材料运输延迟导致的产能下调预测),自动生成供应链调整方案:将原本由受阻物流商承运的紧急订单,动态分配给其他可用物流商;同时建议供应商提前启动备用生产线弥补产能缺口,中能集团成功将暴雨导致的交付延迟率从行业平均的15%降至3%。
“联邦学习的价值在于,它让供应链从‘各自为战’变成‘协同作战’,而不需要任何一方牺牲数据安全。”王芳强调,“甚至我们的竞争对手也在关注这个项目,因为联邦学习提供了一种‘竞合模式’——在保障自身数据主权的前提下,通过模型共享实现行业整体效率提升。”
半导体工厂的良率提升:联邦学习与数字孪生的深度融合
在半导体制造这一对数据敏感度极高的行业,联邦学习与数字孪生的融合展现了更精细化的应用场景,2026年7月,国内领先的12英寸晶圆厂“芯联科技”公布其良率提升成果:通过联邦学习驱动的数字孪生平台,某关键制程的良率从88%提升至93%,每年节省成本超2亿元。 2026年绿色社区与家电数码热度持续攀升,相关技术取得新突破

半导体制造的复杂性决定了良率提升需要整合多维度数据:设备参数(如光刻机的曝光能量、蚀刻机的气体流量)、环境数据(如洁净室的温湿度、颗粒物浓度)、工艺数据(如化学药剂的配比、沉积时间)以及质量检测数据(如晶圆表面的缺陷类型、位置),传统方法中,这些数据由不同部门管理(设备部管设备参数、环境部管温湿度、工艺部管化学药剂),且因涉及生产机密(如某款芯片的特殊工艺参数),数据共享存在严格限制。
“我们曾尝试用差分隐私技术对数据脱敏后共享,但脱敏后的数据价值大幅下降,模型准确率不足60%;若不脱敏,又无法通过安全审计。”芯联科技CTO陈峰回忆道。
2025年下半年,芯联科技引入“联邦学习+数字孪生”的混合架构:在单个生产线上构建数字孪生体,将设备、环境、工艺、质量数据实时映射到虚拟空间,训练本地良率预测模型;通过联邦学习将多条生产线的模型参数进行聚合,生成工厂级全局模型;将全局模型反馈至各生产线的数字孪生体,优化控制参数。
一个关键创新是“动态联邦学习”——根据生产阶段动态调整数据共享范围,在光刻制程中,不同生产线的光刻机型号可能不同(如ASML的NXT:2050i和NXT:2100i),此时联邦学习仅聚合同型号设备的模型参数,避免因设备差异导致模型偏差;而在蚀刻制程中,所有生产线使用相同型号的蚀刻机,则可全量聚合参数,芯联科技还开发了“模型贡献度评估算法”,根据各生产线数据对全局模型的提升效果,动态调整其参数权重——数据质量高的生产线在聚合时获得更高权重,激励各部门主动优化数据采集质量。
“最让我们惊喜的是,联邦学习还帮助我们发现了隐藏的生产规律。”陈峰举例说,通过聚合多条生产线的模型,平台发现某批次化学药剂的供应商变更与晶圆边缘缺陷率上升存在强相关性,而这一规律在单个生产线的数据中因样本不足未被识别,进一步追溯发现,新供应商的药剂在低温环境下稳定性下降,导致蚀刻不均匀,基于这一发现,芯联科技调整了化学药剂的存储温度控制策略,单这一项改进就使良率提升1.2个百分点。
联邦学习与数字孪生的“化学反应”:从技术融合到业务变革
从上述三个案例可以看出,联邦学习与数字孪生的结合并非简单叠加,而是通过“数据安全-模型优化-业务创新”