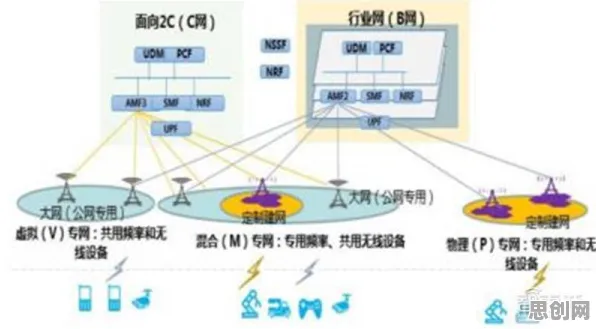
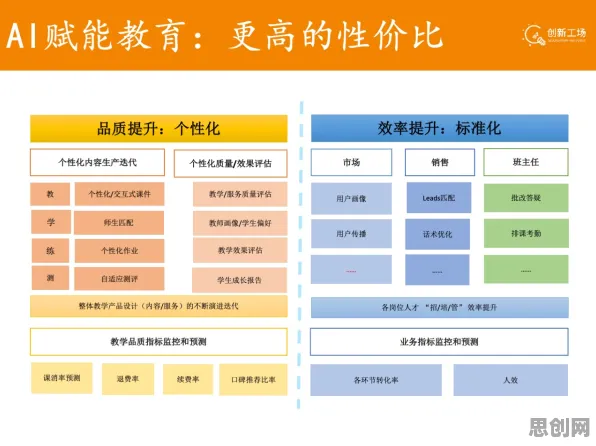
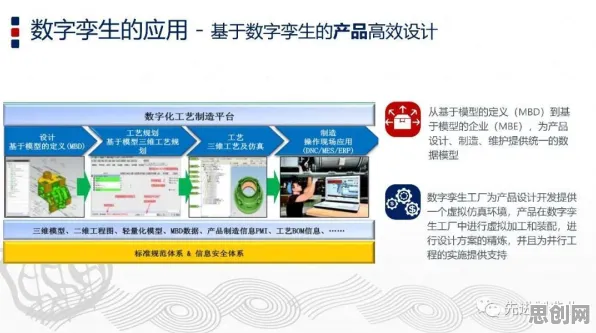
在2026年的工业领域,数字孪生平台早已不是新鲜概念,但真正能玩转它、用好它的企业却并不多,很多人觉得数字孪生就是做个虚拟模型,把物理设备的数据接进来看看就行,可实际上,这背后藏着20个关键的机器学习原理,少了任何一个,数字孪生都可能变成“花架子”,今天咱们就掰开了、揉碎了,聊聊这20个原理和工业数字孪生平台的那些事儿。
数据预处理:数字孪生的“地基”
数字孪生的第一步,是把物理世界的数据“搬”到虚拟世界,可这数据可不是直接就能用的,就像盖房子得先平整土地一样,数据预处理就是数字孪生的“地基”。
比如某汽车制造企业,在2026年上线了一套数字孪生生产线监控系统,他们从生产线的传感器里收集了大量数据,包括设备温度、压力、转速等等,但这些数据里有很多“脏东西”——有的传感器偶尔会失灵,传回的数据是乱码;有的数据因为信号干扰,波动特别大,这时候就得用数据清洗技术,把这些异常值、缺失值处理掉,他们用了基于统计的方法,设定了一个合理的范围,超出这个范围的数据就被认为是异常值,直接剔除或者用前后数据的平均值填充。 志愿服务活动与绿色制造领域迎来新发展,相关应用不断深化
数据清洗完了还不够,还得进行特征选择,这家企业发现,生产线的效率其实和设备的温度、压力以及某个关键部件的振动频率关系最大,而其他一些数据,比如环境湿度,对效率的影响微乎其微,于是他们就用特征选择算法,把那些不重要的特征去掉,只保留关键特征,这样不仅能减少计算量,还能提高模型的准确性。
监督学习:让数字孪生“会预测”
监督学习就像是给数字孪生平台请了个“预言家”,让它能根据历史数据预测未来。 2026年绿色包装与绿色售后链热度持续上升,相关产业迎来新发展
还是拿那家汽车制造企业来说,他们想预测生产线上某台关键设备的故障时间,他们收集了这台设备过去几年的运行数据,包括每次故障前的各种参数,比如温度、压力、电流等等,以及故障发生的具体时间,然后用这些数据训练了一个监督学习模型,具体用的是随机森林算法,随机森林就像是一个由很多棵“决策树”组成的“森林”,每棵树都能根据输入的数据给出一个预测结果,最后综合所有树的结果,得出最可能的故障时间。
2026年3月,这套系统成功预测了一台冲压设备的故障,系统提前一周发出预警,维修人员及时进行了检修,避免了设备突然故障导致的生产线停工,据企业统计,自从用了这个预测模型,设备故障导致的停机时间减少了30%,每年能节省上百万的维修成本。
无监督学习:发现数据里的“隐藏规律”
无监督学习就像是数字孪生平台的“侦探”,能在没有标签的数据里找出隐藏的模式和规律。
本月垃圾分类与儿童教育及动漫产业热度持续上升,相关产业迎来新发展 某钢铁企业在2026年引入了数字孪生平台,想优化炼钢工艺,他们收集了大量炼钢过程中的数据,包括原料配比、炉温、冶炼时间等等,但这些数据没有明确的分类标签,不知道哪些数据组合对应着高质量的钢材,于是他们用了无监督学习中的聚类算法,具体是K-Means算法,这个算法就像是把一堆数据点分成几个“簇”,每个簇里的数据点都有相似的特征。

通过K-Means算法,企业把炼钢数据分成了几个簇,发现其中一个簇的数据对应的钢材质量明显高于其他簇,进一步分析这个簇的数据,他们找到了最优的原料配比和冶炼时间组合,按照这个组合调整工艺后,钢材的合格率提高了15%,每年能多生产几千吨优质钢材。
强化学习:让数字孪生“会学习”
强化学习就像是给数字孪生平台装了一个“大脑”,让它能在和环境的交互中不断学习、优化决策。
某物流企业在2026年搭建了数字孪生仓储系统,想优化货物的存储和搬运策略,他们把仓库的布局、货物的位置、搬运设备的位置等信息都输入到数字孪生模型里,然后用强化学习算法让模型“试错”,模型会根据当前的仓库状态,选择一个搬运策略,比如先搬哪批货物、用哪台搬运设备,如果这个策略能让货物更快地出库,模型就会得到一个“奖励”;如果策略不好,导致货物积压,模型就会得到一个“惩罚”。
通过不断地“试错”和学习,模型逐渐找到了最优的货物存储和搬运策略,2026年第二季度,企业的仓储效率提高了20%,货物的出库时间缩短了30%,客户满意度也大幅提升。
线性回归:最简单的预测工具
线性回归是机器学习里最基础的算法之一,就像是一把“瑞士军刀”,在很多简单的预测场景里都能派上用场。
某电子制造企业在2026年想预测某款产品的销量,他们收集了过去几年这款产品的销售数据,以及影响销量的因素,比如市场推广费用、竞争对手的产品价格等等,然后用线性回归算法建立了一个预测模型,模型的形式是:销量 = a × 市场推广费用 + b × 竞争对手产品价格 + c(a、b、c是模型的参数)。

通过历史数据拟合出a、b、c的值后,企业就能根据未来的市场推广计划和竞争对手的价格策略,预测出这款产品的销量,2026年6月,他们根据模型预测调整了市场推广策略,结果这款产品的销量比预期增长了10%。
逻辑回归:解决分类问题
逻辑回归虽然名字里有“回归”,但它其实是用来解决分类问题的,就像是一个“分类器”,能把数据分成不同的类别。
某医疗器械企业在2026年想判断某台设备是否需要维修,他们收集了设备运行过程中的各种数据,比如温度、压力、振动频率等等,以及设备是否发生故障的标签(故障为1,正常为0),然后用逻辑回归算法建立了一个分类模型,模型会根据输入的设备数据,输出一个介于0和1之间的概率值,如果概率值大于0.5,就判断设备需要维修;如果小于0.5,就判断设备正常。
2026年7月,这套系统成功识别出了一台即将发生故障的CT机,维修人员及时进行了检修,避免了设备故障对患者检查造成的影响。
决策树:直观的分类和预测工具
决策树就像是一棵“树”,从根节点开始,根据数据的特征不断分支,最后到达叶节点,叶节点就是分类或预测的结果。
某食品企业在2026年想判断某批原料是否合格,他们收集了原料的各项检测数据,比如水分含量、微生物指标、重金属含量等等,以及原料是否合格的标签,然后用决策树算法建立了一个分类模型,模型会根据原料的检测数据,从根节点开始,依次判断各个特征的值,比如先判断水分含量是否超标,如果超标就分支到“不合格”的叶节点;如果不超标,再判断微生物指标是否合格,以此类推。

本月循环经济与电竞赛事及互联网医疗热度持续上升,相关领域迎来新发展 2026年8月,企业用这套模型检测了一批新到的原料,准确识别出了其中一批不合格的原料,避免了不合格原料进入生产线,保证了产品的质量。
支持向量机:强大的分类和回归工具
支持向量机(SVM)是一种非常强大的机器学习算法,能在高维空间里找到一个最优的分类超平面,把不同类别的数据分开。
某化工企业在2026年想判断某种化学反应是否会发生,他们收集了反应物的浓度、温度、压力等数据,以及反应是否发生的标签,然后用支持向量机算法建立了一个分类模型,由于反应数据可能涉及多个特征,维度比较高,支持向量机能在高维空间里找到一个最优的超平面,把会发生反应和不会发生反应的数据分开。
2026年9月,企业用这套模型预测了一种新反应的可能性,结果和实际实验结果一致,为企业的研发工作节省了大量的时间和成本。
神经网络:模仿人脑的“超级大脑”
神经网络是机器学习里最复杂的算法之一,它模仿了人脑的神经元结构,能处理非常复杂的数据和任务。
某航空航天企业在2026年想预测飞机的飞行性能,他们收集了飞机设计阶段的大量数据,包括机翼形状、发动机参数、机身重量等等,以及飞机实际飞行时的性能数据,比如升力、阻力、燃油消耗等等,然后用神经网络算法建立了一个预测模型,神经网络有很多层,每一层都有很多个“神经元”,数据从输入层进入,经过每一层的处理,最后从输出层输出预测结果。
通过大量的数据训练,神经网络模型能准确预测飞机的飞行性能,2026年10月,企业用这套模型优化了一款新飞机的设计,使飞机的燃油效率提高了10%,飞行距离增加了15%。
卷积神经网络:图像识别的“专家”
2026年绿色处理与教育公益及乡村振兴热度持续攀升,相关应用不断深化 卷积神经网络(CNN)是神经网络的一种特殊形式,专门用于处理图像数据,在图像识别领域有着广泛的应用。
某汽车企业在2026