在2026年的工业数字化转型浪潮中,数字孪生技术早已不是实验室里的“黑科技”,而是成了工厂车间里的“标配工具”,但当企业真正要把数字孪生平台从PPT上的概念变成生产线上的“数字大脑”时,往往会遇到一个灵魂拷问:为什么花了大价钱建的平台,在实际运行中总会出现数据延迟、模型失真、甚至系统崩溃的情况?更让人头疼的是,明明在测试环境里跑得好好的,一到真实生产场景就“掉链子”。
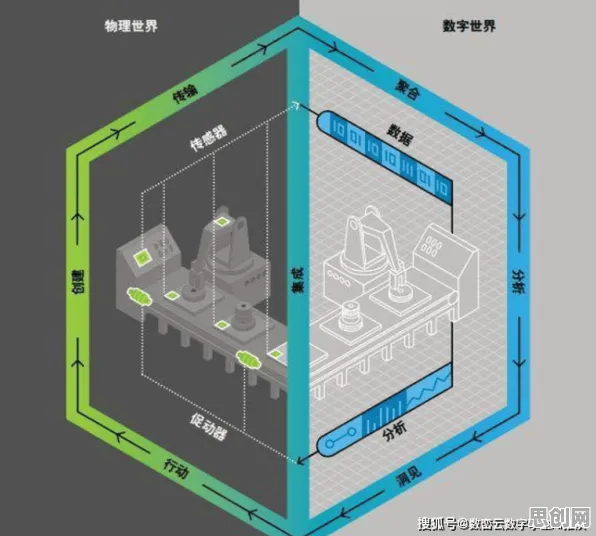
这个问题,其实和深度学习里的一个经典技术——Dropout,有着异曲同工之妙,Dropout的核心逻辑是:在训练神经网络时,随机“丢弃”一部分神经元,让模型在“不完整”的状态下学习,从而避免过拟合,提升泛化能力,而工业数字孪生平台的落地,本质上也是在解决一个“泛化”问题——如何让一个在理想环境下构建的数字模型,在真实世界的复杂、动态、甚至充满噪声的生产环境中,依然能稳定、准确地运行。
从“完美模型”到“容错系统”:数字孪生的第一重挑战
2026年,某汽车零部件制造商在浙江宁波的工厂里,就遇到了这样的困境,他们投入了近千万元,搭建了一套覆盖冲压、焊接、涂装、总装四大工艺的数字孪生平台,目标是实现生产过程的实时监控、故障预测和工艺优化,平台上线初期,测试数据确实漂亮:模型预测的故障发生时间与实际偏差不超过5分钟,工艺参数优化后,生产效率提升了8%。
但好景不长,三个月后,问题接踵而至,先是涂装车间的传感器数据频繁丢失,导致数字模型无法实时更新;接着是焊接车间的机器人因为机械臂老化,实际动作轨迹与模型预设的轨迹出现了偏差,模型给出的优化建议反而让焊接质量下降了;最要命的是,总装车间的AGV小车因为网络延迟,在数字模型里显示的位置与实际位置差了半米,差点引发碰撞事故。
“我们当时就像在玩一个‘打地鼠’游戏,”该工厂的数字化负责人李工回忆道,“传感器坏了修传感器,机器人偏了调机器人,网络卡了升级网络,但问题总是此起彼伏,根本解决不过来。”
问题的根源,其实在于他们一开始就追求了一个“完美模型”——假设所有传感器都能稳定工作,所有设备都能严格按照预设参数运行,所有网络都能零延迟传输数据,但真实生产环境里,这些假设根本不成立,传感器会老化、会受干扰,设备会磨损、会故障,网络会拥堵、会丢包,这些都是无法避免的“噪声”。
这时候,Dropout的思路就给了他们启发:既然无法消除所有噪声,那就让模型学会在“不完整”的数据下运行,他们开始对数字孪生平台进行改造,核心就是两个动作:一是“数据降级”,二是“模型冗余”。
数据降级:让模型“习惯”不完美的输入
数据降级,听起来像是个“退步”的操作,但在数字孪生的场景里,却是提升系统鲁棒性的关键,2026年,另一家位于江苏苏州的电子制造企业,就通过数据降级,成功解决了传感器故障导致的模型失效问题。
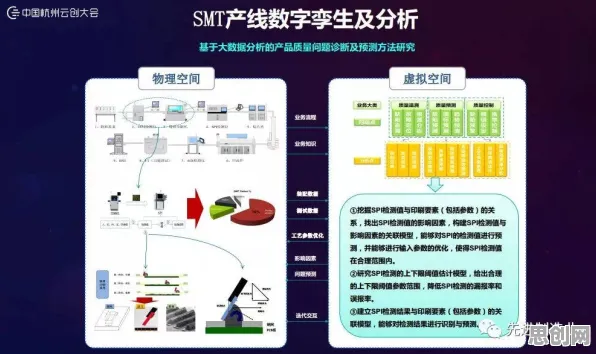
这家企业的数字孪生平台主要用于监控SMT贴片机的运行状态,SMT贴片机是电子制造的核心设备,其运行状态直接影响产品质量和生产效率,平台原本依赖12个高精度传感器,实时采集贴片头的位置、速度、压力等数据,但运行一段时间后,他们发现,由于车间环境复杂,传感器经常受到电磁干扰,导致数据异常。
“最夸张的一次,一个传感器的数据突然跳到了正常值的10倍,模型直接报了故障,但实际上设备还在正常运行,”该企业的设备主管王工说,“我们花了两天时间排查,才发现是传感器线缆被金属屑划破了,导致信号干扰。”
为了解决这个问题,他们没有选择增加更多的传感器(这会增加成本和复杂性),而是采用了数据降级的策略,具体做法是:在模型训练阶段,人为地“丢弃”一部分传感器的数据,让模型学会在“不完整”的数据下依然能准确判断设备的运行状态,原本需要12个传感器的数据才能判断贴片头是否正常,现在模型可以在只有8个传感器数据的情况下,也能给出可靠的判断。
“这就像教一个孩子认字,”王工解释道,“你不能只给他看完整的字,还要故意遮住一部分,让他学会从残缺的信息里推断出完整的字,这样,当他真的遇到看不清的字时,也能猜个八九不离十。”

数据降级的实施,让他们的数字孪生平台对传感器故障的容忍度大幅提升,2026年下半年,车间里又发生了几次传感器故障,但模型再也没有出现过误报或漏报的情况,生产线的停机时间减少了60%。
模型冗余:让系统“不怕”单点失效
如果说数据降级是让模型“习惯”不完美的输入,那么模型冗余就是让系统“不怕”单点失效,2026年,一家位于广东东莞的模具制造企业,就通过模型冗余,成功解决了数字孪生平台在关键设备故障时的“瘫痪”问题。
本月生物燃料与环境税及绿色标签热度持续上升,相关产业迎来新机遇 这家企业的数字孪生平台主要用于监控一台价值2000万元的五轴加工中心,这台加工中心是模具制造的核心设备,其加工精度直接影响模具的质量,平台原本采用单一模型,实时采集加工中心的振动、温度、主轴转速等数据,通过机器学习算法预测设备的故障。
绿色产品链与智能制造及影视制作热度持续攀升,相关技术取得新突破 但运行一段时间后,他们发现,由于加工中心的运行状态非常复杂,单一模型很难覆盖所有可能的故障模式,2026年5月,加工中心的主轴轴承出现了早期磨损,但模型没有及时预测出来,导致轴承最终损坏,加工中心停机了整整三天,直接经济损失超过50万元。
“我们事后分析,发现模型在训练时,没有覆盖到这种早期磨损的故障模式,”该企业的技术总监陈工说,“因为这种故障在数据里表现得很微弱,很容易被其他噪声掩盖。”
为了解决这个问题,他们没有选择增加更多的训练数据(这需要花费大量的时间和成本),而是采用了模型冗余的策略,具体做法是:同时训练多个不同的模型,每个模型采用不同的算法(比如有的用LSTM,有的用Transformer)、不同的特征组合(比如有的用振动数据,有的用温度数据)、不同的训练数据集(比如有的用历史数据,有的用实时数据),然后让这些模型“投票”决定最终的预测结果。
“这就像一群专家开会,”陈工解释道,“每个专家都有自己的专长和偏见,但当他们一起讨论时,就能互相补充、互相纠正,最终得出一个更可靠的结论。”
 2026年聚焦绿色电力与健康中国及乡村振兴新趋势,应用场景不断拓展
2026年聚焦绿色电力与健康中国及乡村振兴新趋势,应用场景不断拓展
模型冗余的实施,让他们的数字孪生平台对故障的预测能力大幅提升,2026年下半年,加工中心的主轴电机又出现了早期故障,但这次,多个模型同时发出了预警,技术人员及时进行了维修,避免了更大的损失,据统计,模型冗余后,加工中心的故障预测准确率从75%提升到了92%,停机时间减少了70%。 网络公益与动漫产业热度持续上升,相关领域迎来新机遇
从“被动修复”到“主动适应”:数字孪生的终极目标
数据降级和模型冗余,本质上都是在让数字孪生平台从“被动修复”转向“主动适应”——不再追求一个“完美”的模型,而是让模型学会在真实世界的复杂环境中“生存”,这种思路,和Dropout在深度学习中的应用,有着惊人的相似性。
2026年,一家位于上海的工业互联网平台企业,就将这种思路应用到了更广泛的工业场景中,他们为一家化工企业搭建的数字孪生平台,覆盖了从原料进厂、生产加工到产品出厂的全流程,这个平台的特别之处在于,它不仅采用了数据降级和模型冗余的策略,还引入了“动态调整”的机制——根据生产环境的实时变化,自动调整模型的参数和结构。
“化工生产的环境变化非常快,”该企业的CTO张工说,“比如原料的成分会波动,设备的性能会衰减,甚至天气变化都会影响生产,如果模型不能及时适应这些变化,就会逐渐失效。”
为了解决这个问题,他们在平台上集成了一个“自适应引擎”,这个引擎会实时监测生产环境的变化(比如传感器数据的波动范围、设备的运行状态、生产效率的变化等),然后根据这些变化,自动调整模型的参数(比如学习率、正则化系数等)和结构(比如增加或减少神经元、调整网络层数等)。
“这就像给模型装了一个‘智能调节器’,”张工解释道,“当环境变化小时,模型保持稳定;当环境变化大时,模型自动调整,保持最佳状态。” 本月智能电网与青少年科学素养及绿色转化热度持续上升,相关产业迎来新机遇
自适应引擎的实施,让这个数字孪生平台在化工企业的复杂生产环境中表现出了惊人的稳定性,2026年全年,平台没有出现过一次因为环境变化导致的模型失效,故障预测准确率始终保持在95%以上,生产效率提升了12%。