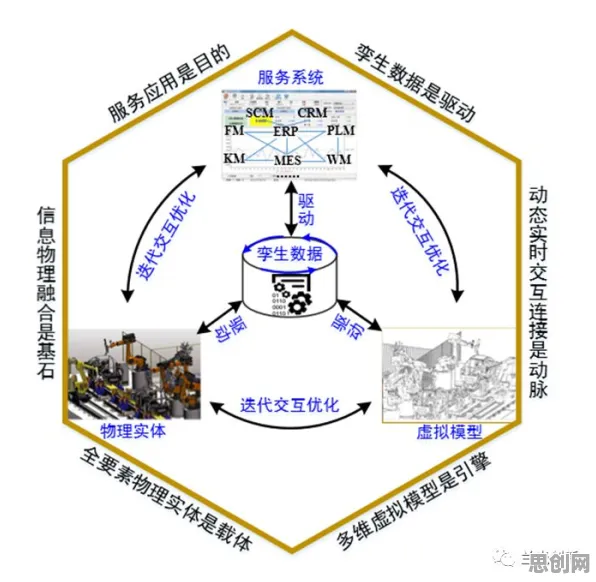
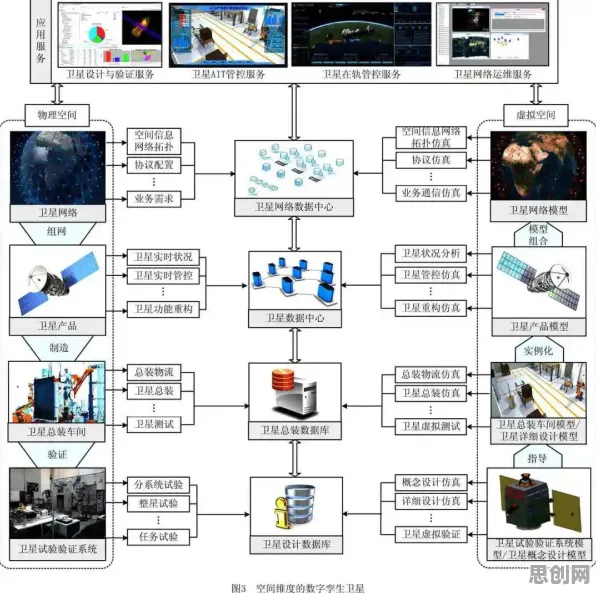
数据孤岛的“心理枷锁”:从“不愿共享”到“主动协作”
可持续时尚与绿色营销链及低代码开发热度持续攀升,相关领域迎来新突破 在2026年的中国长三角地区,一家年产值超百亿的汽车零部件企业正面临一个棘手问题:他们拥有全球最先进的冲压生产线,但设备故障率却比同行高出15%,问题出在数据上——这家企业的生产线数据分散在三个独立系统中:生产部门的设备运行数据、质量部门的检测数据、研发部门的仿真数据,彼此之间像“孤岛”一样无法互通,更关键的是,各部门对数据共享存在强烈的心理抵触:生产部门担心数据泄露影响生产安全,质量部门害怕数据被滥用影响考核,研发部门则顾虑核心算法被竞争对手获取。
“我们曾尝试用传统数据中台整合数据,但各部门负责人直接拍桌子反对。”该企业CIO李明回忆道,“他们说‘数据是我的命根子,凭什么交出去?’”这种心理并非个例,根据2026年麦肯锡发布的《全球工业数据治理报告》,超过70%的制造企业存在“数据孤岛”问题,其中62%的阻力来自部门或团队对数据共享的担忧。
联邦学习的出现,为打破这种心理枷锁提供了技术解法,与传统数据集中存储不同,联邦学习采用“数据不动模型动”的模式:各部门的数据仍保留在本地,仅通过加密算法交换模型参数,2026年,这家汽车零部件企业引入了基于联邦学习的数字孪生平台,各部门在无需共享原始数据的情况下,共同训练了一个设备故障预测模型,三个月后,模型准确率达到92%,设备故障率下降了40%。
“最关键的是心理变化。”李明说,“现在各部门主动要求接入更多数据源,因为他们知道数据不会离开自己的控制范围,这种安全感,比任何管理指令都有效。”这种心理转变在2026年的工业界并非孤例,在德国西门子安贝格电子制造工厂,联邦学习被用于整合全球12个生产基地的生产数据,各部门的数据共享意愿提升了3倍,模型迭代速度加快了50%。
隐私计算的“信任杠杆”:从“被动合规”到“主动创新”
2026年的工业领域,数据隐私已从“法律要求”升级为“核心竞争力”,以新能源汽车电池生产为例,每块电池的充放电数据都包含企业的核心工艺秘密,一旦泄露可能导致数十亿的市场损失,但与此同时,电池的寿命预测又需要整合多家供应商的数据——这种矛盾让许多企业陷入“想用数据又不敢用”的困境。
在江苏常州的一家动力电池企业,这种矛盾曾导致研发进度严重滞后。“我们需要供应商的电池使用数据来优化算法,但供应商担心我们‘偷师’,要么拒绝提供,要么只给脱敏后的无效数据。”该企业首席科学家王芳说,“最后我们只能用自己实验室的有限数据训练模型,结果预测误差高达25%。”
2026年,这家企业引入了联邦学习框架下的数字孪生系统,供应商的数据始终保留在本地服务器,仅通过安全多方计算(MPC)技术交换加密后的中间结果,更关键的是,系统设计了“数据使用追溯”功能:任何模型参数的变动都会留下不可篡改的日志,供应商可以随时审计数据使用情况。
“这种技术设计击中了供应商的心理痛点。”王芳说,“他们现在愿意提供更详细的数据,因为知道我们既拿不到原始数据,也无法篡改使用记录。”效果立竿见影:模型预测误差降至8%,研发周期缩短了6个月,更深远的影响是,供应商开始主动提出合作需求——他们发现,通过联邦学习参与模型训练,不仅能提升自身产品质量,还能获得行业前沿的算法反馈。 本月医疗健康与精准医疗领域迎来新发展,相关应用不断深化
这种“信任杠杆”效应在2026年的工业供应链中正在普及,在浙江宁波的服装产业集群,联邦学习被用于整合300家中小企业的生产数据,帮助龙头企业优化排产计划,参与企业从最初的12家增长到287家,关键原因就是“数据不出域”的承诺消除了他们的信任顾虑。
分布式协作的“心理赋能”:从“单打独斗”到“群体智慧”
工业数字孪生的终极目标,是构建一个“自感知、自决策、自优化”的智能系统,但要实现这一点,仅靠单个企业的数据远远不够——需要整合产业链上下游、甚至跨行业的数据,传统协作模式面临两个心理障碍:一是“贡献数据却得不到回报”的公平性担忧,二是“我的数据比别人差”的自卑心理。
在山东青岛的一家家电企业,这种心理障碍曾导致数字孪生项目差点夭折,2026年,该企业联合5家供应商启动了一个“智能冰箱能耗优化”项目,需要共享冰箱运行数据、压缩机性能数据、用户使用习惯数据等,但项目启动三个月后,仅有两家供应商提供了数据,且数据质量参差不齐。
“供应商A说‘我的压缩机效率最高,共享数据会暴露优势’;供应商B说‘我的数据质量差,共享了会被嘲笑’。”项目负责人张伟回忆道,“这种心理博弈让项目陷入僵局。”
联邦学习的分布式架构为解决这一问题提供了新思路,在该项目中,系统采用“差异化激励”机制:数据质量高的供应商获得的模型反馈更详细,数据贡献大的供应商在后续合作中享有优先权,更重要的是,系统通过差分隐私技术对数据进行扰动处理,确保任何单个数据点都无法被逆向识别。
“这种设计让供应商的心理发生了微妙变化。”张伟说,“供应商A发现,即使共享高效压缩机的数据,竞争对手也无法直接复制技术;供应商B则意识到,差分隐私保护了他们的‘数据面子’,同时还能从模型反馈中提升自身水平。”结果,项目在六个月内完成了数据整合,最终开发的智能算法使冰箱能耗降低了18%。
这种“心理赋能”效应在2026年的工业界正在催生新的协作模式,在广东深圳的3C电子产业带,200家中小企业通过联邦学习平台共享生产数据,共同训练了一个缺陷检测模型,参与企业从最初的“担心数据泄露”转变为“争抢数据贡献度”,因为系统会根据数据质量动态调整合作优先级——这种“数据贡献即价值”的机制,彻底激活了中小企业的协作意愿。
技术伦理的“心理底线”:从“野蛮生长”到“负责任创新”
工业数字孪生的快速发展,也带来了新的伦理挑战:算法偏见、数据歧视、模型失控等问题逐渐显现,2026年,一家欧洲汽车制造商的数字孪生系统因算法偏见引发争议:该系统在预测设备故障时,对来自发展中国家的供应商数据赋予了更低权重,导致这些供应商的订单被系统自动削减,事件曝光后,企业股价暴跌15%,CEO被迫辞职。
这一事件暴露了工业数字孪生的“心理底线”问题:当技术决策影响人类利益时,如何确保算法的公平性与透明性?联邦学习通过其分布式架构,为解决这一问题提供了技术伦理框架。 本月绿色城市与环保公益及电竞赛事热度持续上升,相关领域迎来新发展
在2026年的上海,一家跨国化工企业引入了“可解释联邦学习”系统,该系统在训练设备故障预测模型时,不仅输出预测结果,还生成“决策依据报告”,详细说明每个数据源对结果的贡献度,更重要的是,系统设计了“伦理审查模块”:任何涉及人类利益的决策(如订单分配、安全预警)都必须通过伦理委员会的审核,审核过程通过区块链技术永久记录。
“这种设计让员工和合作伙伴更信任系统。”该企业ESG负责人陈琳说,“以前他们觉得‘算法是黑箱,我们只能被动接受’,现在他们可以查看决策依据,甚至提出异议,这种透明性,消除了他们对技术失控的恐惧。”
这种“负责任创新”的心理需求在2026年的工业界日益强烈,在德国慕尼黑工业大学的最新研究中,83%的制造企业表示,他们更愿意采用“可解释、可审计、可干预”的联邦学习系统,即使这意味着牺牲部分模型性能。
心理驱动的技术进化
站在2026年的时间节点回望,工业数字孪生与联邦学习的结合,早已超越单纯的技术融合——它正在重塑工业领域的心理契约,从“不愿共享”到“主动协作”,从“被动合规”到“主动创新”,从“单打独斗”到“群体智慧”,从“野蛮生长”到“负责任创新”,联邦学习通过满足人类对安全、公平、透明的心理需求,成为推动