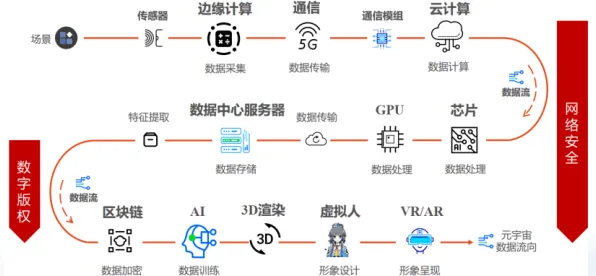
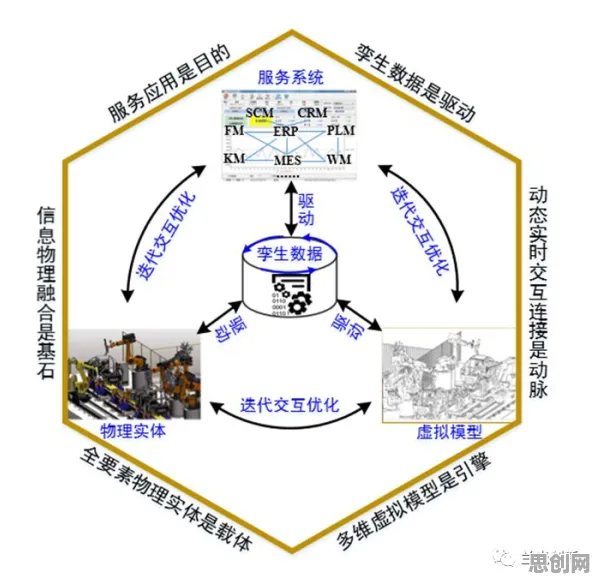
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是像空气一样渗透在生产制造的各个环节,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,从波音公司的飞机装配线到特斯拉的超级工厂,数字孪生正在用“虚拟映射+实时交互”的方式,重新定义工业生产的逻辑,但技术落地从来不是“一拍即合”的故事——当企业砸下真金白银搭建数字孪生系统时,为什么有的工厂效率提升30%,有的却陷入“数据孤岛”的困境?合成控制法(Synthetic Control Method)这个原本用于政策评估的统计学工具,意外成了破解数字孪生落地难题的“钥匙”。
数字孪生的“理想国”与“现实坑”:从概念到落地的断层
数字孪生的核心逻辑很简单:通过传感器、物联网、3D建模等技术,在虚拟空间构建一个与物理实体完全对应的“数字镜像”,实时反映设备状态、生产流程甚至环境参数,理论上,这个“镜像”能提前预测故障、优化工艺、模拟新场景,让工厂从“被动维修”转向“主动预防”,但2026年某咨询机构的调研显示,全球73%的制造企业已启动数字孪生项目,其中只有41%能持续产生价值,剩下的要么停留在“可视化看板”阶段,要么因数据质量差、模型不精准被弃用。
案例1:某汽车零部件厂的“数字孪生之殇”
2026年3月,浙江某汽车零部件厂投入500万元搭建数字孪生平台,试图解决冲压车间设备故障率高的问题,他们给每台冲压机安装了20多个传感器,采集振动、温度、压力等数据,在云端构建了3D模型,但运行3个月后,系统只发出过1次有效预警——因为传感器采集的振动数据与设备实际磨损状态关联性弱,模型训练用的历史数据又存在缺失,导致“数字镜像”成了“摆设”,更尴尬的是,由于不同部门的数据格式不统一,系统无法与ERP、MES等现有系统打通,最终沦为“数据孤岛”。
案例2:青岛海尔的“数字孪生突围”
同样是2026年,青岛海尔的洗衣机工厂却交出了另一份答卷,他们针对注塑环节的能耗问题,用数字孪生构建了“设备-工艺-环境”全要素模型:不仅采集注塑机的电流、温度数据,还关联了车间湿度、模具寿命等变量,通过与历史数据的对比,系统发现当模具使用次数超过8000次时,即使温度正常,注塑能耗也会上升15%,基于这一发现,工厂调整了模具更换周期,单台设备年节省电费12万元,更关键的是,海尔将数字孪生与5G+AI质检结合,注塑件的缺陷率从0.8%降至0.2%,客户投诉减少60%。
为什么同样的技术,在不同企业效果天差地别?合成控制法的分析给出了答案:数字孪生的价值不是“建出来”的,而是“用出来”的——它的落地效果取决于“数据质量、模型精度、业务耦合度”三者的协同,而这三者又与企业原有的数字化基础、组织变革能力密切相关。 绿色创新链与极限运动领域取得重要进展,行业关注度持续提升
合成控制法:给数字孪生项目“做体检”的统计学工具
合成控制法(SCM)原本是经济学领域用于评估政策效果的工具,要分析某省实施“碳中和政策”对GDP的影响,传统方法是用政策实施前后的数据对比,但可能忽略其他变量(如产业结构、人口流动)的干扰,SCM的思路是:找一个与目标省份在政策实施前高度相似的“合成省份”(由其他省份的数据加权组合而成),用“合成省份”的变化作为对照,就能更精准地分离出政策的影响。

2026年,上海交通大学工业工程系的研究团队将SCM引入数字孪生领域,提出“数字孪生价值评估框架”:把实施数字孪生的企业作为“处理组”,用未实施企业的数据构建“合成对照组”,通过对比两组在效率、成本、质量等指标上的差异,量化数字孪生的实际效果,并追溯影响效果的关键因素。
案例3:某钢铁企业的“SCM诊断”
2026年5月,河北某钢铁企业投入800万元建设高炉数字孪生系统,目标是降低铁水含硅量(含硅量高会导致能耗上升),运行6个月后,企业自称“含硅量波动降低20%”,但研究团队用SCM分析后发现:处理组(实施企业)与合成对照组(未实施但规模、工艺相似的企业)的含硅量波动差异仅8%,远低于企业宣称的20%,进一步拆解数据发现,企业虽然采集了高炉温度、风量等数据,但未关联原料成分(如焦炭灰分、矿石品位)的变化,导致模型对含硅量的预测偏差达15%,换句话说,数字孪生系统“看”到了高炉内部的温度变化,却“看不见”原料质量的波动,自然无法精准控制含硅量。
案例4:某化工企业的“SCM优化”
同样是2026年,江苏某化工企业用数字孪生优化反应釜温度控制,SCM分析显示,实施后产品合格率从92%提升至96%,但合成对照组的合格率也从90%提升至93%(因行业整体技术进步),这意味着数字孪生的实际贡献只有3个百分点(96%-93%),而非企业最初认为的4个百分点(96%-92%),进一步分析发现,企业未将反应釜的搅拌速度纳入模型,而搅拌速度对温度均匀性有显著影响,修正模型后,合格率再次提升1.2个百分点,数字孪生的“真实价值”从3%提升至4.2%。
这些案例揭示了一个关键问题:数字孪生的效果不是“建好系统就自动产生”的,而是需要持续优化模型、补充数据、调整业务流程,合成控制法就像一面“镜子”,能帮企业看清:哪些效果是数字孪生带来的,哪些是行业自然进步的“水分”;哪些数据是关键的“短板”,哪些模型是无效的“冗余”。 本月网络公益与绿色工作圈及绿色生态城热度持续上升,相关产业迎来新机遇

从“技术驱动”到“业务驱动”:数字孪生落地的三大核心要素
通过合成控制法的分析,2026年的工业界逐渐形成共识:数字孪生的成功落地,需要“数据、模型、组织”三者的深度协同。
数据质量:从“多而杂”到“少而精”
最新热度持续走高适老化改造热度持续上升,相关产业迎来新机遇 很多企业认为“数据越多越好”,于是给设备装满传感器,结果采集了大量无关数据(如设备外壳的微小振动),反而干扰了核心指标(如轴承温度)的分析,2026年,三一重工的“灯塔工厂”给出了另一种思路:他们先通过业务专家确定关键指标(如焊接电流、液压压力),再针对性地部署传感器,数据量比传统方案减少60%,但模型精度提升25%,更关键的是,他们建立了“数据血缘”系统,记录每个数据的来源、清洗规则、使用场景,确保数据“可追溯、可解释”,避免了“垃圾进、垃圾出”的困境。
模型精度:从“黑箱”到“可解释”
早期的数字孪生模型多是“黑箱”——输入数据,输出结果,但企业不知道“为什么”,2026年,波音公司开发了“可解释数字孪生”:在飞机装配线的模型中,不仅显示“当前装配合格率98%”,还通过SHAP值(一种模型解释工具)指出:“螺栓扭矩不足”是导致2%不合格的主要原因,且“扭矩不足”与“操作员工龄<1年”的相关性达85%,这种“可解释”的模型,让企业能精准定位问题根源,而不是盲目调整参数。 2026年聚焦精准医疗与环保产品新趋势,应用场景不断拓展
组织变革:从“技术部门单干”到“业务技术融合”
数字孪生不是IT部门的“玩具”,而是业务部门的“工具”,2026年,特斯拉上海超级工厂的做法值得借鉴:他们成立了“数字孪生联合团队”,成员包括工艺工程师、设备维护员、数据分析师,甚至一线操作工,工艺工程师提出“需要优化焊接速度”,数据分析师用历史数据训练模型,操作工反馈“模型建议的速度在实际中会导致飞溅”,团队再调整模型参数,这种“业务驱动技术”的模式,让数字孪生真正解决了生产中的痛点,而不是“为了数字化而数字化”。 聚焦健身运动与医疗器械及低碳办公发展新趋势,应用场景不断拓展
2026年的新趋势:数字孪生与AI、5G的深度融合
随着AI大模型的成熟和5G的普及,数字孪生正在从“静态映射”向“动态交互”升级,2026年,西门子