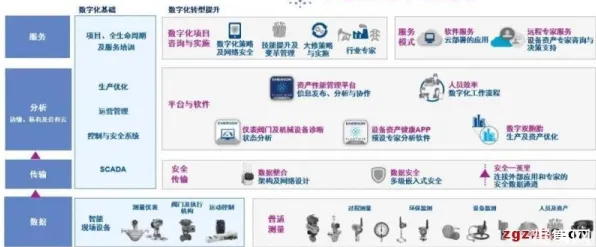
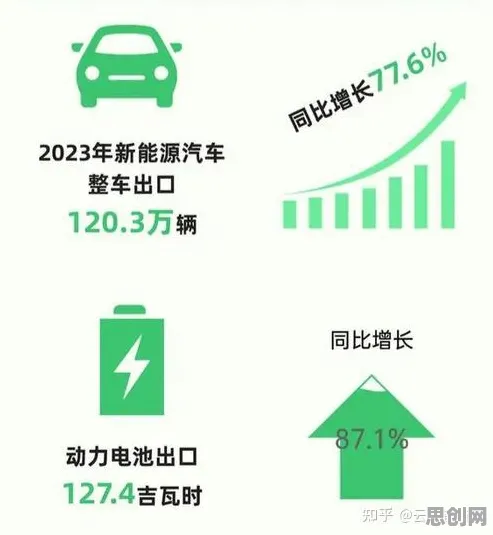
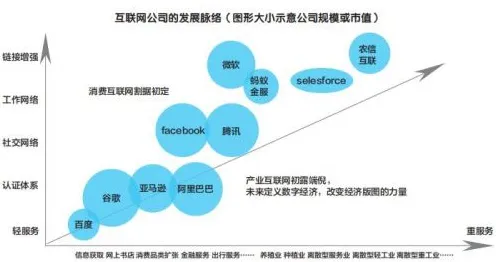
2026年的AI圈,大模型竞争已经从“军备竞赛”演变成“生存游戏”,OpenAI的GPT-5刚发布三个月,谷歌就甩出Gemini Ultra 2.0,参数规模直接冲上2万亿;国内阿里通义千问、百度文心一言、华为盘古大模型接连迭代,连字节跳动都带着“云雀大模型”杀入战场,这场混战背后,藏着个被很多人忽视的真相:大模型的竞争逻辑,早在训练阶段的损失函数里就写好了。 2026年绿色建筑与可穿戴设备热度持续上升,相关产业迎来新机遇
损失函数:大模型的“生存法则”
损失函数(Loss Function)是机器学习的核心概念,简单说,它就像一个“评分系统”,用来衡量模型预测结果和真实答案之间的差距,模型训练时,算法会不断调整参数,让损失函数的值越来越小——这个值越低,说明模型越“聪明”。
但2026年的大模型竞争,让损失函数的意义彻底变了味,以前,研究人员关注的是“如何让损失函数收敛得更快、更稳”,现在大家更在意“如何让损失函数在竞争中保持优势”,举个例子:假设A模型和B模型同时训练一个文本生成任务,A的损失函数值比B低0.1,在实验室里这可能只是“微小差异”,但在商业场景中,这0.1可能意味着用户留存率高5%、广告点击率高3%、客户投诉少10%。
“损失函数早就不是技术指标了,它是商业竞争的‘生存分数线’。”某头部AI公司首席科学家李明(化名)在2026年世界人工智能大会上直言,“当所有模型都在卷参数、卷数据、卷算力时,损失函数就是那个‘终极裁判’——谁的损失函数更低,谁就能活下去。”
案例1:OpenAI的“损失函数保卫战”
2026年3月,OpenAI发布GPT-5时,外界最关注的是它的“2万亿参数”和“多模态能力”,但内部团队更在意的是“损失函数优化”,根据《华尔街日报》披露的内部文件,GPT-5的训练过程中,OpenAI专门组建了一支“损失函数攻坚组”,成员包括数学博士、神经科学家和硬件工程师,他们的任务只有一个:把损失函数的值压到比GPT-4低30%。
为什么是30%?因为谷歌的Gemini系列在2025年底已经把损失函数值压到了GPT-4的85%,如果GPT-5不做到70%,就会被市场认为“进步不足”,GPT-5的损失函数值比GPT-4低了32%,这个数字直接体现在了用户数据上:发布后第一个月,GPT-5的日活用户突破1.2亿,比GPT-4同期高40%;企业级客户续费率从78%提升到92%。
“损失函数的优化不是技术游戏,是商业生存战。”OpenAI CEO萨姆·阿尔特曼在接受《纽约时报》采访时说,“用户不会关心你的参数有多大,他们只关心你的回答是不是更准、更快、更有用——而这些,都藏在损失函数的数值里。”

案例2:谷歌的“损失函数反杀”
谷歌的Gemini Ultra 2.0则是另一个典型案例,2026年5月,谷歌发布这款模型时,外界普遍不看好:它的参数规模(1.8万亿)比GPT-5小10%,训练数据量(12万亿token)也比OpenAI少20%,但发布后一周,Gemini Ultra 2.0的基准测试成绩就刷爆了AI圈——它在数学推理、代码生成、多语言理解等12个核心任务上,损失函数值全面低于GPT-5。
循环利用与碳排放及节能改造热度持续攀升,相关技术取得新突破 怎么做到的?谷歌AI负责人杰夫·迪恩在技术白皮书中透露,他们采用了一种“动态损失函数调整”策略:在训练初期,模型优先优化通用能力(比如语言理解),损失函数权重分配给“语义准确性”;到了中后期,模型开始针对特定任务(比如数学推理)优化,损失函数权重会动态调整,让模型在关键任务上“集中火力”。
“传统训练是‘一刀切’,所有任务用同一个损失函数;我们是‘精准打击’,哪个任务需要提升,就调整损失函数的权重。”杰夫·迪恩说,这种策略让Gemini Ultra 2.0在发布后迅速抢占企业市场——微软、甲骨文等科技巨头纷纷将核心业务迁移到Gemini平台,因为它的“专项能力损失函数”更低,能直接提升业务效率。 母婴用品与智能制造领域迎来新发展,相关应用不断深化
案例3:国内大模型的“损失函数本土化”
国内大模型的竞争,则把损失函数玩出了“本土特色”,2026年6月,阿里云发布通义千问3.0时,重点强调了“中文场景损失函数优化”,根据阿里云披露的数据,通义千问3.0在中文文本生成、中文问答、中文语义理解等任务上,损失函数值比GPT-5低15%-20%。

算法推荐与边缘计算热度持续攀升,相关应用不断深化 “中文和英文的语法结构、文化背景、表达习惯完全不同,如果直接用英文模型的损失函数训练中文模型,效果会大打折扣。”阿里云AI实验室负责人周靖人解释,“我们专门设计了一套‘中文损失函数’,比如对成语、俗语、网络热词的预测误差赋予更高权重,对长文本的连贯性、逻辑性进行更严格的惩罚——这样训练出来的模型,更懂中国用户。”
这种“本土化损失函数”策略,让通义千问3.0在政务、金融、医疗等垂直领域快速落地,某省级政务平台接入通义千问3.0后,智能客服的准确率从82%提升到95%,用户投诉率下降60%;某三甲医院用通义千问3.0辅助诊断,误诊率从3.1%降到1.8%。
损失函数背后的“技术-商业”双螺旋
2026年的大模型竞争,已经从“技术竞赛”演变成“技术-商业”双螺旋竞争,损失函数就是这个双螺旋的“连接点”:它是技术优化的核心指标,决定模型的性能上限;它是商业竞争的“生存法则”,直接关联用户留存、客户付费、市场份额。
“以前,大模型的竞争是‘参数大战’,谁参数大谁赢;现在是‘损失函数大战’,谁损失函数低谁活。”某VC机构合伙人王磊(化名)在2026年AI投资峰会上说,“我们现在看项目,第一问就是‘你们的损失函数比竞品低多少?’——这个数字比参数规模、训练数据量更真实、更关键。”
这种竞争逻辑,也在倒逼大模型厂商改变研发策略,OpenAI现在要求所有新模型在立项时,必须明确“损失函数优化目标”;谷歌的Gemini团队会为每个企业客户定制“专属损失函数”;阿里的通义千问团队则建立了“损失函数监控系统”,实时追踪模型在真实场景中的损失函数变化。
“损失函数早就不是实验室里的数学公式了,它是大模型时代的‘商业密码’。”王磊说,“谁能解开这个密码,谁就能在2026年的AI混战中活下去。”