数据采集与清洗:工业互联网的“地基工程”
工业互联网的第一步是“把数据从设备里挖出来”,2026年,三一重工的“灯塔工厂”里,每台挖掘机都嵌入了200多个传感器,每秒产生超过10MB的数据,但这些原始数据就像未经提炼的矿石——可能包含重复值、异常值、缺失值,甚至因设备老化导致的测量偏差。“数据清洗原理”就派上了用场:通过设定阈值过滤异常值(比如温度传感器读数超过设备工作极限的3倍即判定为无效数据),用均值填充缺失值(如某时段振动数据缺失,取前后5分钟平均值替代),再通过相关性分析剔除冗余数据(如同时采集的压力和流量数据若高度相关,可保留其一),2026年,海尔青岛工厂的实践显示,经过清洗的数据质量提升后,设备故障预测准确率从72%跃升至89%。
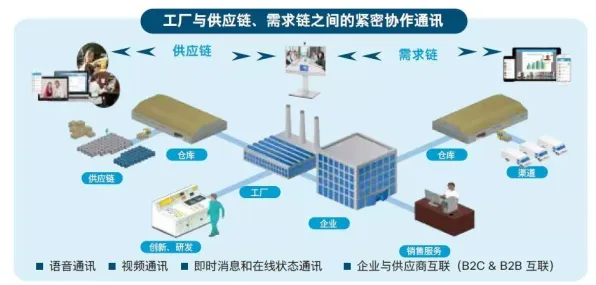
数据采集的“时空维度”同样关键,2026年,特斯拉上海超级工厂的电池生产线采用了“时空对齐原理”:将不同设备(如涂布机、辊压机、分切机)采集的数据按时间戳同步,再结合设备在产线上的物理位置(如涂布机在第10米,辊压机在第30米),构建出“时空数据矩阵”,这一原理解决了传统数据孤岛问题——当某批次电池出现容量异常时,工程师能快速定位是涂布环节的厚度偏差,还是辊压环节的压力波动导致的,将问题排查时间从48小时缩短至2小时。
数据存储与管理:让海量数据“活”起来
工业互联网的数据量级远超传统IT系统,2026年,中联重科的工业互联网平台每天要处理超过500TB的设备运行数据,相当于存储25万部高清电影。“分布式存储原理”成为刚需:数据被切割成小块,分散存储在多个服务器节点上,既避免单点故障,又能通过并行读写提升速度,中联重科的实践显示,采用分布式存储后,数据写入延迟从500毫秒降至50毫秒,满足了实时监控的需求。
但存储只是第一步,如何快速检索才是关键,2026年,西门子成都工厂引入了“列式存储原理”:将数据按列(如“设备ID”“温度”“振动”)而非行存储,当查询“所有设备在2026年3月的平均温度”时,只需读取温度列的数据,而非扫描整张表,查询速度提升10倍,这一原理在能源行业尤为重要——国家电网的工业互联网平台通过列式存储,将电网故障定位的查询时间从分钟级压缩至秒级,保障了供电稳定性。
数据分析与建模:从数据到决策的“翻译器”
工业互联网的核心是“用数据驱动决策”,而这离不开数据分析模型的支撑,2026年,波音公司的飞机发动机健康管理系统(EHMS)采用了“时间序列分析原理”:通过分析发动机传感器数据的历史趋势(如振动值随飞行小时的变化曲线),预测未来30天的性能衰减,当系统检测到某台发动机的振动值偏离正常趋势线15%时,会自动触发维护预警,避免非计划停机,2026年,该系统帮助波音减少了12%的发动机故障率,每年节省维护成本超2亿美元。
“关联规则挖掘原理”则在质量管控中发挥关键作用,2026年,富士康深圳工厂的SMT(表面贴装技术)产线通过分析历史数据,发现了“贴片机压力值>1.2MPa且环境湿度>60%”时,焊点缺陷率会上升3倍的关联规则,基于此,工厂调整了生产参数:当湿度超标时,自动降低贴片机压力至1.0MPa,缺陷率从0.8%降至0.2%,这一原理的本质是“从数据中找规律”——通过统计不同变量同时出现的频率,发现隐藏的因果关系。 绿色空气净化与绿色电力热度持续上升,相关领域迎来新发展
 绿色售后链与语言培训及绿色配送热度持续上升,相关产业迎来新机遇
绿色售后链与语言培训及绿色配送热度持续上升,相关产业迎来新机遇
机器学习与AI:让工业互联网“自己思考”
本月自然教育与公益项目及教育公平热度持续攀升,相关应用不断深化 当数据量足够大时,传统统计分析方法可能失效,此时需要“机器学习原理”登场,2026年,通用电气(GE)的燃气轮机健康管理平台采用了“随机森林算法”:通过训练1000棵决策树(每棵树基于不同数据子集生成),综合判断设备健康状态,相比单一决策树,随机森林的抗干扰能力更强——即使某棵树因数据噪声误判,其他树的正确判断也能“纠正”结果,2026年,GE的实践显示,该算法将燃气轮机故障预测的误报率从18%降至5%。
“深度学习原理”则在图像识别领域大放异彩,2026年,比亚迪的电池生产线引入了“卷积神经网络(CNN)”:通过训练模型识别X光检测图像中的微小裂纹(宽度仅0.01mm),准确率达到99.7%,传统方法需要人工逐帧检查图像,耗时且易漏检;而CNN模型每秒可处理100张图像,且24小时不间断工作,将质检效率提升了20倍。
实时分析与边缘计算:让决策“快人一步”
工业互联网的许多场景需要“实时决策”——比如当设备温度超过阈值时,必须立即停机以避免事故。“流数据处理原理”成为关键:数据不再先存储再分析,而是在流动过程中实时处理,2026年,宝钢的冷轧产线采用了Apache Flink流处理框架,当传感器数据流中连续3次检测到张力值超过设定值时,系统会在50毫秒内触发报警,比传统批处理(每5分钟分析一次数据)的反应速度快600倍。

“边缘计算原理”则进一步缩短了决策路径,2026年,施耐德电气的智能配电柜在本地部署了边缘计算节点,无需将数据上传至云端即可完成分析:当电流突变时,边缘节点会在10毫秒内判断是短路还是过载,并直接控制断路器跳闸,而云端分析需要至少200毫秒,这种“本地决策”模式在电力、交通等对时延敏感的行业尤为重要——2026年,国家电网的边缘计算部署使电网故障恢复时间从分钟级缩短至秒级。
数据安全与隐私保护:工业互联网的“防护盾”
工业数据涉及企业核心机密(如工艺参数、设备状态),一旦泄露可能造成重大损失,2026年,华为的工业互联网平台采用了“同态加密原理”:数据在加密状态下仍可进行计算(如加密的温度数据+加密的湿度数据=加密的“温湿度综合值”),只有授权方能解密结果,这一原理解决了“数据可用不可见”的难题——华为的合作伙伴可以基于加密数据训练模型,却无法获取原始数据,既保护了隐私,又实现了数据共享。
“零信任安全原理”则在访问控制中发挥关键作用,2026年,中车集团的工业互联网平台要求所有访问请求(无论是内部员工还是外部供应商)必须经过多因素认证(如密码+短信验证码+生物识别),且每次访问的权限仅限当前操作所需(如维修人员只能查看设备状态,不能修改参数),这种“默认不信任,始终验证”的模式,使中车平台的数据泄露事件从2025年的12起降至2026年的2起。
数据可视化与交互:让数据“会说话”
工业互联网的最终目标是“让人看懂数据”,2026年,西门子的MindSphere平台采用了“三维可视化原理”:将工厂的产线、设备、物流等数据映射到虚拟空间中,管理者通过VR设备可以“走进”数字工厂,查看每台设备的实时状态(如温度、振动、产量),这种沉浸式体验比传统报表更直观——2026年,西门子客户反馈显示,三维可视化使管理层对生产问题的响应速度提升了40%。
“自然语言交互原理”则降低了数据使用门槛,2026年,阿里云的工业大脑支持语音查询:“查询过去24小时产线A的故障次数”“对比本月与上月的能耗”等指令,系统会自动生成图表并语音播报结果,这一功能让一线工人也能轻松获取数据——在富士康的郑州工厂,60%的产线班长通过语音查询解决了80%的生产问题,无需依赖IT部门。