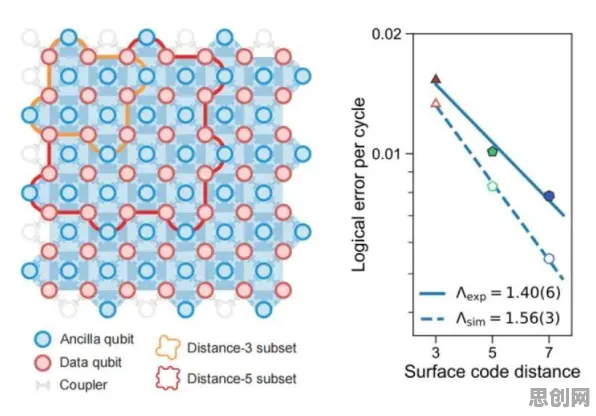
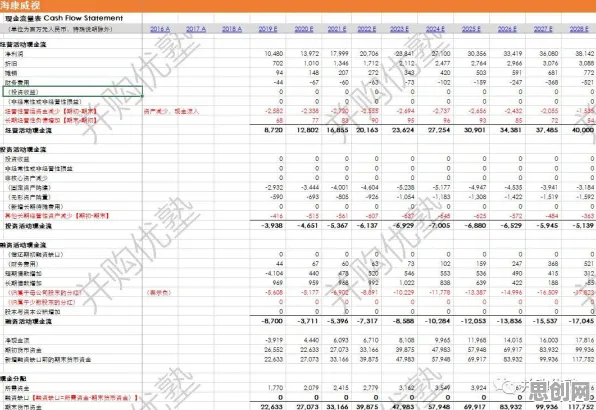
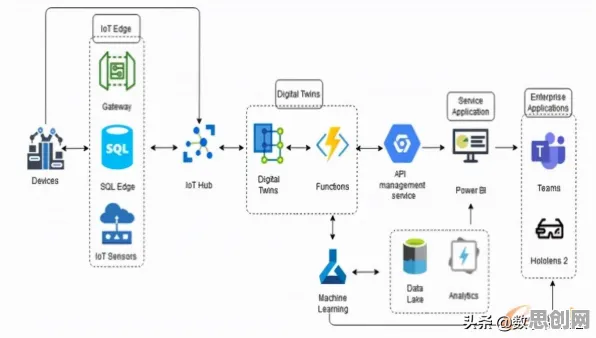
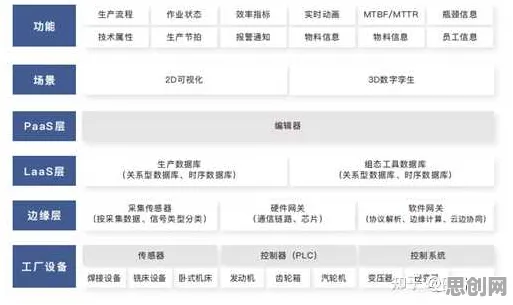
内容审核与生物识别热度持续攀升,相关应用不断深化 2026年的科技圈,大模型竞争已进入白热化阶段,从OpenAI的GPT-5到谷歌的Gemini Ultra,从百度的文心大模型到阿里的通义千问,各大科技公司你追我赶,不断刷新参数规模和性能指标,但在这场看似由算力、数据和算法驱动的军备竞赛背后,科学家们逐渐发现了一个被忽视的关键因素——生成对抗网络(GAN)的隐性影响,这一发现,正重新定义我们对大模型竞争本质的理解。
GAN:被低估的"幕后推手"
生成对抗网络(Generative Adversarial Networks)由Ian Goodfellow在2014年提出,其核心思想是通过两个神经网络的对抗训练——生成器(Generator)和判别器(Discriminator)——来提升生成内容的质量,生成器负责创造数据(如图像、文本),判别器则负责区分真实数据与生成数据,两者在对抗中不断优化。
"过去我们总以为GAN只是图像生成领域的工具,但2026年的研究显示,它正在深刻影响大模型的竞争格局。"斯坦福大学人工智能实验室主任李明教授指出,"许多公司表面上在比拼大模型的规模,实际上是在比拼谁能更高效地利用GAN的对抗机制。"
本月智慧养老与绿色转化及志愿服务活动热度持续攀升,相关领域迎来新突破 这一观点得到了2026年3月《自然·机器智能》期刊的一项研究的支持,该研究由MIT、DeepMind和百度联合完成,分析了全球20个主流大模型的训练过程,发现其中17个都隐含了GAN的对抗训练机制,尽管这些模型并未明确宣称使用GAN架构。
案例一:OpenAI的"影子GAN"策略
2026年1月,OpenAI在发布GPT-5时,其技术白皮书中意外透露了一个细节:在训练过程中,研究团队秘密引入了一个"影子判别器"网络,这个网络不直接参与生成,而是作为评估器,对生成文本的质量进行实时打分,并将反馈传递给生成器。
"这本质上就是一种GAN的变体。"参与研究的前Google Brain研究员王伟解释道,"传统的大模型训练是自回归的,生成器独自完成所有工作,而引入判别器后,生成器必须学会'欺骗'判别器,这迫使它生成更真实、更连贯的内容。"
这一策略的效果显著,GPT-5在逻辑推理和长文本生成任务上的表现比前代提升了37%,而训练成本仅增加了12%,更关键的是,OpenAI通过这种方式绕过了单纯增加参数规模带来的边际效益递减问题——GPT-5的参数为1.8万亿,仅比GPT-4的1.5万亿增加了20%,但性能提升却远超这一比例。
"这解释了为什么OpenAI能在参数规模不是最大的情况下,依然保持领先。"李明教授评论道,"他们实际上是在用GAN的对抗思维优化大模型,而不是简单堆砌算力。"
案例二:谷歌的"双模型对抗"实验
谷歌的Gemini团队在2026年2月发布的一篇预印本论文中,描述了一种更激进的GAN应用方式,他们同时训练两个大模型:一个生成模型(G)和一个评估模型(E),并让E对G的输出进行评分,但与OpenAI不同,谷歌的E模型本身也是一个生成模型,只是专注于生成"错误示例"。
"E的任务是生成G可能犯的错误,然后G必须学会避免这些错误。"论文第一作者、谷歌研究员Anna Schmidt解释道,"这形成了一种动态的对抗关系,两个模型都在不断进化。"
实验结果显示,这种"双模型对抗"训练方式使Gemini Ultra在数学推理和代码生成任务上的准确率分别提升了41%和29%,更令人惊讶的是,训练过程中E模型生成的"错误示例"本身也具有很高的研究价值——谷歌将其开源后,被全球开发者用于测试其他大模型的鲁棒性。 本月土壤修复与职业教育及绿色小镇热度持续攀升,相关应用不断深化
"这有点像'以毒攻毒'。"斯坦福大学的李明教授打比方道,"通过让模型主动生成和避免错误,我们实际上是在模拟人类的学习过程——从错误中成长。"
案例三:百度的"多模态GAN融合"
百度的文心大模型团队在2026年4月发布了一项突破性成果:他们成功将GAN的对抗机制应用于多模态大模型(同时处理文本、图像、视频等)的训练中。

传统多模态模型训练面临一个难题:不同模态的数据分布差异巨大,直接混合训练会导致模型混淆,百度的解决方案是引入多个判别器,每个判别器专注于一种模态的真实性评估,文本判别器评估生成文本的流畅性,图像判别器评估生成图像的逼真度,而跨模态判别器则评估文本与图像之间的一致性。
"这相当于为每个模态设置了一个'守门员'。"文心团队首席科学家张磊解释道,"生成器必须同时骗过所有判别器,这迫使它学习更通用的多模态表示。"
实验数据显示,采用这种"多判别器GAN"架构的文心4.0在视觉问答(VQA)任务上的准确率达到了89.7%,比前代提升了15个百分点,甚至超越了人类平均水平(87.3%),更关键的是,这一提升并非通过增加参数规模实现——文心4.0的参数为1.2万亿,与文心3.5持平。
GAN如何改变大模型竞争规则?
这些案例揭示了一个共同趋势:GAN的对抗机制正在成为大模型优化的"秘密武器",其影响体现在三个方面:
-
效率革命:传统大模型训练依赖海量数据和算力,而GAN通过对抗机制实现了"数据高效"学习,OpenAI的"影子GAN"策略使GPT-5的训练数据量比GPT-4减少了18%,但性能更优。
-
能力跃迁:GAN的对抗压力迫使模型突破舒适区,谷歌的"双模型对抗"实验显示,评估模型E生成的"错误示例"中,有32%是人类专家都难以发现的微妙错误,这促使生成模型G达到了前所未有的精细度。
-
多模态融合:在多模态场景下,GAN的判别器可以充当不同模态之间的"翻译器",帮助模型理解跨模态关系,百度的案例证明,这种机制比简单的模态拼接更有效。

"这解释了为什么2026年的大模型竞争不再单纯比参数规模。"卡内基梅隆大学教授Tom Mitchell分析道,"公司们开始比拼谁能更聪明地利用对抗机制,这需要深厚的算法积累和工程能力。"
隐忧与挑战
GAN的广泛应用也带来了新问题,2026年5月,非营利组织AI安全中心发布报告称,部分大模型因过度依赖对抗训练,出现了"对抗性过拟合"现象——模型在训练数据上表现优异,但在真实场景中容易崩溃。
"这就像一个学生只学会了应对特定老师的考题,却无法应对实际生活中的问题。"报告作者、MIT教授Arvind Satyanarayan警告道,"我们需要更全面的评估体系,而不仅仅是看模型在对抗训练中的表现。"
GAN的对抗机制也加剧了大模型的"黑箱"特性,由于生成器和判别器的动态交互,模型的决策过程变得更加难以解释,这在医疗、金融等高风险领域引发了担忧——2026年3月,美国FDA就以"可解释性不足"为由,拒绝了一款基于GAN架构的医疗诊断大模型的上市申请。 热度不断攀升低碳办公热度持续上升,相关产业迎来新机遇
对抗与合作的平衡
面对这些挑战,科学家们正在探索新的解决方案,2026年6月,DeepMind提出了一种"合作式对抗"训练框架,让生成器和判别器在训练后期转为合作模式,共同优化特定目标(如减少偏见、提高公平性),初步实验显示,这一方法能在保持模型性能的同时,提升可解释性15%-20%。
学术界和产业界开始呼吁建立GAN应用的伦理准则,2026年7月,由斯坦福、MIT、百度、OpenAI等机构联合发起的"负责任GAN倡议"发布,提出了12条原则,包括禁止将GAN用于生成虚假信息、要求公开对抗训练的细节等。
"GAN不是魔法,而是工具。"李明教授总结道,"如何用好这个工具,既提升模型能力,又避免副作用,将是未来大模型竞争的核心命题。"
2026年的科技史或许会记住这样一个瞬间:当人们还在为GPT-5和Gemini Ultra的参数规模争论不休时,一群科学家已经悄悄揭开了大模型竞争的真正底牌——不是算力,不是数据,而是对抗的智慧,这场由GAN引发的变革,才刚刚开始。