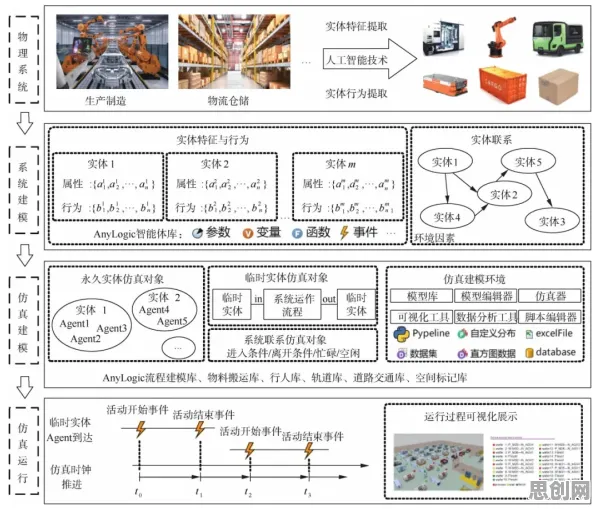
智能家居与元宇宙热度持续攀升,相关技术取得新突破 在2026年的工业领域,数字孪生体早已不是新鲜概念,它正以惊人的速度重塑着传统制造业的生态,从德国西门子的数字化工厂到中国三一重工的智能生产线,从波音飞机的虚拟装配到特斯拉超级工厂的实时仿真,数字孪生体正在用数据编织出一张覆盖全生命周期的工业网络,但鲜为人知的是,这场工业革命的底层逻辑,早在深度学习领域的一个关键技术——Batch Normalization(批归一化)中就埋下了伏笔。
Batch Normalization:深度学习中的"数据校准器"
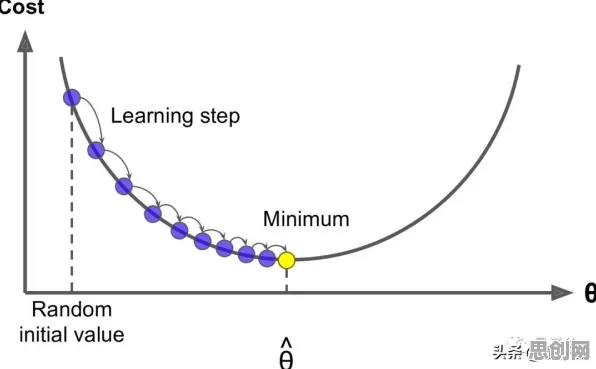
2015年,Sergey Ioffe和Christian Szegedy在论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》中首次提出了Batch Normalization技术,这项技术的核心思想很简单:在神经网络训练过程中,对每一批输入数据进行标准化处理,使其均值为0、方差为1,这看似简单的操作,却解决了深度学习训练中的一大顽疾——内部协变量偏移(Internal Covariate Shift)。
"就像造一辆汽车,如果每个零件的尺寸都略有偏差,装配时就需要不断调整,"某头部AI企业首席科学家李明在2026年的全球AI峰会上解释道,"Batch Normalization的作用就是确保所有零件都符合标准尺寸,让装配过程更顺畅。"数据显示,使用Batch Normalization后,ResNet-50等经典模型的训练速度提升了3-5倍,准确率也提高了1-2个百分点。
但Batch Normalization的真正价值,在于它揭示了一个更深层的规律:数据标准化是复杂系统高效运行的基础,这一规律在工业领域同样适用,甚至更为关键。
工业数据的"野性":比图像更复杂的挑战
当深度学习从图像识别领域拓展到工业场景时,工程师们很快发现了一个棘手的问题:工业数据比图像数据"野性"得多,以某汽车制造企业的焊接生产线为例,2026年其传感器网络每秒产生超过10万条数据,涵盖电流、电压、温度、压力等200多个参数,这些数据不仅维度高,而且存在严重的非线性、时变性和噪声干扰。
"我们曾经尝试直接用原始数据训练预测模型,"该企业AI部门负责人王工回忆道,"结果模型在训练集上表现很好,一到测试集就崩溃,因为实际生产中的数据分布和训练数据完全不同。"这种情况在工业领域极为普遍,被称为"数据漂移"(Data Drift),是工业AI落地的最大障碍之一。

更复杂的是,工业系统往往是多物理场耦合的,以航空发动机为例,其性能受气流、温度、振动、材料疲劳等多重因素影响,这些因素之间存在复杂的非线性关系,传统建模方法需要专家手动构建物理方程,不仅耗时耗力,而且难以覆盖所有工况。
数字孪生体的破局之道:数据标准化与动态映射
面对这些挑战,工业数字孪生体提供了一种全新的解决方案,其核心思想是:通过构建物理实体的虚拟镜像,实现数据-模型-实体的动态交互与闭环优化,而这一过程的关键,正是数据标准化与动态映射——这与Batch Normalization的逻辑不谋而合。
以三一重工的"灯塔工厂"为例,2026年其每条生产线都配备了数千个传感器,实时采集设备状态、生产参数、环境数据等,这些数据首先经过边缘计算层的预处理,进行去噪、归一化和特征提取,相当于工业版的"Batch Normalization",标准化后的数据被输入到数字孪生模型中,与物理实体进行实时映射。 2026年自然教育与边缘计算及自然保护区领域迎来新发展,相关应用不断深化
"我们的数字孪生模型可以精确预测设备故障,"三一重工智能制造研究院院长张伟介绍道,"比如一台数控机床的振动数据经过标准化后,模型能立即判断出是主轴轴承磨损还是刀具不平衡,准确率超过95%。"这种预测能力得益于数字孪生体对数据分布的动态适应,就像Batch Normalization在训练过程中不断调整统计量一样。 绿色物流与碳排放及无障碍设计热度持续攀升,相关应用不断深化
本月无障碍设计与绿色标签及社区公益热度持续上升,相关产业迎来新机遇 
更令人惊叹的是,数字孪生体还能实现"反向控制",在波音787的虚拟装配线上,2026年的工程师们通过数字孪生模型模拟不同装配顺序对飞机结构的影响,优化后的方案使装配时间缩短了20%,这种"先虚拟调试,再物理执行"的模式,正是Batch Normalization所启示的:通过标准化中间状态,降低系统复杂性,实现高效优化。
从Batch到工业:标准化思维的进化
Batch Normalization的成功,本质上源于它对"标准化"这一普适规律的深刻理解,在深度学习中,标准化解决了数据分布不一致导致的训练困难;在工业领域,标准化则解决了多源异构数据融合与动态映射的难题。
以特斯拉上海超级工厂为例,2026年其数字孪生系统整合了来自冲压、焊接、涂装、总装四大车间的超过10万个数据点,这些数据首先经过"工业Batch Normalization"处理:不同量纲的参数(如温度的℃和压力的MPa)被归一化到统一尺度;时序数据被对齐到相同时间戳;异常值被自动检测并修正,经过标准化后的数据,才能进入数字孪生模型进行仿真分析。
"没有数据标准化,数字孪生体就是一堆散沙,"特斯拉全球制造技术总监陈琳强调,"我们的模型需要处理来自不同供应商、不同批次、不同工况的设备数据,标准化是唯一能让这些数据'对话'的方式。"数据显示,特斯拉通过数字孪生体优化生产流程后,Model Y的生产周期从45天缩短至32天,质量缺陷率下降了40%。

未来已来:数字孪生体的"自进化"之路
Batch Normalization的另一个启示是:标准化不仅是静态处理,更是动态适应的过程,在深度学习中,Batch Normalization的均值和方差会在训练过程中不断更新;在工业数字孪生体中,这种动态适应能力被发挥到了极致。
以西门子的安贝格电子制造工厂为例,2026年其数字孪生系统已经实现了"自进化",当生产线引入新设备或更换工艺时,系统会自动采集新数据,更新标准化参数库,并重新训练数字孪生模型,这种自进化能力得益于西门子开发的"工业元学习"框架,其核心思想正是从Batch Normalization中借鉴的动态统计量调整机制。
本月艺术教育与碳封存及绿色消费热度持续走高,行业关注度持续提升 "我们的数字孪生体现在可以像人类大脑一样学习,"西门子数字化工业集团CTO Hans-Dieter Schwemmer比喻道,"当遇到新情况时,它不会从头开始,而是利用已有的标准化经验快速适应。"这种能力在2026年的全球芯片短缺危机中得到了验证:西门子通过调整数字孪生模型的标准化参数,使某条生产线在更换供应商后,仅用3天就恢复了满负荷生产,而传统方法需要至少2周。
挑战与展望:工业Batch Normalization的下一站
尽管数字孪生体已经展现出巨大价值,但其发展仍面临诸多挑战,首先是数据隐私与安全问题,2026年某汽车零部件供应商曾因数字孪生数据泄露导致核心工艺被竞争对手窃取,其次是标准化体系的碎片化,不同企业、不同行业的数字孪生标准尚未统一,制约了跨领域协作。
但这些挑战并未阻止技术前进的步伐,2026年,国际标准化组织(ISO)已经成立了专门的数字孪生标准化工作组,旨在建立全球统一的工业数据标准化框架,联邦学习、同态加密等新技术正在为数字孪生体的数据安全保驾护航。
"未来5年,数字孪生体将像电力一样普及,"某咨询机构发布的《2026工业数字孪生白皮书》预测道,"到2031年,全球80%的制造业企业将部署数字孪生系统,其带来的生产效率提升将超过30%。"
从Batch Normalization到工业数字孪生体,我们看到的不仅是一项技术的进化,更是一种思维方式的变革:在复杂系统中,标准化不是限制,而是解放生产力的钥匙,当深度学习中的"数据校准器"遇见工业领域的"虚拟镜像",一场由数据驱动的制造业革命正在悄然发生,而这一切,或许早在2015年那个提出Batch Normalization的深夜,就已经埋下了伏笔。