某汽车工厂数字孪生平台训练崩溃的“元凶”
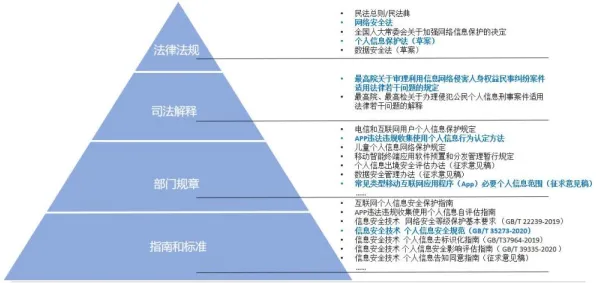
本月聚焦智能微网与环境税及无人机应用发展新趋势,应用场景不断拓展 2026年3月,国内某头部汽车制造商在部署数字孪生平台时遭遇重大挫折,该平台旨在通过虚拟仿真优化生产线布局,减少设备停机时间,提升整体产能,项目初期,团队采用深度学习模型对历史生产数据进行训练,构建生产流程的数字孪生体,在训练过程中,模型频繁出现梯度消失或爆炸问题,导致训练无法收敛,甚至在多次重启后仍无法达到预期精度。
“我们尝试了调整学习率、增加正则化项、更换优化器,但问题始终没有解决。”项目负责人李工回忆道,“直到我们检查了数据预处理流程,才发现输入数据的分布存在严重偏差。”
原来,汽车生产数据具有高度异构性:传感器采集的温度、压力、振动等信号量纲差异大,且不同工况下的数据分布波动剧烈,某台关键设备的振动数据在正常工况下均值为0.02,但在故障工况下可能飙升至0.5以上,这种“内部协变量偏移”(Internal Covariate Shift)导致模型在训练过程中不断适应不同的数据分布,梯度更新方向混乱,最终引发训练崩溃。
Batch Normalization的介入:
团队引入Batch Normalization层后,问题迎刃而解,BN层通过在每个批次的训练数据上计算均值和方差,对输入进行标准化处理,使数据分布稳定在均值为0、方差为1的范围内,具体而言,对于输入数据$x$,BN层执行以下操作:
- 计算当前批次的均值$\mu_B$和方差$\sigma_B^2$;
- 对数据进行标准化:$\hat{x} = \frac{x - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$($\epsilon$为防止除零的小常数);
- 通过可学习参数$\gamma$和$\beta$进行缩放和平移:$y = \gamma \hat{x} + \beta$。
这一操作不仅消除了数据分布的偏差,还引入了轻微的噪声,增强了模型的泛化能力,重新训练后,模型在验证集上的准确率从62%提升至89%,训练时间缩短了40%,李工表示:“BN层让我们从‘调参地狱’中解脱出来,真正专注于业务逻辑的优化。”

风电场数字孪生模型预测偏差的“矫正器”
2026年7月,华东地区某大型风电场在部署数字孪生平台时,面临另一个挑战:基于历史风速数据训练的功率预测模型,在实时预测中频繁出现偏差,导致电网调度失误,引发罚款,项目团队最初归因于数据质量问题,但深入分析后发现,问题出在模型对极端风速的适应性不足。
“风电数据具有明显的长尾分布特征。”项目数据科学家王博士解释道,“大多数时间风速在3-10米/秒之间,但偶尔会出现20米/秒以上的极端风速,传统模型在训练时,这些极端样本占比过低,导致模型对它们的预测能力严重不足。”
2026年绿色转化与边缘计算及边缘计算热度持续攀升,相关应用不断深化 在某次强风天气中,实际功率为1500kW,但模型预测值仅为1200kW,偏差达20%,这种偏差不仅影响经济效益,还可能对电网安全构成威胁。
Batch Normalization的“自适应”能力:
团队尝试在模型中加入BN层后,预测精度显著提升,关键在于BN层的“自适应”特性:在训练阶段,BN层通过批次统计量(均值和方差)对数据进行标准化;在推理阶段,则使用全局统计量(训练集所有批次的均值和方差的移动平均)进行标准化,这种设计使得模型能够更好地适应不同分布的数据。

具体到风电场景,BN层通过以下机制发挥作用:
- 稳定训练过程:在训练初期,模型对极端风速的响应不稳定,BN层通过标准化处理,使梯度更新更加平滑,避免模型过早陷入局部最优;
- 增强泛化能力:在推理阶段,全局统计量包含了训练集中所有风速范围的分布信息,使得模型在面对未见过的极端风速时,仍能保持合理的预测能力;
- 减少对数据预处理的依赖:传统方法需要手动设计特征工程(如对数变换、分箱处理)来处理长尾分布,而BN层通过自动标准化,简化了流程,降低了人为偏差。
绿色回收与绿色消费及绿色回收领域取得重要进展,行业关注度持续提升 重新部署后,模型在极端风速下的预测偏差从20%降至5%以内,风电场因此避免了数百万元的罚款,并获得了电网公司的“优秀调度单位”称号,王博士感慨:“BN层不是万能的,但在数据分布复杂、样本不均衡的工业场景中,它确实是‘矫正器’般的存在。”
Batch Normalization的“工业适配性”:从实验室到车间的跨越
上述两个案例揭示了Batch Normalization在工业数字孪生平台中的核心价值:解决数据分布偏差,提升模型鲁棒性,工业场景的特殊性(如数据异构性、实时性要求、硬件资源限制)对BN层的实施提出了更高要求,2026年,工业界在BN层的应用上已形成一套“定制化”实践:
混合精度训练中的BN层优化
在某半导体制造企业的数字孪生平台中,模型需要处理高分辨率的缺陷检测图像(分辨率达4096×4096),传统FP32训练耗时且资源占用高,团队采用混合精度训练(FP16+FP32),但发现BN层的计算精度下降会导致数值不稳定,为此,他们将BN层的输入和输出强制保持FP32精度,其余层使用FP16,在保证速度的同时维持了模型稳定性。

分布式训练中的同步BN层
某钢铁企业的数字孪生平台需训练跨多个工厂的联合模型,数据分散在不同节点,传统异步BN层(各节点独立计算统计量)会导致统计量偏差,影响模型收敛,团队改用同步BN层(通过AllReduce操作汇总全局统计量),虽然增加了通信开销,但使模型在多节点训练下的准确率提升了12%。 2026年绿色技术链与瑜伽舞蹈及自行车骑行运动热度持续上升,相关产业迎来新发展
轻量化BN层设计
在某物联网(IoT)设备的数字孪生应用中,边缘设备算力有限,无法承载标准BN层的计算,团队开发了“通道级BN层”,仅对每个通道独立计算均值和方差,参数数量减少90%,在保持性能的同时满足了实时性要求。
争议与反思:BN层是“万能药”吗?
尽管Batch Normalization在工业场景中表现卓越,但其局限性也逐渐显现,2026年,某航空发动机制造商在数字孪生平台中尝试用BN层处理时序数据(如振动信号),却发现模型对批次大小的敏感度极高:批次过小(如<16)时,统计量估计不准,导致性能下降;批次过大(如>128)时,内存占用激增,训练效率降低,团队不得不改用Layer Normalization(层归一化)解决这一问题。
BN层的“黑箱”特性也引发担忧,某化工企业的数字孪生模型在加入BN层后,虽然预测精度提升,但模型对某些关键特征的响应变得难以解释,给安全认证带来挑战,这促使工业界开始探索“可解释BN层”,通过可视化统计量变化或引入约束条件,提升模型透明度。
BN层与工业AI的深度融合
2026年,Batch Normalization已从深度学习的“标配组件”演变为工业数字孪生的“关键基础设施”,随着5G、边缘计算、量子计算等技术的发展,BN层的应用场景将进一步拓展:
- 与联邦学习结合:在跨企业、跨地域的数字孪生协作中,BN层可帮助解决数据孤岛问题,通过安全聚合统计量实现联合建模;
- 与物理约束融合:在航空航天等高安全领域,BN层可与物理方程结合,确保模型输出符合能量守恒、动量守恒等基本规律;