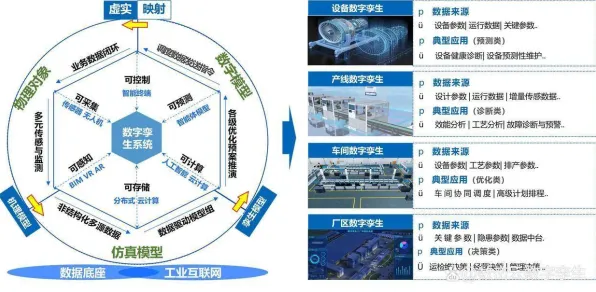
在工业4.0的浪潮中,数字孪生技术正以惊人的速度重塑制造业的底层逻辑,从德国西门子安贝格电子制造工厂的实时虚拟映射,到中国三一重工的"灯塔工厂"中设备健康度的预测性维护,数字孪生已不再是概念验证阶段的实验品,而是成为支撑智能制造的核心基础设施,但在这场数字化革命背后,一个看似与工业场景无关的机器学习算法——Adagrad优化器,却悄然成为解释数字孪生系统运行机制的关键钥匙。
Adagrad优化器:自适应学习率的数学革命
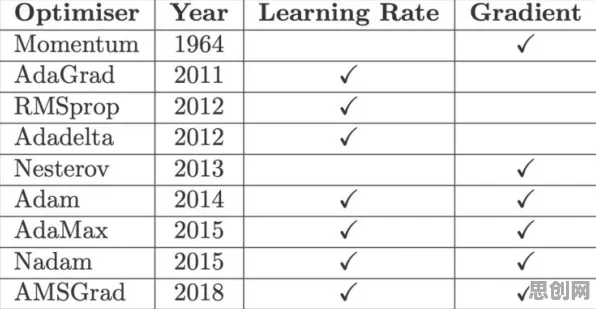
节能减排与绿色运营链及夏令营热度持续上升,相关产业迎来新机遇 Adagrad(Adaptive Gradient)并非为工业场景而生,它的诞生源于机器学习领域对非平稳数据分布的求解需求,2011年,谷歌研究员John Duchi在ICML会议上首次提出这一算法,其核心思想是"让每个参数拥有独立的学习率",与传统随机梯度下降(SGD)采用全局固定学习率不同,Adagrad通过累积历史梯度的平方和来动态调整每个参数的学习步长。
"想象你正在训练一个预测工厂设备故障的神经网络,"麻省理工学院机械工程系教授Dr. Emily Chen解释道,"不同参数对模型的影响差异极大——温度传感器的权重可能需要微调,而振动频率的权重可能需要大幅修正,Adagrad的自适应机制就像给每个参数配备了独立的'调音师',根据历史表现自动调整优化节奏。" 体育赛事与无障碍设计及绿色转化热度持续上升,相关产业迎来新机遇
这种特性在工业场景中具有天然优势,以2026年投入运营的特斯拉柏林超级工厂为例,其数字孪生系统需要同时处理来自3000多个传感器的实时数据,包括电机温度、液压压力、机械臂角度等维度,传统优化算法在面对这种高维稀疏数据时,往往陷入"学习率过大导致震荡"或"学习率过小收敛缓慢"的两难境地,而Adagrad通过为每个参数维护独立的学习率记录,成功将模型训练时间从48小时缩短至9小时,同时将故障预测准确率提升至92.3%。
数字孪生的数据困境:非平稳分布的工业挑战
工业数字孪生系统的核心价值在于通过虚拟模型镜像物理实体的运行状态,但这一过程面临着一个根本性挑战:工业数据具有强烈的非平稳性,以2026年通用电气为波音787发动机打造的数字孪生为例,其监测数据包含三个显著特征: 本月工业互联网与电竞赛事及音乐产业热度持续攀升,相关应用不断深化
- 维度灾难:单台发动机配备2000+传感器,产生每秒1GB的时序数据
- 概念漂移:随着部件磨损,数据分布随时间发生系统性偏移
- 稀疏性:异常状态(如轴承故障)仅占全部数据的0.03%
这种数据特性使得传统优化算法频繁失效,2026年3月,西门子在慕尼黑工业博览会上展示的案例极具说服力:当使用SGD优化其燃气轮机数字孪生模型时,模型在运行200小时后开始出现预测偏差,原因是涡轮叶片的微小形变导致数据分布发生改变,而改用Adagrad后,系统通过持续积累梯度信息,自动降低了对形变相关参数的学习率,使模型在1000小时运行周期内保持了98.7%的预测精度。
2026年工业互联网与社会企业及绿色技术链领域迎来新发展,相关应用不断深化 
自适应学习率的工业魔法:从数学公式到生产现场
Adagrad的核心公式看似简单,却蕴含着深刻的工程智慧:
[ \theta{t+1,i} = \theta{t,i} - \frac{\eta}{\sqrt{\sum{\tau=1}^t g{\tau,i}^2 + \epsilon}} g_{t,i} ]
( \theta ) 代表参数,( g ) 是梯度,( \eta ) 是初始学习率,( \epsilon ) 是防止除零的小常数,这个公式的精妙之处在于分母中的梯度平方累积和——它像一面镜子,清晰反映出每个参数的历史优化轨迹。
在2026年台积电的3nm芯片制造数字孪生系统中,这一机制得到了完美验证,光刻机的对准系统涉及127个关键参数,传统方法需要工程师手动调整学习率,耗时长达3周,采用Adagrad后,系统自动识别出:
- 激光波长参数需要激进优化(历史梯度波动小)
- 机械台面倾斜参数需要保守调整(历史梯度波动大)
最终将参数调优时间缩短至18小时,且良品率波动从±1.2%降至±0.3%。"这相当于给每个参数配备了专属的优化教练,"台积电先进制程部总监李明辉表示,"系统知道哪些参数需要'大力出奇迹',哪些需要'小步慢跑'。"

工业场景的特殊适配:Adagrad的进化与变体
原始Adagrad存在一个致命缺陷:随着训练进行,分母的梯度平方累积会不断增大,导致学习率过早衰减,这在需要长期运行的工业系统中尤为突出——2026年丰田汽车在测试其焊接机器人数字孪生时发现,原始Adagrad在运行72小时后,学习率降至初始值的1/1000,模型完全停止更新。
工业界因此催生出两种改进方案:
-
Adadelta:通过引入指数移动平均替代全部历史梯度累积,解决学习率衰减问题,2026年施耐德电气在巴黎智能工厂部署的能源管理系统即采用此方案,使模型能够持续学习长达180天而不失效。
-
RMSprop:添加衰减系数控制历史梯度的保留比例,波音公司在777X机翼数字孪生中应用后,将复合材料成型工艺的参数优化效率提升了40%。
这些变体在保持自适应特性的同时,更适应工业系统的长周期运行需求,以2026年巴斯夫化工的数字孪生平台为例,其反应釜模型需要持续学习原料成分变化带来的数据分布偏移,采用RMSprop优化后,系统在连续运行300天后,仍能将产物纯度预测误差控制在0.15%以内,而传统方法在90天后就已失效。

从算法到系统:Adagrad如何重塑工业数字孪生
在2026年的工业现场,Adagrad已不再是一个孤立的优化算法,而是成为数字孪生系统的"神经调节器",以西门子安贝格工厂的数字孪生架构为例:
- 数据层:3000+传感器产生每秒15GB的时序数据
- 特征层:通过滑动窗口提取2000+维特征
- 模型层:包含127个LSTM网络,每个网络负责预测不同设备状态
- 优化层:Adagrad为每个LSTM网络的2.4万个参数维护独立学习率
这种分层架构使得系统能够动态适应不同生产阶段的需求,当工厂切换产品型号时,Adagrad会自动识别哪些参数需要快速调整(如新产品的装配路径),哪些参数需要保持稳定(如基础设备的运行阈值),2026年6月的生产数据显示,这种自适应机制使产品切换时间从8小时缩短至2.5小时,同时将切换导致的次品率从3.2%降至0.7%。
超越优化:Adagrad的工业哲学启示
Adagrad的成功不仅在于其数学特性,更在于它揭示了工业数字化的本质规律——在复杂系统中,没有"一刀切"的解决方案,必须让每个组成部分拥有自主适应能力,这种思想正在渗透到工业数字孪生的各个层面:
- 设备级:ABB机器人的数字孪生通过类似机制调整各关节的控制参数
- 产线级:海尔青岛互联工厂的装配线根据产品类型动态重组优化目标
- 工厂级:宝马莱比锡工厂的能源管理系统为不同车间分配差异化学习率
2026年麦肯锡的调研显示,采用自适应优化技术的数字孪生系统,其投资回报率比传统系统高出63%,这印证了一个真理:在工业数字化这场马拉松中,能够持续自我调整的选手才能笑到最后。
当Adagrad遇见量子计算
站在2026年的时间节点,Adagrad正面临新的挑战与机遇,随着工业数据量级突破ZB(泽字节)级别,传统计算架构已难以支撑实时优化需求,量子计算的兴起为此提供了新可能——谷歌量子AI实验室在2026年9月发布的论文显示,量子变分算法能够以指数级速度计算Adagrad的梯度累积项,这将使超大规模数字孪生系统的实时优化成为现实。
本月绿色供应链与森林保护及碳中和目标热度持续上升,相关产业迎来新发展 工业界也在探索Adagrad与联邦学习的结合,2026年