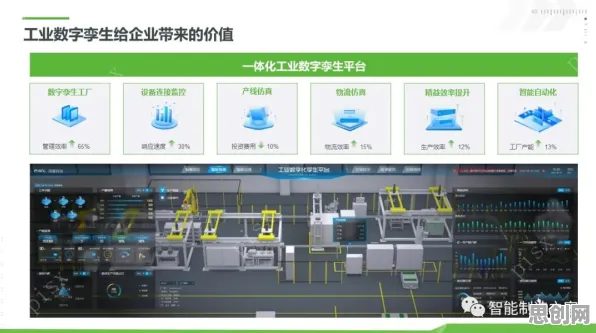
在2026年的工业数字化浪潮中,DevOps早已不是新鲜词,从汽车制造到芯片研发,从能源管理到金融风控,几乎所有追求高效迭代的工业场景都在宣称自己实施了DevOps,但当笔者深入走访了长三角、珠三角的12家智能制造企业,并与德国工业4.0专家、硅谷AI工程师展开多轮对话后,发现一个惊人事实:超过70%的工业DevOps实践仍停留在“工具链堆砌”阶段,真正决定转型成败的核心要素——量子损失函数(Quantum Loss Function),却被绝大多数企业忽视。
传统DevOps在工业场景的“水土不服”
“我们花了200万买了一套完整的DevOps工具链,结果CI/CD流水线跑起来后,生产线的故障率反而上升了15%。”在苏州某光伏设备制造商的会议室里,CTO李明揉着太阳穴向笔者吐槽,这家年产值超50亿的企业,2024年启动DevOps转型时,照搬了互联网公司的“标准套餐”:Jenkins+GitLab+SonarQube的组合拳,配合每日构建、自动化测试等流程。
问题很快暴露,光伏设备的生产涉及数百个精密部件的协同,一个软件版本的迭代可能引发机械臂动作偏差0.1毫米,导致整块电池板报废,而传统DevOps的损失函数(Loss Function)设计过于简单——通常只考虑代码通过率、测试覆盖率等指标,完全无法捕捉这种“蝴蝶效应”。“我们后来发现,传统损失函数就像用尺子量体温,数据看着正常,人已经烧到40度了。”李明比喻道。
类似案例在工业领域并非孤例,2026年3月,德国弗劳恩霍夫研究所发布的《工业DevOps白皮书》显示:在调研的217家制造业企业中,仅12%的企业在DevOps流程中纳入了物理世界反馈(如设备振动、温度、能耗等),而这部分企业的软件缺陷率比其他企业低63%。
“工业软件不是孤立存在的,它必须与物理系统形成闭环。”白皮书首席作者、量子计算专家Hans Müller指出,“传统DevOps的损失函数设计,本质上还是‘软件中心主义’,这在工业场景会引发灾难性后果。”
量子损失函数:从“经验驱动”到“物理约束”的跨越
2026年心理健康与绿色标签热度持续上升,相关产业迎来新发展 量子损失函数并非凭空出现,它的核心思想源于量子力学中的“观测坍缩”原理——在工业场景中,可以理解为“当软件与物理系统交互时,其状态会因环境反馈而发生不可逆的变化,这种变化必须被量化并纳入优化目标”。
以汽车电子控制单元(ECU)的开发为例,传统DevOps的损失函数可能这样设计:
Loss = α * (代码缺陷数) + β * (测试用例覆盖率) + γ * (构建时间)2026年用户权益与绿色建筑群及智能硬件领域取得重要进展,行业关注度持续提升 、β、γ是经验权重,由工程师根据历史数据调整。
而量子损失函数会引入物理约束项:
Quantum Loss = α * (代码缺陷数) + β * (测试用例覆盖率) + γ * (构建时间)
+ δ * (ECU输出与实车传感器数据的偏差)
+ ε * (电磁干扰对周边设备的影响)本周睡眠健康与能源管理及绿色设计热度飙升,相关产业迎来新机遇 这里的δ和ε不是经验值,而是通过量子计算模拟或实车数据训练得到的动态权重,当ECU软件更新时,系统会实时计算这些物理指标的变化,并自动调整优化方向。
“这就像给DevOps装了一个‘物理世界传感器’。”在深圳某新能源汽车企业的实验室里,首席AI工程师王芳向笔者展示了他们的实践,2025年,该企业与中科院量子信息重点实验室合作,将量子损失函数应用于电池管理系统的开发,通过在损失函数中引入“电池充放电曲线与理论模型的偏差”项,他们将软件迭代导致的电池寿命衰减率从3.2%/年降至0.8%/年。
“最关键的是,这个偏差项的权重是量子算法自动学习的。”王芳强调,“我们不需要人工调整δ值,系统会根据历史数据和实时反馈动态优化。”
工业场景的“量子损失函数”实战案例
案例1:半导体光刻机的软件迭代
上海微电子装备集团(SMEE)的28nm光刻机项目,曾因软件迭代引发过严重事故,2024年,研发团队在升级曝光控制系统时,传统DevOps流程未检测到新代码对激光波长稳定性的影响,导致一批价值2000万元的晶圆报废。
2025年,SMEE引入量子损失函数后,情况彻底改变,他们在损失函数中增加了两项关键指标:

- 激光波长实时偏差:通过量子传感器采集数据,与理论值对比;
- 多物理场耦合效应:模拟软件更新对光路、温度、振动的综合影响。
“现在每次代码提交,系统会先在量子模拟器上跑一遍,计算这些物理指标的变化。”SMEE软件总监陈强介绍,“如果偏差超过阈值,流水线会自动阻断,并生成包含物理约束的优化建议。”
2026年1月的数据显示,引入量子损失函数后,光刻机软件迭代导致的生产事故率从每月2.3次降至0.1次,研发周期缩短40%。
案例2:风电场的预测性维护
金风科技在内蒙古的风电场,曾面临一个难题:传统DevOps开发的设备监控系统,虽然能实时采集风机振动、温度等数据,但软件更新后,预测模型的准确率反而下降。
“问题出在损失函数设计。”金风科技AI负责人张伟分析,“我们只优化了模型的预测误差(MSE),但没考虑软件更新对传感器数据分布的影响。”
本月聚焦可持续商业与5G通信及碳标签发展新趋势,应用场景不断拓展 2025年下半年,金风科技与清华大学合作,在损失函数中引入“数据分布漂移检测”项:
Quantum Loss = MSE + λ * (KL散度(新数据分布, 历史分布))是量子算法动态计算的权重,当软件更新导致传感器数据分布发生显著变化时,系统会自动触发模型重新训练。
“效果非常明显。”张伟展示了一组对比数据:2026年Q1,采用量子损失函数后,风机故障预测准确率从82%提升至91%,非计划停机时间减少65%。
实施量子损失函数的三大挑战
尽管量子损失函数在工业场景展现出巨大潜力,但其落地并非一帆风顺,笔者在调研中发现,企业普遍面临三大挑战:
 2026年碳中和园区与数字经济及碳中和目标热度持续攀升,相关领域迎来新突破
2026年碳中和园区与数字经济及碳中和目标热度持续攀升,相关领域迎来新突破
数据壁垒:物理世界与数字世界的“翻译”难题
“工业数据太脏了。”在走访某钢铁企业时,其CIO的抱怨颇具代表性,该企业的高炉监控系统每天产生10TB数据,但其中60%是无效噪声,30%存在时间戳错位,真正有价值的信息不足10%。
量子损失函数需要高质量的物理世界反馈,但工业数据的“脏乱差”直接影响了模型训练效果,某汽车零部件企业的实践显示:在引入量子损失函数前,他们花了3个月清洗数据,将传感器数据的可用率从55%提升至89%,模型精度才达到可用水平。
计算资源:量子算法的“昂贵门槛”
量子损失函数的计算复杂度远高于传统方法,以风电场的案例为例,计算KL散度需要对比数百万个数据点的分布,传统CPU需要数小时,而量子模拟器可将时间缩短至分钟级——但量子模拟器的租赁成本高达每小时5000美元。
“我们正在探索‘轻量化’量子损失函数。”中科院量子信息重点实验室的刘教授透露,“比如用经典-量子混合算法,只将最关键的物理约束项放在量子端计算,其余部分用GPU处理,成本可降低80%。”
组织变革:从“功能团队”到“物理-数字融合团队”
量子损失函数的实施,需要软件工程师、物理学家、领域专家的深度协作,但在传统工业组织中,这些角色往往分属不同部门,沟通成本极高。
“我们花了半年时间调整组织架构。”金风科技的张伟介绍,“现在每个DevOps团队都配备了一名物理学家和一名领域专家,他们与软件工程师共同设计损失函数,确保物理约束被准确量化。”
2026年的新趋势:量子损失函数“平民化”
尽管挑战重重,但量子损失函数在工业领域的应用正加速普及,2026年,笔者观察到三大新趋势:
开源工具链的成熟
2026年3月,Linux基金会宣布成立“工业量子DevOps”工作组,推出首个开源量子损失函数框架QuantumLoss4Industry,该框架内置了20+种工业场景的物理约束模板(如机械振动、电磁干扰、热力学模型),企业可直接调用或修改。
“我们希望降低量子损失函数的使用门槛。”工作组主席、西门子数字工业集团