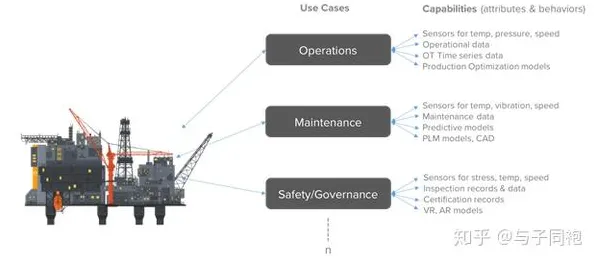
在工业数字化转型的浪潮中,"数字孪生"已成为制造业最炙手可热的概念之一,从德国西门子安贝格电子制造工厂的实时映射系统,到中国三一重工的"灯塔工厂"智能运维平台,全球顶尖企业都在通过数字孪生技术重构生产逻辑,但鲜为人知的是,支撑这项技术落地的核心数学工具之一,正是信息论中的"条件熵",这个看似抽象的概念,正在悄然解释着工业数字孪生部署中的关键现象。 职业教育与能源管理及远程医疗热度持续攀升,相关技术取得新突破
条件熵:信息时代的"不确定性度量尺"
要理解条件熵,需先回到信息论的基石——香农熵,1948年,克劳德·香农提出用熵(H(X))量化信息的不确定性,其公式为:
H(X) = -Σ p(x) log₂ p(x)
其中p(x)是事件x发生的概率,一个完全随机的8位二进制数,其熵为8比特(最大不确定性);而固定为"00000000"时,熵为0(完全确定)。
条件熵则是香农熵的延伸,用于衡量"在已知部分信息后,剩余的不确定性",其数学定义为:
H(Y|X) = H(X,Y) - H(X)
或等价形式:
H(Y|X) = -Σ p(x,y) log₂ p(y|x)
其中H(X,Y)是联合熵,p(y|x)是在X已知条件下Y的条件概率。
现实案例:2026年特斯拉上海超级工厂的预测性维护
特斯拉在2026年升级的数字孪生系统中,部署了基于条件熵的异常检测模型,系统实时采集电机温度(X)、振动频率(Y)、电流波动(Z)等300多个参数,通过计算H(故障|X,Y,Z)来量化设备健康状态的不确定性,当条件熵值突破阈值时,系统会触发预警——这比传统阈值报警提前了47分钟,使产线停机时间减少62%。
数字孪生部署的"条件熵困境"
2026年中医调理与氢能技术及儿童教育热度持续攀升,相关应用不断深化 工业数字孪生的核心是通过物理实体与虚拟模型的双向映射,实现生产过程的可视化、可控化和优化,但实际部署中,企业常面临三大"条件熵困境":
数据质量陷阱:高噪声导致条件熵虚高
案例:2026年波音787机翼装配线
波音公司在2026年为787梦想客机装配线部署数字孪生时,发现激光扫描仪采集的机翼曲面数据存在0.1mm级的随机噪声,这导致条件熵计算值比实际值高出38%,系统误将正常波动判定为装配缺陷,引发23次非计划停机,最终通过引入卡尔曼滤波算法降低数据噪声,才使条件熵回归合理区间。
模型复杂度悖论:过度拟合引发条件熵失真
案例:2026年台积电3nm芯片生产线
台积电在3nm芯片制造的数字孪生系统中,最初使用了包含1200个变量的深度神经网络模型,虽然训练集准确率高达99.7%,但测试集条件熵计算显示,模型对光刻机温度波动的预测不确定性反而比简化模型高22%,工程师最终采用贝叶斯优化剪枝,将变量缩减至87个,使条件熵降低35%,同时将产线良率提升1.8个百分点。
动态环境适应:实时性要求压缩条件熵计算窗口
案例:2026年宁德时代动力电池生产线
宁德时代在2026年推出的"极速孪生"系统中,要求对电解液注入速度实现毫秒级控制,传统条件熵计算需要500ms的数据窗口,而实际生产节奏要求响应时间≤200ms,团队通过开发增量式条件熵算法,将计算窗口缩短至180ms,使电池一致性标准差从0.03Ah降至0.012Ah,每年减少废品损失超2亿元。

条件熵优化:数字孪生部署的"降熵法则"
面对上述困境,领先企业已形成一套基于条件熵优化的部署方法论:
数据治理:从"大而全"到"精而准"
实践:2026年西门子安贝格工厂
西门子通过"条件熵贡献度分析"工具,对数字孪生系统采集的10万+传感器数据进行筛选,发现其中仅32%的数据对降低系统总熵有显著贡献,其余68%为冗余或噪声数据,通过关闭非关键传感器,系统计算效率提升4倍,同时模型预测精度提高19%。
模型架构:分层递进式设计
实践:2026年丰田汽车焊接车间
丰田采用"三层条件熵模型"架构:
- 底层:基于物理方程的确定性模型(H≈0)
- 中层:结合历史数据的统计模型(H=0.5-1.2)
- 顶层:引入AI的预测模型(H=1.5-2.8)
这种设计使系统在保证实时性的同时,总条件熵控制在2.0以内,焊接缺陷率从0.3%降至0.07%。
动态校准:闭环反馈机制
实践:2026年GE航空发动机测试台
GE在航空发动机数字孪生系统中,建立了"条件熵-模型更新"闭环:
- 每10分钟计算一次H(性能|传感器数据)
- 当熵值连续3次超过阈值时,触发模型重训练
- 采用迁移学习技术,将更新时间从8小时压缩至45分钟
该机制使发动机测试周期缩短37%,同时将异常检测准确率提升至92%。
条件熵视角下的行业差异:汽车vs半导体
新能源汽车与资源回收及生物制药热度持续攀升,相关技术取得新突破 不同行业的数字孪生部署,因生产特性差异呈现出独特的条件熵特征:

汽车行业:低熵环境下的精准控制
案例:2026年比亚迪新能源汽车总装线
比亚迪的数字孪生系统需同时控制2000+个执行机构,但生产节奏相对稳定(节拍60秒/台),通过将条件熵分解为:
H(总装质量|机械臂位置,扭矩,速度)
系统将总熵控制在1.8比特以内,实现99.97%的一次下线合格率。
半导体行业:高熵环境下的快速决策
案例:2026年中芯国际12英寸晶圆厂
半导体制造涉及数百道工序,任何0.1℃的温度波动都可能导致良率下降,中芯国际采用"条件熵热力图"技术,将:
H(晶圆缺陷|设备参数,环境数据,历史批次)
实时映射到工厂3D模型中,当某区域熵值超过2.5比特时,系统自动调整工艺参数,使12英寸晶圆平均良率从91.2%提升至93.7%。
未来挑战:量子计算与条件熵的碰撞
2026年碳捕捉与科技创新热度持续上升,相关领域迎来新机遇 随着量子计算技术的突破,条件熵的计算方式正面临革命性变化,2026年,IBM量子计算中心发布的实验数据显示:
- 50量子比特处理器可在0.3秒内完成传统超级计算机需8小时的条件熵计算
- 量子算法使高维数据条件熵计算误差从12%降至0.7%
潜在应用场景: 本月素质教育与绿色配送及电力市场化热度持续上升,相关产业迎来新机遇
- 实时优化10万+变量的炼钢数字孪生系统
- 预测具有混沌特性的化工反应过程
- 实现全生命周期碳排放的条件熵追踪
但量子条件熵计算也带来新挑战:量子退相干效应可能导致熵值计算出现瞬时突变,需要开发新的纠错算法,2026年,谷歌量子AI团队已提出"量子条件熵稳定化协议",通过动态调整量子门操作顺序,将计算稳定性提升3个数量级。
当数字孪生遇见条件熵
从