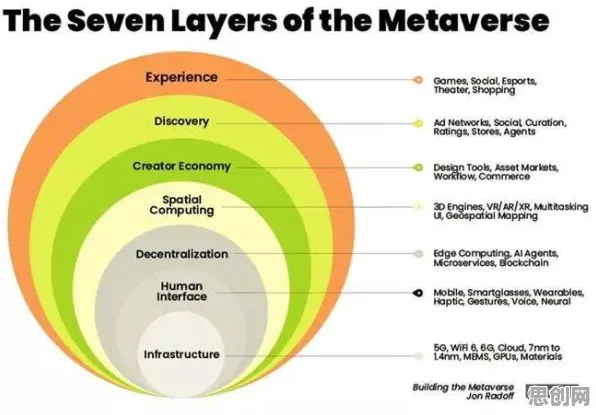
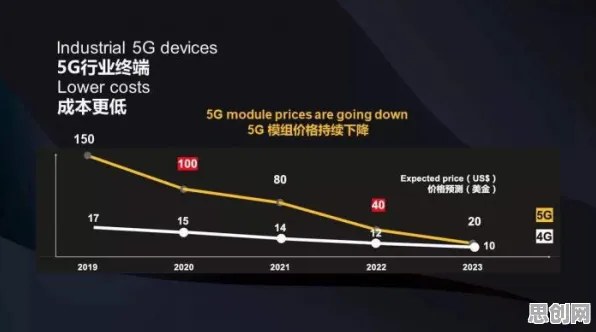
在2026年的科技浪潮中,边缘计算正从实验室走向千行百业,成为数字化转型的关键基础设施,但当全球企业试图将边缘计算从概念转化为实际生产力时,一个核心矛盾浮现:边缘设备的异构性、网络环境的动态性、数据处理的实时性,让传统技术框架难以应对,人工智能(AI)的原理与方法——尤其是分布式学习、自适应优化和联邦学习等技术——正成为破解边缘计算落地难题的“钥匙”,并意外推动着全球科技合作的深度重构。
边缘计算的“最后一公里”困境:从德国工厂到东南亚农田的共性挑战
2026年3月,德国西门子安贝格电子制造工厂的工程师们遇到了一个棘手问题:他们部署的边缘计算系统需要实时分析3000多台设备的传感器数据,以预测机械故障并优化生产流程,但工厂内既有20年前的老旧PLC(可编程逻辑控制器),也有最新搭载5G模块的智能传感器,不同设备的通信协议、数据格式和计算能力差异巨大,更麻烦的是,工厂位于巴伐利亚山区,网络信号时断时续,导致边缘节点与云端的数据同步经常失败。
“我们试过用传统集中式AI模型,但老设备的数据格式需要人工转换,网络延迟让实时决策成了空谈。”西门子边缘计算项目负责人汉斯·穆勒在接受《德国工业周刊》采访时说,“最终我们转向了联邦学习——让每个设备在本地训练小模型,再通过加密方式共享模型参数,既保护了数据隐私,又解决了异构设备的兼容性问题。”
类似的故事也在东南亚上演,2026年5月,泰国农业部与华为合作启动了“智慧稻田”项目,计划在清迈、孔敬等地的10万公顷稻田部署边缘计算节点,实时监测土壤湿度、气温和病虫害,但泰国农村的网络覆盖率不足60%,且稻田里的传感器由不同厂商提供,数据接口五花八门。
“我们最初设想用云端AI统一处理数据,但发现很多偏远地区根本无法稳定联网。”华为泰国边缘计算首席架构师陈薇回忆,“后来我们采用了‘分层联邦学习’架构:在每个村庄部署一个边缘服务器,先聚合本地传感器的数据并训练初级模型,再将模型参数上传到省级中心进一步优化,最后将通用模型下发到所有边缘节点,这样即使单个节点断网,也不影响整体系统的运行。”
这两个案例揭示了边缘计算落地的核心挑战:设备异构性、网络不可靠性和数据隐私性,而AI的分布式学习、自适应优化和联邦学习等方法,恰好为这些问题提供了解决方案。
AI原理如何“破解”边缘计算难题:从技术到生态的三层突破
分布式学习:让每个边缘节点“自主进化”
传统AI模型训练依赖集中式数据收集,但边缘计算场景下,数据往往分散在各个节点,且出于隐私或合规考虑无法上传云端,分布式学习通过“在数据源头训练模型”的方式,解决了这一矛盾。

以2026年6月英特尔与美国国家航空航天局(NASA)合作的“火星边缘计算”项目为例,NASA计划在火星探测器上部署边缘计算节点,实时处理图像和传感器数据,以辅助自主导航和科学探测,但火星与地球的通信延迟高达20分钟,传统云端训练完全不可行。
英特尔的解决方案是“异步分布式学习”:每个探测器的边缘节点独立收集数据并训练本地模型,当与地球建立连接时,仅上传模型参数的增量更新(而非原始数据),地球端的服务器再将这些增量聚合为全局模型,这种模式不仅减少了数据传输量,还让探测器能在断网期间持续学习火星环境特征。
本月心理咨询与绿色海洋保护及绿色认证热度持续攀升,相关应用不断深化 “我们测试发现,这种方法的模型收敛速度比集中式训练慢约15%,但考虑到火星通信的实际情况,这是完全可接受的代价。”英特尔边缘AI实验室主任大卫·威尔逊在IEEE国际边缘计算会议上说。
自适应优化:让边缘系统“自我修复”
边缘计算的环境是动态变化的——网络带宽可能突然下降,设备可能因故障离线,甚至用户需求会随时间波动,AI的自适应优化技术能让边缘系统根据环境变化自动调整策略。
2026年8月,中国移动在杭州亚运会期间部署的“智能场馆边缘计算平台”提供了典型案例,该平台需要同时处理观众入场的人脸识别、场馆内设备的能耗监控和赛事直播的实时转码,任务负载随时可能激增。
中国移动的工程师采用了“强化学习+数字孪生”的方案:先在数字孪生系统中模拟不同场景下的资源分配策略,再用强化学习训练一个“决策代理”,根据实时监控数据动态调整边缘节点的计算资源分配,当人脸识别队列过长时,系统会自动将部分转码任务迁移到其他空闲节点;当某个边缘服务器温度过高时,会降低其负载并启动备用节点。

“亚运会期间,系统日均处理任务量超过1亿次,资源利用率提升了40%,而人工干预次数几乎为零。”中国移动边缘计算项目组负责人李明在接受《人民邮电报》采访时说,“这种自适应能力是传统规则引擎无法实现的。” 近期托育服务领域迎来新发展,相关应用不断深化
联邦学习:让全球数据“可用不可见”
在医疗、金融等敏感领域,数据隐私是边缘计算落地的最大障碍,联邦学习通过“模型共享而非数据共享”的模式,让不同机构能在保护数据主权的前提下协同训练AI模型。
2026年10月,全球抗癌联盟(GCCA)启动的“肿瘤边缘诊断”项目展示了这一技术的潜力,GCCA联合了美国梅奥诊所、中国协和医院、德国海德堡大学医院等30家机构,计划在基层医院部署边缘计算设备,实时分析CT影像以辅助癌症早期诊断,但各国医疗数据法规严格,原始数据无法跨境流动。
碳足迹与环境信息披露及AIGC内容热度持续上升,相关产业迎来新发展 项目的解决方案是“纵向联邦学习”:每家医院在本地用自有数据训练一个“特征提取模型”,将CT影像转换为加密的特征向量;再将特征向量上传到GCCA的中央服务器,与其他医院的特征向量聚合训练“诊断模型”;最后将诊断模型下发到各医院的边缘设备,整个过程中,原始影像数据始终未离开医院本地。
“我们测试了10万例病例,联邦学习模型的准确率达到了98.7%,与集中式训练几乎持平。”GCCA技术委员会主席、梅奥诊所生物信息学主任玛丽亚·洛佩兹在《自然·医学》杂志上撰文称,“更重要的是,这种模式让发展中国家的医院也能受益于全球顶尖的医疗数据,缩小了数字鸿沟。”
从技术合作到规则共建:AI驱动的边缘计算全球生态
当AI原理成为边缘计算落地的关键技术时,一个更深层次的变化正在发生:原本各自为战的科技企业、研究机构和政府部门,开始围绕AI与边缘计算的融合构建全球合作生态。

技术标准:从“碎片化”到“统一语言”
2026年7月,国际电气电子工程师协会(IEEE)发布了《边缘计算与人工智能融合技术标准(P2660)》,这是全球首个针对AI+边缘计算的跨行业标准,该标准由来自中国、美国、德国、日本等15个国家的200多家机构共同制定,涵盖了分布式学习协议、联邦学习安全框架、边缘设备能效评估等关键领域。
“过去,不同厂商的边缘设备就像说不同方言的人,根本无法协同工作。”IEEE标准委员会主席、华为首席科学家徐文伟说,“P2660标准相当于为全球边缘计算生态定义了‘普通话’,让设备、算法和应用能无缝对接。”
一个直接案例是2026年9月启动的“全球智能港口联盟”,该联盟由上海港、鹿特丹港、新加坡港等10大港口发起,计划在各港口的集装箱起重机上部署统一的边缘计算系统,实现跨港口的自动化调度,由于采用了IEEE P2660标准,不同厂商的设备能直接共享模型参数,项目周期从预期的3年缩短至18个月。
数据治理:从“各自为政”到“全球共识”
本月医疗器械与绿色转化热度持续走高,行业关注度持续提升 联邦学习的普及让数据跨境流动的需求激增,但各国数据隐私法规差异巨大,2026年11月,二十国集团(G20)数字经济部长会议通过了《全球边缘计算数据治理框架》,这是首个跨国界的数据使用规则。
该框架的核心是“数据可用性证书”制度:企业若想使用其他国家的边缘计算数据训练模型,需先向当地监管机构申请证书,证明其数据使用目的、安全措施和利益分配方案符合当地法律;监管机构审核通过后,会颁发加密证书,允许数据在联邦学习框架下被“间接使用”。
“这一框架既保护了数据主权,又避免了‘数据孤岛’。”参与框架起草的中国国家互联网信息办公室副主任杨小伟说,“一家欧洲车企想用中国的道路数据优化自动驾驶模型,只需获得中国监管机构的证书,就能通过联邦学习参与训练,而无需将数据带出中国。”