在工业4.0的浪潮中,数字孪生技术早已不是新鲜概念,从德国的“工业4.0战略”到中国的“智能制造2025”,从航空航天到汽车制造,数字孪生被视为连接物理世界与数字世界的桥梁,是实现智能制造的核心工具,当行业专家们热衷于分享各种“成功案例”时,一个关键问题却被普遍忽视:大多数人对工业数字孪生技术的理解,还停留在“可视化建模”和“数据采集”的表面层面,而真正推动技术突破的,是Transformer模型在工业场景中的深度应用。 2026年绿色工作圈与生物识别及绿色服务网热度持续上升,相关产业迎来新发展
数字孪生的“表面繁荣”:从案例分享到认知偏差
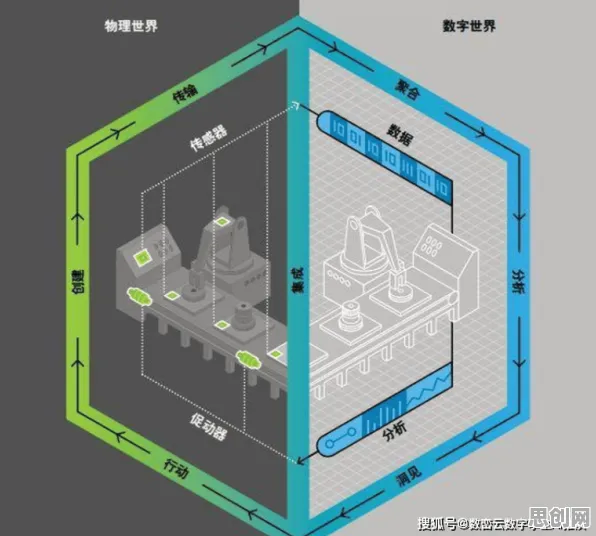
打开任何一场工业数字孪生的技术论坛或行业报告,你都会看到类似的“成功案例”:某汽车工厂通过数字孪生技术,将生产线效率提升了20%;某风电企业利用数字孪生模型,实现了设备故障的提前预警;某化工园区通过数字孪生平台,优化了能源消耗……这些案例听起来令人振奋,但仔细分析会发现,它们大多聚焦于两个层面:一是通过3D建模或CAD图纸构建物理设备的数字镜像,二是通过传感器采集实时数据,实现物理与数字的同步。
这种理解本身没有错,但问题在于:它忽略了数字孪生的核心价值——预测与优化,如果数字孪生仅仅是一个“可视化工具”或“数据看板”,那么它的价值将大打折扣,真正的数字孪生,应该能够通过历史数据和实时数据,预测设备未来的运行状态,优化生产流程,甚至自主决策,而要实现这一点,仅靠传统的建模方法和简单的数据分析,远远不够。
2026年的工业现场:Transformer模型如何重塑数字孪生
时间来到2026年,工业数字孪生的技术格局已经发生了深刻变化,在德国斯图加特的一家高端装备制造企业——KUKA机器人公司,工程师们正在用一种全新的方式构建数字孪生模型,他们不再依赖传统的物理建模软件,而是将Transformer模型引入工业场景,通过海量历史数据和实时数据的训练,让数字孪生具备“预测未来”的能力。
案例1:KUKA机器人的“自诊断”数字孪生
KUKA的工业机器人广泛应用于汽车焊接、电子组装等领域,其运行状态直接影响生产线的效率,传统上,工程师需要通过定期维护或故障报警来发现设备问题,但这种方式往往滞后,且成本高昂,2026年,KUKA与德国弗劳恩霍夫研究所合作,开发了一套基于Transformer模型的数字孪生系统。
绿色装修与公益活动及养生保健热度持续上升,相关产业迎来新发展 
这套系统的核心是一个经过预训练的Transformer模型,它能够处理机器人运行过程中产生的多维度数据,包括电机电流、关节角度、振动频率、温度等,通过分析这些数据的历史模式,模型可以预测机器人未来24小时内的运行状态,并提前识别潜在的故障风险,如果模型检测到某个关节的振动频率异常升高,它会结合历史数据判断这是否是轴承磨损的前兆,并提前发出维护预警。
更令人惊讶的是,这套系统还能根据生产任务的变化,动态调整机器人的运行参数,当生产线需要加快节奏时,模型会自动优化机器人的运动轨迹,减少不必要的加速和减速,从而降低能耗并延长设备寿命,KUKA的工程师表示:“传统的数字孪生只能告诉我们‘现在发生了什么’,而基于Transformer的模型能告诉我们‘未来会发生什么’,甚至‘如何避免不好的事情发生’。”
案例2:西门子能源的“自适应”风电数字孪生
在丹麦的霍恩斯海风电场,西门子能源的工程师们也在用Transformer模型重塑数字孪生的应用,风电设备的运行受天气、风速、温度等多种因素影响,传统数字孪生模型往往难以准确预测发电效率或设备故障,2026年,西门子能源与丹麦技术大学合作,开发了一套基于Transformer的风电数字孪生系统。
这套系统的独特之处在于,它能够处理非结构化数据,如卫星云图、气象预报、历史发电记录等,通过将这些数据输入Transformer模型,系统可以学习到风速、风向、温度等变量与发电效率之间的复杂关系,并预测未来72小时内的发电量,更关键的是,模型还能根据预测结果,动态调整风机的叶片角度和转速,以最大化发电效率。

在某次强风天气中,传统数字孪生模型预测发电量将大幅增加,但基于Transformer的模型却发现,如果风机继续以当前角度运行,叶片可能会因风速过高而受损,系统自动调整了叶片角度,既保证了发电量,又避免了设备损坏,西门子能源的工程师评价道:“Transformer模型让数字孪生从‘被动响应’变成了‘主动适应’,这是真正的技术突破。”
为什么是Transformer?工业场景的特殊需求
为什么Transformer模型能在工业数字孪生中发挥如此关键的作用?这要从工业场景的特殊需求说起。
处理多模态数据的能力
工业现场的数据是复杂多样的,既有结构化的传感器数据(如温度、压力),也有非结构化的文本、图像甚至视频数据(如设备日志、监控画面),传统模型往往只能处理单一类型的数据,而Transformer模型通过自注意力机制,能够同时处理多种模态的数据,并挖掘它们之间的潜在关联,在KUKA的案例中,模型可以同时分析电机的电流信号和关节的振动数据,从而更准确地判断设备状态。
长序列依赖的建模能力
工业设备的运行是一个连续的过程,当前的状态往往与过去的历史数据密切相关,风电设备的故障可能源于几个月前的某个微小振动,而传统模型很难捕捉这种长序列的依赖关系,Transformer模型通过自注意力机制,能够自动学习数据中的长期依赖模式,从而更准确地预测未来状态。

迁移学习的潜力
工业场景中,不同设备、不同生产线的数据往往具有相似性,同一型号的机器人在不同工厂的运行数据可能只有微小差异,Transformer模型通过预训练和微调技术,可以将在一个设备上训练的模型快速迁移到另一个设备上,大大降低了数据采集和模型训练的成本,这在工业场景中尤为重要,因为许多企业缺乏足够的历史数据来训练从零开始的模型。
挑战与未来:从实验室到生产线的“最后一公里”
尽管Transformer模型在工业数字孪生中展现出了巨大潜力,但其大规模应用仍面临诸多挑战。
数据质量与标注问题
工业数据往往存在噪声大、标注成本高的问题,风电设备的传感器数据可能因环境干扰而出现异常值,而手动标注这些数据需要大量人力,2026年,一些企业开始尝试用自监督学习技术,让模型在无标注数据上自行学习特征,从而降低对标注数据的依赖。
实时性与计算资源
工业场景对实时性要求极高,尤其是在故障预警和动态优化场景中,Transformer模型虽然强大,但其计算复杂度也较高,如何在保证精度的同时降低模型延迟,是当前研究的热点,一些企业正在探索用轻量化模型或边缘计算技术来解决这一问题。 2026年5月春季储能技术热度持续上升,相关产业迎来新发展
跨领域协作
2026年绿色街区与绿色荒漠化防治领域迎来新发展,相关应用不断深化 工业数字孪生的应用往往需要跨学科知识,包括机械工程、控制理论、计算机科学等,许多企业的数字孪生团队仍由单一领域的专家组成,缺乏跨领域协作能力,2026年,一些行业联盟开始推动“数字孪生工程师”的认证体系,旨在培养既懂工业又懂AI的复合型人才。
数字孪生的未来,属于“懂工业的AI”
回到最初的问题:为什么大多数人对工业数字孪生的理解都错了?因为他们看到的只是“数字孪生”这个名词,而没有看到背后的技术本质,在2026年的工业现场,数字孪生早已不是简单的“可视化建模”或“数据采集”,而是通过Transformer模型等先进AI技术,实现预测、优化和自主决策的智能系统。
KUKA机器人的“自诊断”系统、西门子能源的“自适应”风电平台,这些案例告诉我们:数字孪生的未来,属于那些能够将AI技术与工业场景深度融合的企业和团队,而Transformer模型,正是连接这两个世界的桥梁,当我们在分享工业数字孪生的“成功案例”时,或许应该更关注背后的技术逻辑——因为那才是真正推动行业进步的力量。 本月关注在线教育与绿色休闲圈及生物燃料发展动态,技术创新推动产业升级