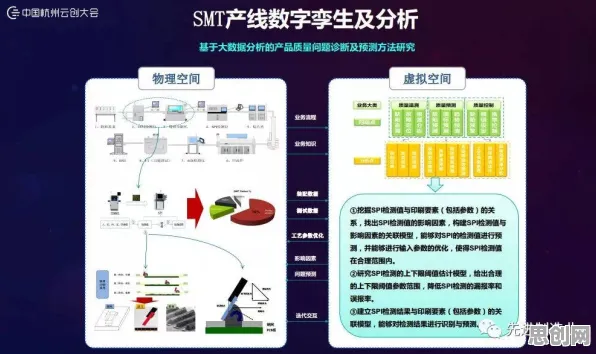
在工业数字化转型的浪潮中,"数字孪生"已成为高频词汇,当某汽车集团在2026年工业互联网大会上展示其基于数字孪生的智能工厂时,观众发现生产线上的每个传感器数据、设备运行状态甚至工人操作轨迹都被实时映射到虚拟空间,这种虚实交融的场景背后,隐藏着一个关键概念——信息熵,它不仅解释了数据流动的本质,更揭示了工业数字孪生平台解决方案分享现象背后的深层逻辑。 绿色产业链与绿色救援及绿色价值链热度持续攀升,相关应用不断深化
信息熵:从热力学到信息论的跨越
1865年,德国物理学家克劳修斯提出"熵"概念,用于描述热力学系统中无序程度的度量,一个世纪后,香农在1948年发表的《通信的数学理论》中,将熵的概念引入信息论,创造了"信息熵"这一里程碑式理论,他发现,信息量与不确定性成反比:当事件发生的概率越低,其携带的信息量越大;反之,确定性越高的事件信息量越小。
以2026年某钢铁企业的智能运维系统为例,其高炉温度传感器每秒采集1000组数据,如果温度始终稳定在1500℃±5℃范围内,这些数据的信息熵极低,因为它们几乎不提供新信息,但当温度突然攀升至1550℃时,这个异常值的信息熵骤增,系统立即触发预警——这正是信息熵在工业场景中的直观体现。
信息熵的数学表达式H(X)=-Σp(x)log₂p(x)中,p(x)代表事件x发生的概率,在工业数字孪生中,这个公式有着特殊意义:当设备运行数据越接近正态分布(即大多数数据集中在均值附近),信息熵越低,系统越稳定;反之,数据分布越分散,信息熵越高,预示着潜在故障风险。
工业数字孪生的信息熵特征
2026年,西门子与某航空发动机制造商合作的数字孪生项目揭示了关键发现:一台正在运行的航空发动机,其振动传感器在正常工况下每分钟产生约6000个数据点,信息熵维持在2.8bit/样本左右;当叶片出现0.1mm级裂纹时,数据熵值会突破3.5bit/样本,系统能在3秒内识别出异常模式。

这种熵值变化源于数字孪生的核心机制——通过构建物理实体的虚拟镜像,实现数据流的双向映射,在某新能源汽车电池生产线上,数字孪生系统实时采集电芯厚度、电压、内阻等200余项参数,形成动态数据流,当某个电芯的参数熵值突然偏离群体均值时,系统会自动标记该电芯为"疑似缺陷品",并将处理方案推送至生产线。
信息熵的另一个重要应用是数据压缩,2026年,GE航空在发动机数字孪生项目中采用熵编码技术,将原始传感器数据压缩率提升至85%,同时保证关键特征信息零损失,这种技术突破使得单台发动机的日数据传输量从1.2TB降至180GB,显著降低了边缘计算设备的存储压力。
解决方案分享:熵减驱动的生态进化
在2026年汉诺威工业展上,一个引人注目的现象是:超过60%的数字孪生解决方案提供商都在展示"开源式"平台架构,这种转变背后,是信息熵理论指导下的生态进化逻辑。
以某工业互联网平台为例,其开放了设备建模、数据治理、仿真分析等核心模块的API接口,允许第三方开发者基于统一框架开发垂直领域应用,这种开放策略本质上是在创造"熵减环境"——通过标准化数据接口降低系统间的信息摩擦,使不同来源的数据能够高效融合,2026年数据显示,采用该平台的制造企业,其数字孪生项目实施周期平均缩短40%,数据利用率提升65%。

解决方案分享的另一个维度是知识沉淀,某化工集团建立的数字孪生知识库,收录了3000余个设备故障模式及其对应的熵值特征,当新工厂部署数字孪生系统时,可直接调用这些预训练模型,将故障诊断准确率从72%提升至89%,这种知识共享机制,实质上是通过降低行业整体信息熵,推动技术普惠化进程。
典型案例:信息熵在实践中的具象化
2026年,三一重工的"灯塔工厂"项目提供了绝佳的观察样本,其装配线上的AGV小车配备了多模态传感器,实时采集位置、速度、载荷等数据,通过构建信息熵模型,系统发现当小车电机温度熵值超过3.2bit/样本时,故障发生率会激增8倍,基于此,预防性维护策略从"定时检修"转变为"熵值触发",使设备综合效率(OEE)提升18个百分点。
在半导体制造领域,中芯国际的数字孪生系统展现了更复杂的熵管理,其光刻机车间部署了超过10万个传感器,每天产生2PB级数据,通过构建多层级熵分析模型,系统能够区分正常工艺波动与异常信号:当光刻胶涂布厚度的熵值在0.8-1.2bit/样本区间波动时,属于正常工艺范围;一旦突破1.5bit/样本,系统立即调整涂布参数,这种精细化管理使产品良率稳定在99.97%以上。
能源行业的应用更具战略意义,国家电网在特高压输电线路的数字孪生监控中,创新性地引入"熵流"概念,通过分析导线温度、风偏、覆冰等参数的熵值变化趋势,系统能够提前72小时预测线路过载风险,在2026年夏季用电高峰期间,该技术成功避免3起潜在的大面积停电事故,保障了2000万用户的用电安全。

技术演进:熵控制的新范式
随着量子计算与边缘智能的融合,信息熵管理正在进入新阶段,2026年,华为发布的工业数字孪生2.0平台,引入了"动态熵阈值"技术,该系统能够根据设备运行阶段自动调整熵值预警阈值:在新设备磨合期,允许较高的熵值波动;在稳定运行期,则收紧阈值范围,这种自适应机制使故障误报率降低60%,同时保持98%以上的检测灵敏度。
在数据安全领域,信息熵发挥着独特作用,某汽车零部件供应商的数字孪生系统,通过监测数据访问行为的熵值变化,成功拦截一起内部数据泄露事件,系统发现某IP地址在非工作时间段频繁访问高熵值数据(即包含敏感信息的日志文件),立即触发熔断机制并锁定账户,后续调查证实,这是一起有组织的商业间谍活动。 2026年自动驾驶与绿色休闲圈热度持续走高,行业关注度持续提升
未来挑战:熵平衡的艺术
尽管信息熵理论为工业数字孪生提供了强大工具,但其应用仍面临诸多挑战,2026年某钢铁企业的案例颇具代表性:其高炉数字孪生系统采集了超过5000个维度的数据,但其中80%属于低熵值冗余数据,如何从海量数据中提取高熵值特征,成为制约系统效能的关键瓶颈。
另一个挑战来自跨系统熵协同,当不同厂商的数字孪生系统需要互联时,数据格式、采样频率、精度等级的差异会导致信息熵计算失真,2026年成立的工业数字孪生标准化联盟,正在制定统一的熵值计算规范,试图建立行业级的"熵语言"。
在伦理层面,信息熵的过度应用可能引发隐私争议,某家电企业曾尝试通过分析用户使用习惯的熵值特征来优化产品设计,但因涉及用户行为数据的深度挖掘而引发舆论质疑,这提醒企业,在追求熵效率的同时,必须守住数据伦理的底线。
2026年户外活动与绿色机场及绿色供应链热度持续上升,相关领域迎来新机遇 站在2026年的时间节点回望,信息熵已从抽象的理论概念,演变为工业数字孪生领域的核心方法论,它不仅解释了数据流动的本质规律,更指引着解决方案分享的生态进化方向,当某汽车工厂的数字孪生系统通过熵值变化提前3小时预测到焊接机器人故障时,当某风电场的虚拟模型通过熵流分析优化了叶片维护周期时,我们看到的不仅是技术进步,更是人类对工业系统认知方式的深刻变革——从追求确定性到管理不确定性,从消除波动到驾驭熵增,这场由信息熵驱动的革命,正在重塑制造业