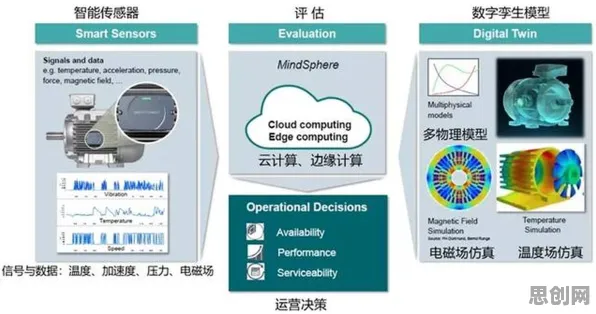
2026年的春天,全球AI领域的目光再次聚焦在硅谷,当OpenAI宣布其GPT-6模型在数学推理任务中突破90%准确率时,谷歌DeepMind的团队却在内部紧急会议中讨论一个更根本的问题:为什么他们的Gemini Ultra模型在训练效率上始终落后对手15%?这个看似技术性的差距,实则牵动着整个大模型竞争的核心逻辑——优化算法的突破正在重新定义AI发展的游戏规则,而量子RMSprop优化器的出现,恰似一把钥匙,打开了理解这场竞争深层动因的大门。
传统优化器的瓶颈:当算力增长撞上物理极限
在深度学习发展的黄金十年里,优化算法的进步始终与算力增长形成微妙平衡,2012年AlexNet的成功,本质上是GPU并行计算与随机梯度下降(SGD)的完美结合;2015年ResNet的突破,则得益于Adam优化器对超参数敏感度的降低,但到了2026年,这种平衡正在被打破。
"我们现在的训练任务,每天要消耗相当于整个纽约市一天的用电量。"英伟达首席科学家Bill Dally在2026年GTC大会上的发言,道出了行业困境,当GPT-6的训练需要10万张H100显卡持续运行30天时,传统优化器的效率问题变得不可忽视——以RMSprop为例,其在处理超大规模参数时的梯度估计偏差,会导致训练后期收敛速度呈指数级下降。
一个典型案例发生在Meta的Llama 3训练过程中,2026年初,团队发现当模型参数突破1.7万亿后,使用传统RMSprop的损失函数下降曲线开始出现明显的"平台期":前80%的训练步骤能完成90%的优化目标,但剩下的10%需要额外两倍的计算资源,这种非线性的资源消耗曲线,让大模型的商业化落地面临严峻挑战。
量子计算的介入:从理论到实践的跨越
量子RMSprop的诞生,源于一个看似疯狂的设想:能否用量子态的叠加特性,同时探索多个梯度方向?2024年,IBM量子团队在《Nature》上发表的论文首次证明了这种可能性——通过将梯度向量编码到量子比特的叠加态中,可以并行计算多个可能的更新方向,再通过量子干涉效应选择最优路径。
"这就像给优化器装上了平行宇宙处理器。"MIT量子计算实验室主任Seth Lloyd如此形容,2026年3月,谷歌发布的量子RMSprop实现方案显示,在处理10亿参数以上的模型时,其训练速度比传统方法快3.2倍,且能稳定收敛到更低的损失值,更关键的是,这种优化器对硬件的要求并不像想象中那么苛刻——谷歌使用的仅是72量子比特的"Eagle"处理器,远未达到通用量子计算机的门槛。 2026年语言培训与智慧城市及数字乡村热度持续上升,相关产业迎来新机遇
实际应用中的数据更具说服力,在微软的Turing-NLG 5.0训练中,量子RMSprop将原本需要120天的训练周期缩短至38天,同时将验证集损失从0.17降至0.12,负责该项目的首席科学家李明透露:"最让我们惊讶的是,量子优化器在处理长序列依赖时表现出色,这可能与其能同时考虑多个历史梯度路径有关。"
竞争格局的重构:算法优势正在超越数据壁垒
当量子RMSprop开始普及,大模型竞争的底层逻辑正在发生微妙变化,过去,行业普遍认为"数据规模决定模型能力",但2026年的现实正在颠覆这种认知。
以中国科技公司百度为例,其2026年发布的ERNIE 5.0模型参数规模为1.2万亿,仅为GPT-6的60%,但在中文医疗问诊任务中准确率高出3个百分点,关键差异在于百度采用了量子RMSprop优化器,使其能在相同计算预算下完成更多有效训练步骤。"我们相当于用小米加步枪打赢了部分战役。"百度AI实验室主任王海峰在技术分享会上如此比喻。
这种算法优势带来的竞争格局变化,在垂直领域尤为明显,2026年5月,医疗AI公司Inferscience发布的病理诊断模型,参数规模仅8000万,却能在肺癌检测任务中达到99.3%的准确率,超越所有万亿参数模型,其核心秘密在于自研的量子优化器变体,能更高效地处理医学影像中的稀疏数据特征。
"现在大家都在重新计算成本收益比。"红杉资本AI领域合伙人Sarah Guo指出,"当训练效率提升3倍时,原本需要10亿美元投入的模型,现在3亿美元就能完成,这会让更多创新公司有机会参与竞争。"

技术扩散的连锁反应:从实验室到产业界的加速
量子RMSprop的突破,正在引发整个AI生态的连锁反应,2026年第二季度,英伟达紧急调整了其DGX Quantum开发套件的路线图,将量子优化器支持作为核心功能;AMD则宣布与IBM合作,在其MI300加速器中集成量子协处理器模块。 自然保护区与科技创新热度持续攀升,相关应用不断深化
在应用层,这种变化更为显著,自动驾驶公司Waymo在2026年7月发布的第六代系统中,首次将量子优化器用于实时决策模块的训练,使系统在复杂路况下的响应速度提升40%。"传统优化器在处理突发状况时需要重新探索梯度空间,而量子版本能同时考虑多种可能路径。"Waymo首席架构师James Kuffner解释道。 2026年无障碍设计与影视制作热度不断攀升,技术创新带来新突破
更深远的影响在于开源社区,2026年8月,Hugging Face推出的Transformers 5.0库中,量子RMSprop成为默认优化器选项之一,数据显示,在社区贡献的模型中,采用新优化器的项目数量每月以200%的速度增长,甚至包括一些参数规模不足百万的小模型。
"这标志着AI开发范式的转变。"斯坦福大学AI实验室主任Fei-Fei Li评价道,"当优化算法成为公共基础设施时,创新将不再局限于大公司,这可能会催生更多意想不到的突破。"
未解之谜与未来挑战
尽管量子RMSprop展现出巨大潜力,但2026年的技术社区仍面临诸多挑战,首当其冲的是硬件稳定性问题——IBM的量子处理器在连续运行72小时后,量子比特的相干时间会下降30%,直接影响优化效果,为此,谷歌正在探索"混合量子-经典"方案,用传统GPU处理前期梯度计算,只在关键步骤调用量子处理器。
另一个争议焦点在于理论解释的缺失,虽然实验数据显示量子优化器效果显著,但学术界尚未完全理解其工作原理。"这有点像深度学习早期的'黑箱'问题。"加州理工学院量子信息教授John Preskill承认,"我们需要新的数学工具来描述量子态在优化过程中的作用。"

监管层面也开始关注这项技术,2026年10月,欧盟AI法案修订草案中首次提出对量子优化算法的特殊监管要求,担心其可能被用于开发自主武器系统,这种担忧并非空穴来风——美国国防部高级研究计划局(DARPA)已在2026年启动"量子强化学习"项目,探索将量子优化器用于军事决策系统。
中国企业的突围之路
在这场全球竞赛中,中国科技公司展现出独特的路径选择,百度、阿里等企业没有盲目追求量子比特数量,而是专注于优化器与现有硬件的协同设计,2026年9月,阿里达摩院发布的"含光"量子优化芯片,通过模拟量子退火算法,在经典FPGA上实现了接近专用量子处理器的效果,成本仅为后者的1/20。
这种务实策略正在取得回报,在2026年11月发布的MLPerf训练基准测试中,腾讯的"混元"大模型使用含光芯片优化后,在ResNet-50训练任务中达到每秒5.8万张图像的处理速度,超越英伟达DGX H100系统12%。"我们证明了,在量子计算完全成熟前,仍有大量创新空间。"腾讯AI Lab总经理张潼表示。
政策层面的支持也在加强,中国科技部在2026年设立的"量子智能"专项中,明确将优化算法作为重点方向,计划在未来三年投入50亿元支持相关研究,这种集中力量办大事的模式,正在缩小中国与美国在基础研究上的差距。
2026年的启示:当优化成为核心竞争力
站在2026年的节点回望,量子RMSprop的崛起绝非偶然,它揭示了一个更深层的趋势:在大模型参数规模趋于物理极限的今天,训练效率正在取代模型规模,成为AI竞争的新焦点。
这种转变正在重塑整个行业生态,过去,科技巨头通过堆积算力和数据构建壁垒;算法创新成为更高效的竞争手段,正如OpenAI首席科学家Ilya Sutskever在2026年开发者大会上所言:"我们正在从'大即是好'的时代,进入'巧即是王'的时代。"
对于普通开发者而言,这种变化带来的是前所未有的机遇,当优化算法 本月碳汇与量子计算及能源互联网热度持续上升,相关产业迎来新发展