2026年的工业圈里,一个有趣的现象正在蔓延:原本被视为“高精尖”的数字孪生技术,正从大型企业的实验室走向中小工厂的车间,甚至出现在个体工程师的电脑屏幕上,更让人意外的是,许多实践者并非专业出身——他们可能是流水线上的班组长、刚毕业的技术员,或是跨界转型的创业者,这些“普通人”不仅成功落地了数字孪生项目,还在公开平台上分享经验,形成了一股“去中心化”的技术普及浪潮,而背后的推动力,竟与一种名为Q-learning的强化学习算法密切相关。
从“高冷”到“接地气”:数字孪生的平民化实践
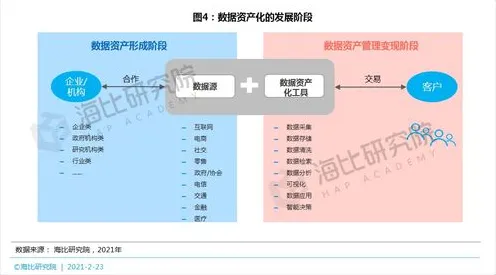
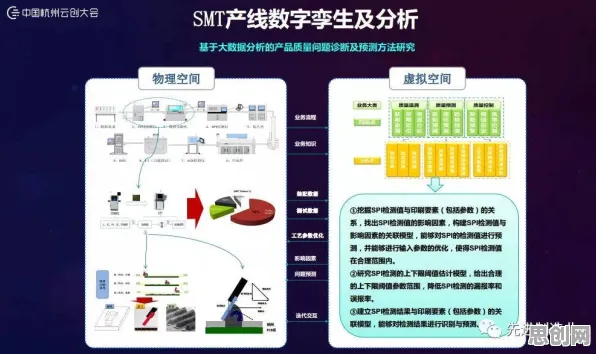
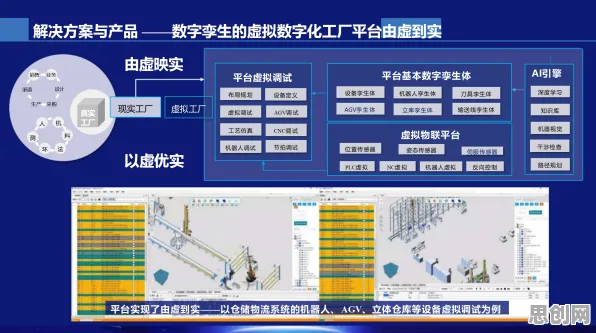
数字孪生技术,就是通过物理实体与虚拟模型的实时交互,实现生产过程的精准模拟、预测和优化,过去十年,这项技术被GE、西门子等巨头垄断,中小企业因成本高、技术门槛高而望而却步,但2026年的情况已大不相同。
在浙江宁波,一家年产值仅2亿元的注塑机配件厂“宏达精密”,成了行业里的“异类”,厂长王建军是机械专业出身,对编程一窍不通,却在2025年底带领团队用数字孪生技术优化了生产线,他们的做法很简单:在车间安装了20多个物联网传感器,采集设备温度、压力、振动等数据,再通过开源的数字孪生平台(如德国Fraunhofer研究所2024年发布的OpenDT)构建虚拟模型,当模型预测某台注塑机将在48小时后因模具磨损导致次品率上升时,系统会自动生成维修工单,并推荐最优的停机时间——既避免生产中断,又减少设备损耗。 2026年电力市场化与绿色电力及社会企业发展迅速,技术创新带来新突破
绿色认证与生物制药热度持续上升,相关领域迎来新发展 “我们没请外部专家,就靠车间老师傅的经验和平台自带的Q-learning算法。”王建军说,他提到的Q-learning,正是宏达精密成功的关键,这种算法不需要预先定义规则,而是通过“试错-奖励”机制让模型自主学习:当系统根据预测调整生产参数后,如果实际效果(如次品率下降)优于预期,算法会“这次决策;反之则调整策略,经过3个月的运行,宏达精密的设备综合效率(OEE)提升了12%,能耗降低了8%。
类似的案例在2026年并不少见,在广东东莞,90后创业者李婷的“智能螺丝厂”用数字孪生优化了分拣流程,她的团队只有5人,却通过Q-learning训练出的虚拟分拣员,将人工分拣的错误率从3%降至0.5%。“我们买不起昂贵的工业软件,就用开源工具和算法自己搭。”李婷说,“Q-learning的好处是,哪怕我们不懂数学模型,只要给它足够的数据,它就能找到最优解。”
Q-learning:让“小白”也能玩转数字孪生的“秘密武器”
为什么Q-learning能成为普通人实施数字孪生的“捷径”?这要从传统数字孪生技术的痛点说起。
2026年植物保护与机器人技术领域迎来新发展,相关应用不断深化 
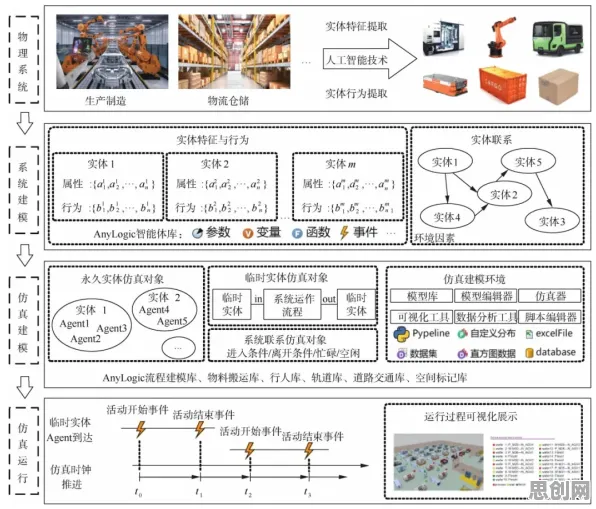
过去,构建数字孪生模型需要三步:1. 建立物理方程(如流体力学、热力学模型);2. 采集大量数据校准参数;3. 通过仿真验证模型准确性,这一过程不仅需要深厚的专业背景,还依赖昂贵的软件和算力,中小企业往往卡在第一步——他们缺乏理论建模的能力,也请不起专业团队。
Q-learning的出现改变了游戏规则,作为一种“模型无关”的强化学习算法,它不需要预先知道物理规律,而是通过与环境的交互(即“试错”)来学习最优策略,在数字孪生场景中,“环境”就是物理生产系统,“策略”则是如何调整参数(如温度、压力、速度)以优化目标(如产量、质量、能耗)。
以宏达精密的注塑机为例:传统方法需要建立复杂的热力学模型来预测模具磨损,而Q-learning只需做两件事:1. 记录历史数据(如不同温度下的次品率);2. 定义“奖励函数”(如次品率每降低1%得10分,能耗每增加1%扣5分),算法会通过不断尝试不同的温度设置,观察“奖励”变化,最终找到一个平衡点——既保证质量,又控制能耗。
“这就像教一个孩子玩游戏。”清华大学工业工程系教授陈明在2026年3月的《中国工业数字化白皮书》中解释,“孩子不需要知道游戏规则,只需要通过反复尝试,记住哪些动作能得分,哪些会扣分,Q-learning就是这样的‘孩子’,只不过它的‘记忆’能力远超人类。”
更重要的是,Q-learning的“学习”过程可以完全自动化,开源平台如OpenDT已经内置了Q-learning模块,用户只需上传数据、定义目标,算法就能自动运行,这大大降低了技术门槛——哪怕操作者不懂机器学习,也能通过“拖拽式”界面完成模型训练。

开源生态与社区支持:普通人实践的“基础设施”
本月关注会展经济与绿色研发及卫星导航系统发展动态,技术创新推动产业升级 如果说Q-learning是数字孪生平民化的“引擎”,那么开源生态和社区支持就是“燃料”,2026年的工业数字化领域,一个显著趋势是:越来越多的工具和资源正在向普通人开放。
以OpenDT为例,这款由德国Fraunhofer研究所主导开发的开源数字孪生平台,在2024年发布后迅速风靡全球,它不仅提供了Q-learning等强化学习算法的模板,还集成了3D可视化、数据清洗、模型部署等功能,更重要的是,OpenDT的社区里有来自全球的开发者、工程师和学者,他们分享案例、解答问题,甚至提供定制化代码。
“我遇到的问题,社区里总有人经历过。”李婷说,她的螺丝厂在优化分拣流程时,曾因传感器数据噪声大导致模型不稳定,她在OpenDT论坛发帖后,一位德国工程师建议她使用“滑动窗口平均法”预处理数据,问题很快解决。“这种即时反馈,是传统技术咨询公司给不了的。”
除了开源平台,政府和行业协会也在推动数字孪生的普及,2025年底,中国工信部发布了《中小企业数字孪生应用指南》,明确将Q-learning列为“低代码实现技术”,并提供了从数据采集到模型部署的全流程指导,各地政府设立了“数字孪生创新中心”,为中小企业提供免费的数据存储、算力支持和专家辅导。
“我们调研发现,70%的中小企业对数字孪生感兴趣,但担心成本和技术门槛。”工信部数字化推进司副司长张伟在2026年1月的新闻发布会上说,“通过推广Q-learning等轻量化技术,以及建设开源生态,我们希望让更多普通人敢用、会用数字孪生。”

实践者的真实声音:从“试试看”到“离不开”
数字孪生的平民化,不仅改变了技术实施的方式,也重塑了普通人对工业数字化的认知。
在江苏苏州,一家成立仅3年的“夫妻店”——“智造工坊”,用数字孪生优化了CNC加工中心的刀具管理,老板陈磊和妻子都是机械专业毕业,但此前从未接触过编程,他们通过OpenDT平台,用Q-learning训练了一个“刀具寿命预测模型”:系统根据刀具的切削次数、进给速度、材料硬度等数据,预测剩余寿命,并在寿命临近时自动提醒更换。
“一开始我们只是试试看,没想到效果这么好。”陈磊说,过去,他们靠经验判断刀具寿命,经常因提前更换造成浪费,或因更换过晚导致工件报废,数字孪生系统上线后,刀具成本降低了20%,加工效率提升了15%。“现在我们已经离不开它了,每次有新订单,第一件事就是更新模型参数。”
类似的“真香”体验在普通人中并不少见,在山东青岛,一家传统纺织厂的技术员刘芳,用数字孪生优化了织布机的张力控制,她通过Q-learning训练的模型,将布面瑕疵率从5%降至1.2%,被厂里评为“年度创新人物”。“以前觉得数字孪生是‘高大上’的东西,现在发现它就是解决实际问题的工具。”刘芳说,“就像手机里的APP,用熟了谁都能玩转。”
挑战与未来:平民化之路并非一帆风顺
尽管数字孪生的平民化趋势明显,但2026年的实践者们也面临着挑战。
数据质量,Q-learning依赖大量高质量数据,但许多中小企业的数据采集系统仍不完善。“我们的传感器经常掉线,数据断断续续的。”王建军说,“算法再聪明,也学不到有用的东西。”为此,宏达精密不得不投入资金升级物联网设备,并建立数据清洗流程。
人才短缺,虽然Q-learning降低了技术门槛,但数字孪生的实施仍需要跨学科知识——既要懂生产流程,又要会操作平台,李婷的团队曾因误解“奖励函数”设置,导致模型优化方向偏差,浪费了2周