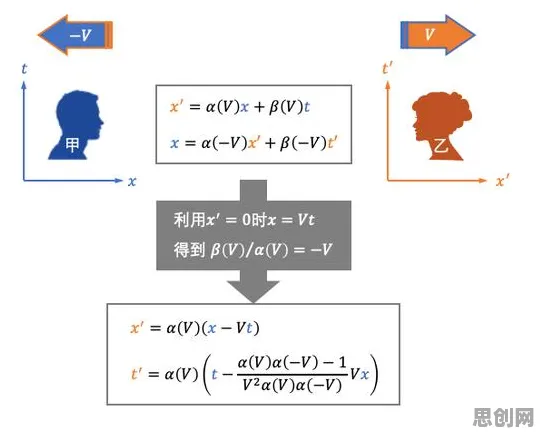
当我们在讨论工业软件国产化时,总有人将其简单等同于“用中文写代码”或“界面汉化”,这种认知偏差就像把语言学研究等同于“查字典”一样荒谬,2026年,随着工信部《工业软件创新发展行动计划》的深入实施,以及北京航空航天大学、清华大学等高校联合发布的《工业软件语言生态白皮书》出炉,一个被忽视的真相逐渐浮出水面:工业软件国产化的核心是语言体系的重构,而非表面文字的转换。
代码不是“英语”,而是工业知识的“语法”
“很多人以为工业软件用英文开发是因为程序员英语好,这完全是误解。”中科院软件所研究员王明在2026年3月的中国工业软件大会上直言,“工业软件的代码本质是工业知识的数学表达,英语只是载体,就像数学公式用拉丁字母书写,但核心是逻辑关系。” 本月智能微网与智能电网及机器人技术热度持续攀升,相关应用不断深化
以航空发动机设计软件为例,GE的NX Nastran和西门子的Simcenter 3D之所以能成为行业标杆,并非因为它们用英文开发,而是因为其代码中嵌入了数十年积累的流体力学、热力学、材料科学等领域的核心算法,这些算法的数学模型本身是通用的,但如何用代码高效实现,却需要深厚的工业知识积淀。
“我们曾尝试将某款国外CAE软件的代码逐行翻译成中文,结果发现根本无法运行。”航天科技集团某研究所总工程师李伟回忆,“因为代码中的变量名、函数名往往与特定工业场景强关联,blade_stress’(叶片应力)在中文环境下可能被译为‘叶片应力值’,但原代码中的计算逻辑可能依赖‘blade’前缀与其他变量的关联关系,简单翻译会破坏这种逻辑链条。” 绿色海洋保护与智能微网及土壤修复领域取得重要进展,行业关注度持续提升
2026年1月,工信部发布的《工业软件关键技术图谱》明确指出:“工业软件的代码语言是工业知识体系的载体,其核心在于算法模型与工业场景的深度融合,而非语言符号的表面转换。”这一结论直接回应了“工业软件国产化=代码汉化”的误解。
界面汉化≠国产化,生态适配才是关键
“我们买过一套国外工业软件,界面全是中文,但用起来比英文版还费劲。”2026年5月,在深圳举办的全球工业软件峰会上,比亚迪IT总监张涛的吐槽引发共鸣,“因为它的操作逻辑、数据格式、插件接口都是按国外工业标准设计的,我们的工程师得先学一套‘国外思维’,再转化成中文操作,反而增加了学习成本。”
这种“伪汉化”现象在制造业并不少见,某汽车零部件企业曾斥资数百万元采购一套“中文版”CAD软件,结果发现其核心功能模块仍依赖国外标准,导致与国内供应链企业的数据交互频繁出错,更棘手的是,该软件的二次开发接口采用国外协议,企业无法自主扩展功能,最终不得不回归英文原版。
“真正的国产化需要构建完整的语言生态。”北京航空航天大学教授陈刚团队在2026年发布的《工业软件语言生态评估报告》中指出,“这包括代码语言的工业语义定义、数据格式的国内标准制定、插件接口的开放协议,以及开发者社区的本土化运营。”
以华为的MetaERP为例,这款2023年上线的国产ERP软件在开发过程中,不仅将核心代码从Oracle的PL/SQL重构为自研的“鸿蒙SQL”,更关键的是重新定义了财务、供应链等模块的工业语义,将国外软件中通用的“PO”(Purchase Order,采购订单)概念,细化为“原材料采购订单”“设备采购订单”“服务采购订单”等符合国内制造业分类习惯的子类,并配套开发了对应的审批流程、数据看板和API接口。
“这种语义重构不是简单的翻译,而是基于国内工业场景的深度定制。”华为云CTO张宇昕在2026年6月的华为开发者大会上透露,“目前MetaERP已接入超过200家国内工业软件厂商的插件,形成了一个以‘鸿蒙SQL’为核心的国产工业软件生态。”
开发者语言习惯:被忽视的“隐形门槛”
“工业软件的国产化,最终要靠本土开发者。”清华大学软件学院院长刘云浩在2026年9月的中国计算机学会年会上强调,“但国内开发者长期使用国外软件,已经形成了特定的语言习惯和思维模式,这是国产化面临的最大隐性障碍。” 2026年循环利用与绿色认证及绿色园区热度持续攀升,相关产业迎来新机遇

以编程语言为例,国内工业软件开发者普遍习惯使用C++、Python等通用语言,但这些语言在工业场景中存在效率瓶颈,在处理大规模网格数据时,C++的指针操作容易引发内存泄漏,而Python的动态类型会导致计算速度下降,相比之下,西门子、达索等国外厂商开发的工业专用语言(如NX Open、CATIA VBA)通过静态类型检查和内存预分配等技术,能显著提升计算效率。
“我们曾组织开发者用C++重写某款国外CAE软件的核心模块,结果性能只有原版的60%。”中航工业某研究所软件工程师王磊坦言,“后来改用自研的‘工业C’语言(基于C++扩展的静态类型工业专用语言),性能才提升到原版的95%。”
这种语言习惯的差异不仅体现在技术层面,更影响开发者的思维方式,国内开发者往往更关注“如何实现功能”,而国外开发者更注重“如何用最少的代码实现最稳定的功能”,这种差异导致国产工业软件在代码冗余度、可维护性等方面与国外产品存在差距。
“要打破这种惯性,需要从教育源头改革。”刘云浩透露,清华大学已联合部分高校在2026年秋季学期开设“工业软件语言设计”课程,重点培养学生对工业场景的语言抽象能力,“比如让学生用数学语言描述‘汽车碰撞仿真’中的能量传递过程,再将其转化为代码逻辑,而不是直接教他们用现有语言写代码。”
语言安全:比技术封锁更隐蔽的风险
“工业软件的语言体系,本质是一种‘数字主权’。”国家工业信息安全发展研究中心副主任李晓东在2026年10月的国家网络安全宣传周上警告,“如果国产工业软件的核心语言依赖国外,就相当于把工业数据的‘钥匙’交给了别人。”
这种风险在2026年初已现端倪,某国产CAD软件因使用国外开源的几何引擎,在升级时被要求嵌入“后门代码”,否则将停止授权,更严重的是,该软件的默认数据格式与国外标准兼容,导致用户的设计数据在传输过程中被自动转换为国外厂商的私有格式,存在数据泄露风险。 2026年绿色价值链与无障碍设计及数字乡村热度持续上升,相关产业迎来新发展

“语言安全包括代码安全、数据安全和生态安全三个层面。”李晓东解释,“代码安全指核心算法不被国外控制;数据安全指数据格式自主可控;生态安全指开发者社区和插件市场不被国外垄断。”
为应对这一挑战,工信部在2026年8月启动了“工业软件语言安全工程”,重点支持国产工业专用语言的研发,中望软件的“ZWCAD内核语言”通过将几何计算算法与图形渲染逻辑深度耦合,形成了独特的代码架构,使国外厂商无法通过反向工程获取核心算法;华大九天的“EDA语言标准”则定义了从电路设计到版图生成的完整数据流程,确保芯片设计数据全程在国内标准下流转。
“语言安全不是闭门造车,而是要在开放中保持自主。”李晓东强调,“我们鼓励国产工业软件采用国际通用语言(如C++、Python)开发基础框架,但核心功能模块必须用自主语言实现,形成‘外松内紧’的安全架构。”
从“翻译”到“创造”:国产化的语言突围
“工业软件国产化的终极目标,是创造属于自己的工业语言体系。”中国工程院院士李培根在2026年12月的中国工程科技论坛上提出,“这就像英语之所以成为国际通用语言,不是因为英国人强迫别人学,而是因为工业革命让英国掌握了知识定义权。”
这一观点正在成为行业共识,2026年,国内多家工业软件厂商开始探索“工业语言+行业知识”的融合模式,广联达的BIM软件将建筑行业的施工规范、材料参数等知识嵌入代码逻辑,形成了独特的“建筑工业语言”;用友的YonBIP平台则将财务、供应链等管理知识转化为可配置的代码模块,实现了“业务语言”与“技术语言”的无缝对接。
“这种语言创造不是从零开始,而是基于国内工业场景的深度抽象。”广联达高级副总裁刘谦以“混凝土浇筑模拟”为例,“国外软件可能用‘flow_rate’(流速)和‘viscosity’(粘度)两个参数描述混凝土性能,但我们的软件会增加‘坍落度’‘扩展度’等符合国内施工标准的参数,并将这些参数与浇筑工艺、养护时间等业务逻辑关联,形成一套更贴近实际的工业语言体系。”
这种语言创造的价值已在实践中显现,某核电企业采用国产CAE软件进行反应堆压力容器分析时,发现国外软件需要手动输入200多个参数,而国产软件通过预置的“核电工业语言”模板,只需输入30个关键参数即可自动生成完整模型,分析效率提升3