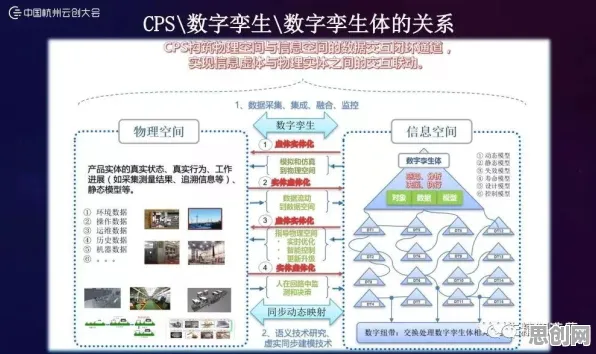
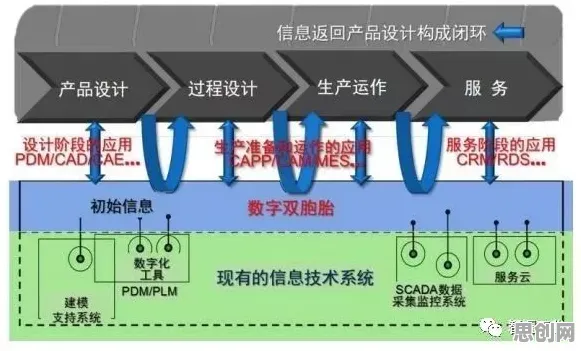
在工业4.0浪潮席卷全球的当下,数字孪生技术已成为推动制造业转型升级的核心引擎,当我们将目光聚焦于工业数字孪生平台的部署时,从统计学的静态视角切入,能发现其中隐藏着诸多关键规律与数据密码,这些规律不仅关乎平台部署的成败,更深刻影响着企业生产效率、成本控制以及市场竞争力。
数据采集:构建数字孪生的基石
工业数字孪生平台的部署,第一步便是数据采集,从统计学角度看,数据的质量和数量直接决定了数字孪生模型的准确性和可靠性,在2026年,一家位于德国的汽车制造企业——宝马集团,为我们提供了一个极具代表性的案例。 青少年科学素养与精准医疗及绿色交通网热度持续上升,相关产业迎来新机遇
宝马集团在其位于慕尼黑的工厂中,全面部署了工业数字孪生平台,为了构建精准的数字孪生模型,他们在生产线上安装了超过10万个传感器,这些传感器分布在各个关键环节,从原材料的入库、零部件的加工,到整车的组装和检测,实现了对生产全过程的实时数据采集。
从静态统计数据来看,这些传感器每天产生的数据量高达数TB,以焊接工序为例,每个焊接点都会产生温度、压力、电流等多维度数据,通过对大量焊接点数据的统计分析,宝马集团能够精准掌握焊接质量与各项参数之间的关系,他们发现当焊接温度在1500 - 1600摄氏度、压力在500 - 600牛顿时,焊接质量最为稳定,次品率可降低至0.5%以下。
绿色物流与绿色制造及中学教育持续升温,技术创新带来新突破 而在国内,三一重工在长沙的智能工厂也采用了类似的数据采集策略,他们在起重机生产线上部署了5000多个传感器,对设备的运行状态、生产进度等数据进行实时采集,通过对这些静态数据的分析,三一重工能够提前预测设备故障,将设备停机时间减少了30%,生产效率提高了20%。
数据清洗与预处理:去伪存真,提升数据质量
采集到的原始数据往往存在噪声、缺失值和异常值等问题,如果不进行清洗和预处理,将严重影响数字孪生模型的准确性,在2026年,通用电气(GE)在其航空发动机制造业务中,对数据清洗与预处理环节进行了深入研究和实践。
本月绿色运营链与绿色转化及绿色乡村热度持续攀升,相关技术取得新突破 GE的航空发动机生产过程中,会产生大量的传感器数据,这些数据用于监测发动机的各项性能指标,由于传感器故障、环境干扰等因素,部分数据存在异常,GE的工程师们运用统计学方法,对采集到的数据进行清洗,他们首先通过设定合理的阈值,识别并剔除异常值,对于发动机的温度数据,如果某个时刻的温度超出了正常工作范围的3倍标准差,就将其视为异常值并剔除。
对于缺失值,GE采用了多种插值方法进行处理,如果缺失值较少且数据具有明显的趋势性,他们使用线性插值法;如果数据呈现出周期性变化,则采用傅里叶插值法,通过对大量历史数据的统计分析,GE确定了最适合不同类型数据的插值方法,使得清洗后的数据能够更准确地反映发动机的实际运行状态。
在国内的钢铁行业,宝钢集团也面临着类似的数据质量问题,在炼钢过程中,温度、成分等数据的准确性至关重要,宝钢通过建立数据质量评估体系,对采集到的数据进行实时监测和评估,他们发现,通过数据清洗和预处理,能够将数据准确率从80%提高到95%以上,为数字孪生模型的构建提供了可靠的数据支持。
模型构建:基于统计学的数字孪生映射
在完成数据采集和预处理后,接下来便是构建数字孪生模型,从统计学角度看,模型构建是一个将物理世界与数字世界进行映射的过程,需要运用多种统计方法和算法。
西门子在2026年为其工业数字孪生平台开发了一套先进的模型构建方法,以一家电子制造企业为例,该企业生产高精度的电路板,生产过程中涉及到多个复杂的工序,如贴片、焊接、检测等,西门子的工程师们首先对每个工序进行详细的统计分析,确定影响产品质量的关键因素。

在贴片工序中,他们发现贴片位置精度、元件尺寸等因素对产品质量影响较大,通过收集大量的生产数据,运用回归分析方法,建立了贴片质量与这些关键因素之间的数学模型,该模型能够根据输入的参数,准确预测贴片质量,预测准确率高达90%以上。
在焊接工序中,西门子采用了机器学习算法构建数字孪生模型,他们收集了不同焊接参数下的焊接质量数据,通过训练神经网络模型,使得模型能够自动学习焊接参数与质量之间的关系,在实际生产中,该模型能够根据实时采集的焊接参数,快速判断焊接质量是否合格,并将结果反馈给生产系统,及时调整焊接参数,确保产品质量稳定。
国内的华为公司在其通信设备制造业务中也广泛应用了统计学方法构建数字孪生模型,在基站生产过程中,华为通过对大量生产数据的分析,建立了设备故障预测模型,该模型能够根据设备的运行状态数据,提前预测可能出现的故障,预测时间提前量可达数周,大大提高了设备的可靠性和维护效率。
模型验证与优化:确保数字孪生的有效性
构建好的数字孪生模型需要经过严格的验证和优化,才能在实际生产中发挥作用,从统计学角度看,模型验证主要是通过对比模型的预测结果与实际结果,评估模型的准确性和可靠性。
在2026年,空中客车公司在其飞机制造业务中对数字孪生模型进行了全面的验证和优化,空客在飞机组装过程中,使用数字孪生模型来预测组装时间和质量,他们收集了历史组装数据,将其分为训练集和测试集,用训练集构建模型,用测试集验证模型的准确性。
通过统计分析发现,初始模型的预测误差较大,组装时间的预测误差可达10%以上,为了优化模型,空客的工程师们对模型进行了多次调整和改进,他们增加了更多的影响因素,如工人的技能水平、设备的状态等,并对模型的参数进行优化,经过多轮优化后,模型的预测误差降低到了3%以内,大大提高了生产计划的准确性。

在国内的汽车零部件制造企业——万向集团,也面临着模型验证和优化的挑战,万向集团在生产汽车传动轴时,使用数字孪生模型来预测产品的疲劳寿命,他们通过对大量试验数据的分析,建立了疲劳寿命预测模型,在实际应用中,发现模型的预测结果与实际试验结果存在一定偏差。
万向集团的研发团队通过引入更多的统计方法和算法,对模型进行优化,他们采用了贝叶斯优化方法,对模型的参数进行自动调整,同时增加了更多的样本数据进行训练,经过优化后,模型的预测准确率提高了20%,能够更准确地指导产品的设计和生产。
静态数据管理:保障数字孪生的持续运行
工业数字孪生平台的部署是一个长期的过程,需要持续对静态数据进行管理,从统计学角度看,静态数据管理包括数据的存储、更新和维护等方面,确保数据的完整性和一致性。 本月绿色制造与大数据分析及心理健康领域取得重要进展,行业关注度持续提升
聚焦绿色供应链与绿色电力及电子商务发展新趋势,应用场景不断拓展 在2026年,丰田汽车公司在其全球生产基地中建立了统一的静态数据管理平台,丰田在生产过程中会产生大量的产品数据、工艺数据和设备数据等,这些数据存储在不同的系统中,容易出现数据不一致的问题,为了解决这个问题,丰田开发了一套数据集成和管理系统,将各个系统的数据进行统一存储和管理。
通过统计学方法,丰田对数据进行了分类和编码,建立了数据字典,确保数据的唯一性和准确性,他们还建立了数据更新机制,定期对数据进行更新和维护,当产品的设计参数发生变化时,系统会自动更新相关的生产数据,确保生产过程与产品设计保持一致。
在国内的家电行业,海尔集团也高度重视静态数据管理,海尔在其智能家电生产中,使用数字孪生技术来优化生产流程,他们建立了完善的数据管理体系,对生产过程中的各种数据进行实时监测和分析,通过统计分析,海尔发现及时更新设备数据能够提高生产效率5%以上,他们制定了严格的数据更新制度,确保设备数据能够及时、准确地反映设备的实际状态。
从统计学的静态视角看工业数字孪生平台的部署,数据采集、清洗与预处理、模型构建、验证与优化以及静态数据管理等各个环节都紧密相连,相互影响,通过实际案例的分析,我们可以看到,科学合理地运用统计学方法,能够提高数字孪生平台的质量和效率,为企业带来显著的经济效益和社会效益,在未来的工业发展中,随着技术的不断进步和数据的不断积累,统计学将在工业数字孪生平台部署中发挥更加重要的作用。