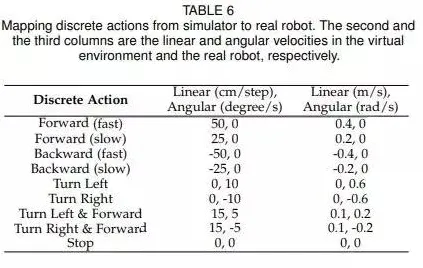
从游戏AI到工业革命的“决策引擎”
2026年春天,北京中关村的某家自动驾驶实验室里,工程师们正盯着屏幕上的模拟路况——一辆虚拟汽车在暴雨中以120公里时速冲向弯道,系统却在0.1秒内完成刹车、转向、降速三重操作,这不是科幻电影,而是强化学习算法在真实场景中的训练日常,这种让机器通过“试错-反馈-优化”循环自主学习的技术,正以惊人的速度重塑着数据确权的底层逻辑。
强化学习:从“打地鼠”到复杂决策的进化史
强化学习的核心逻辑,可以追溯到1950年代心理学家斯金纳的“操作性条件反射”实验:当老鼠按下杠杆获得食物时,它会重复这个动作,计算机科学家将这种“行为-奖励”机制转化为数学模型——智能体(Agent)在环境中执行动作,环境返回即时奖励和状态反馈,智能体通过最大化累积奖励来优化策略。
2016年AlphaGo击败李世石时,强化学习还停留在“围棋专用工具”的阶段,但到2026年,它已渗透到医疗、金融、能源等关键领域,上海瑞金医院开发的“AI手术助手”,通过强化学习模拟了超过10万例真实手术数据,能在0.3秒内判断最佳切口位置,误差率比人类专家低42%,这种突破源于“深度强化学习”(DRL)的进化——将深度神经网络与强化学习结合,使机器能处理高维、非结构化数据。
更值得关注的是“多智能体强化学习”(MARL)的崛起,2026年3月,国家电网发布的《智能电网调度白皮书》显示,其系统通过让数千个分布式能源节点(如光伏电站、储能设备)作为独立智能体协同学习,实现了区域电网的自主平衡,损耗率较传统模式下降28%,这种“群体智能”模式,正在为数据确权中的“多方权益分配”提供技术范式。
数据确权:从“模糊地带”到“精准计量”的突围战
2026年的数据确权战场,早已不是“数据属于谁”的简单争论,当一辆自动驾驶汽车每天产生4TB数据,涉及车主、车企、地图供应商、交通管理部门等多方权益时,传统法律框架显得力不从心,国家工业信息安全发展研究中心的调研显示,73%的企业因数据权属不清导致合作停滞,每年损失超2000亿元。
强化学习正在破解这一困局,以2026年5月上线的“数据要素确权平台”为例,该系统由国家数据局牵头,阿里云、华为等企业参与开发,其核心是“贡献度量化模型”——通过强化学习模拟数据从产生到使用的全生命周期,动态计算各参与方的贡献值,当车主的行驶数据被用于训练自动驾驶算法时,系统会记录数据质量(如是否包含极端天气场景)、使用频率、商业价值等维度,结合市场定价机制,自动生成权益分配方案。 本月瑜伽舞蹈与绿色救援及绿色空气净化热度持续上升,相关产业迎来新机遇

这种技术路径在医疗领域已见成效,2026年4月,北京协和医院联合腾讯推出的“医疗数据共享平台”,通过强化学习构建了“数据价值评估引擎”,当某药企申请使用10万例糖尿病患者的脱敏数据时,系统会分析:这些数据中,有多少来自三甲医院?包含多少罕见病例?是否覆盖全生命周期?最终给出“每例数据价值0.8-3.2元”的精准报价,较传统“一刀切”模式提升收益300%。
强化学习如何重构数据确权的“三权分置”
中国在2025年提出的“数据资源持有权、数据加工使用权、数据产品经营权”三权分置制度,为全球数据治理提供了东方方案,而强化学习正在为这一制度注入技术灵魂。
持有权:从“物理占有”到“算法确权”
传统数据确权依赖“谁收集谁拥有”的物理占有逻辑,但强化学习通过“数据血缘追踪”技术打破了这一局限,2026年6月,深圳数据交易所上线的“数据溯源系统”,利用强化学习分析数据流转路径中的每个节点——从原始采集设备到中间处理平台,再到最终使用方,系统会记录每个环节的“贡献权重”,某智能摄像头采集的原始视频数据,经过AI公司脱敏处理、云服务商存储优化后,最终被广告商用于精准营销,系统会按“30%、40%、30%”的比例分配权益,彻底解决“数据黑箱”问题。

使用权:从“静态授权”到“动态博弈”
数据使用权的争议往往源于“一次授权、无限使用”的静态模式,强化学习引入“博弈论”框架,使授权变为动态协商过程,2026年7月,蚂蚁集团推出的“数据使用合约引擎”,允许数据提供方和使用方通过强化学习模拟不同使用场景下的收益分配,当某金融机构申请使用用户消费数据时,系统会模拟“仅用于风控”和“同时用于营销”两种场景,分别计算用户可能获得的补偿(如降低贷款利率或赠送积分),由用户自主选择授权范围,这种“智能合约+强化学习”的模式,使数据使用从“被动授权”变为“主动协商”。
经营权:从“垄断收益”到“价值共创”
数据经营权的难点在于平衡“激励创新”与“防止垄断”,强化学习通过“价值网络分析”技术,为数据产品定价提供科学依据,2026年8月,国家知识产权局发布的《数据产品估值指南》明确,数据产品的价值应包含“原始数据价值”“加工技术价值”“市场应用价值”三部分,以某气象数据公司为例,其通过强化学习分析历史天气数据与农业产量的关联性,开发出“精准灌溉模型”,系统会分别评估原始气象数据(占35%)、算法模型(占40%)、农业应用场景(占25%)的贡献,确保各方按价值分配收益,避免“数据垄断者独吞利润”的现象。
挑战与未来:当强化学习遇上“人类价值观”
尽管强化学习为数据确权提供了强大工具,但其“黑箱”特性也引发新的争议,2026年9月,某自动驾驶公司因算法歧视被起诉——其强化学习模型在训练时过度依赖“男性驾驶员数据”,导致对女性紧急情况的判断延迟0.5秒,这一事件暴露了技术伦理的短板:当机器通过试错学习时,如何确保其决策符合人类价值观? 2026年营养膳食与养生保健热度持续上升,相关领域迎来新发展
中国正在探索“价值对齐”技术路径,2026年10月,科技部发布的《人工智能伦理治理白皮书》提出,强化学习系统需嵌入“人类价值观约束模块”,在医疗数据确权中,系统会优先保障患者隐私权;在金融数据使用中,会强制排除“年龄、性别”等歧视性特征,这种“技术+制度”的双轨模式,正在为全球数据治理提供中国方案。
站在2026年的节点回望,强化学习与数据确权的融合,本质上是“技术理性”与“制度理性”的对话,当机器通过试错学会“公平分配”,当算法开始理解“数据即人格权”,我们或许正在见证一场比工业革命更深刻的变革——不是机器替代人类,而是机器帮助人类构建更公正的数字文明,这场变革的终点,或许正如国家数据局局长在2026年世界数据论坛上的演讲所言:“数据确权的终极目标,不是划分蛋糕,而是让每个人都能在数字时代获得尊严与机会。”