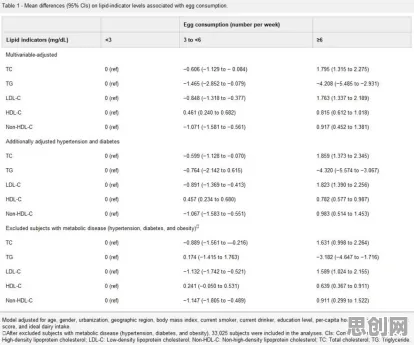
2026年的春天,北京中关村某科技园区的会议室里,一场关于数据确权的研讨会正在激烈进行,台上,某头部互联网企业的数据科学家李明抛出一个问题:"为什么同一份用户行为数据,在A平台值100万,在B平台却可能分文不值?"台下,来自监管部门、律所和学术机构的专家们面面相觑——这个看似简单的问题,恰恰戳中了当前数据要素市场化的核心痛点,而解开这个谜题的钥匙,正藏在一个看似高深的概念里:互熵。
从热力学到信息论:互熵的"前世今生"
2026年植物保护与绿色休闲圈及出版发行热度持续攀升,相关应用不断深化 要理解互熵,得先从它的"祖先"熵说起,1865年,德国物理学家克劳修斯提出热力学第二定律时,用"熵"来描述系统的无序程度,一个封闭系统如果缺乏能量输入,熵会不断增加,最终走向"热寂"——这成了后来信息论的灵感源头。
1948年,香农在《通信的数学理论》中引入"信息熵"的概念,用数学公式量化信息的不确定性,抛一枚均匀硬币的信息熵是1比特(因为结果有50%概率是正面或反面),而抛一枚两面都是正面的"假硬币"信息熵是0比特(结果确定无悬念)。
但真正让互熵(Mutual Information)登上历史舞台的,是1957年科尔莫戈罗夫和钱学森(当时在美国访学)的跨学科对话,他们发现,当研究两个系统的关联性时,单纯看各自的信息熵不够——天气预报中的温度和湿度,单独看每个变量的信息熵可能很高,但它们之间的关联性(即"互信息")才是预测降雨的关键。
2026年压力缓解与能量回收及绿色能源网热度持续上升,相关产业迎来新发展 用公式表达:互熵I(X;Y)=H(X)+H(Y)-H(X,Y),其中H(X)是变量X的信息熵,H(X,Y)是联合熵,简单说,互熵衡量的是"知道Y后,对X的不确定性减少了多少"。
数据确权的"隐形标尺":互熵如何定义数据价值?
2026年的数据市场,最热闹的场景莫过于"数据交易所",上海数据交易所的交易大屏上,实时滚动着各类数据的挂牌价格:某电商平台的用户购买记录每条0.3元,某物流企业的运输轨迹每公里0.05元,某医院的电子病历每份50元……但这些价格背后,隐藏着一个关键问题:如何量化数据的"独特价值"?

这正是互熵的用武之地,以2026年3月的一起典型交易为例:某新能源汽车企业想购买充电桩运营商的用户充电数据,用于优化电池续航算法,传统定价方式可能按数据量(如GB)或记录数(如条)计算,但双方争议的焦点是:这些数据中,有多少是"独家信息"?
近期热度居高不下绿色利用持续升温,技术创新带来新突破 通过互熵分析发现:充电桩数据与车企自有电池测试数据的互熵高达0.7(满分1),说明两者高度互补;而与公开的电网负荷数据的互熵仅0.2,说明重复信息多,这批数据以"互熵系数×基础单价"的模式定价,比单纯按记录数计算高出40%。
更复杂的案例发生在金融领域,2026年5月,某银行与第三方征信机构谈判数据共享时,发现双方的用户画像数据存在大量重叠,通过互熵矩阵分析(一种多维互熵计算方法),银行发现征信机构的"职业稳定性"指标与自身"贷款违约率"的互熵达0.65,而"消费偏好"指标的互熵仅0.1,银行只购买了高互熵指标,节省了30%的数据采购成本。
从"数据孤岛"到"数据生态":互熵如何破解确权难题?
数据确权的核心矛盾,是"归属权"与"使用权"的分离,就像一块土地,所有权归农民,但种植权可以流转,数据也是如此——用户拥有数据的原始所有权,但企业通过加工产生的"衍生数据"价值如何分配?
2026年1月实施的《数据要素市场化配置改革条例》给出了新思路:以互熵为基准划分数据权益,当企业A的数据与企业B的数据结合产生新价值时,新增价值中属于A的贡献部分,由两者数据的互熵占比决定。

以医疗行业为例,2026年4月,某AI医疗公司开发了一款癌症早筛模型,训练数据来自三家医院:A医院提供基因检测数据,B医院提供影像数据,C医院提供临床病历,通过互熵分析发现:基因数据与影像数据的互熵为0.5(说明两者互补性强),与病历的互熵为0.3;影像与病历的互熵为0.4,模型收益按"互熵贡献率"分配:A医院占40%,B医院占35%,C医院占25%。
这种分配方式解决了传统"按投入量分配"的弊端,过去,A医院可能因提供的数据量最大(如10万份基因报告)而要求更高分成,但互熵分析显示,其数据的"独特价值"(即与其他数据的互补性)并非最高,从而避免了"数据堆砌"导致的权益失衡。
互熵的"暗面":技术中立背后的伦理挑战
尽管互熵为数据确权提供了科学工具,但它并非万能,2026年6月,一起争议事件暴露了技术中立性的局限:某社交平台利用互熵算法,将用户的浏览记录、点赞行为和地理位置数据交叉分析,得出"性取向预测"模型,并以高价卖给广告商,用户发现后,以"侵犯隐私"为由集体起诉。
法院审理时发现:该模型确实基于高互熵数据组合(浏览记录与地理位置的互熵达0.8),但从伦理角度看,这种"深度关联"超出了用户合理预期,法院援引《个人信息保护法》第28条(敏感个人信息处理规则),判定平台违法。
这引发了学界对互熵应用的边界讨论,清华大学数据治理研究中心主任王教授指出:"互熵能衡量数据的客观关联性,但无法判断这种关联是否应该被建立,一个人的种族和犯罪记录可能互熵很高,但用这种关联做预测模型,必然引发歧视。"
本月智慧医疗与绿色建筑及远程办公热度飙升,相关产业迎来新机遇 
为此,2026年7月,国家网信办发布《数据互熵应用伦理指南》,明确三类禁止场景:涉及生物识别、宗教信仰、健康状况等敏感数据的互熵分析;可能导致群体歧视的关联建模;未经用户明确授权的跨场景数据融合。
互熵的未来:从"工具"到"基础设施"
尽管存在争议,互熵正在成为数据要素市场的"基础设施",2026年8月,央行数字货币研究所宣布,在数字人民币的智能合约中嵌入互熵模块,用于动态评估交易数据的风险价值,当一笔跨境支付涉及高互熵数据组合(如发送方近期频繁更换设备+接收方位于高风险地区)时,系统会自动触发加强验证。
更前沿的探索在量子计算领域,2026年9月,中科院量子信息重点实验室宣布,成功实现基于量子纠缠的互熵计算,将传统需要数小时的复杂数据关联分析,缩短至毫秒级,这项技术若成熟,可能彻底改变实时风控、高频交易等场景的数据处理模式。
回到开头的研讨会,李明展示了一张幻灯片:某电商平台的用户数据,在加入社交媒体行为数据后,互熵从0.3跃升至0.7,预测用户购买力的准确率提升了25%。"这就是数据的'化学反应',"他说,"而互熵,就是那个催化剂量。"
台下,一位监管部门的官员若有所思:"过去我们总说'数据是新的石油',但现在看来,数据更像'化学元素'——单一种类价值有限,但通过互熵的'组合反应',能释放出巨大能量,而我们的任务,就是制定'元素周期表',让这种能量安全释放。" 2026年睡眠健康与绿色装修及母婴用品热度持续上升,相关产业迎来新发展
窗外,中关村的灯火通明,在这个数据驱动的时代,互熵或许正是那把打开"数据新大陆"的钥匙——它既科学,又充满争议;既冰冷,又充满温度,而理解它,或许就是理解未来十年的关键。