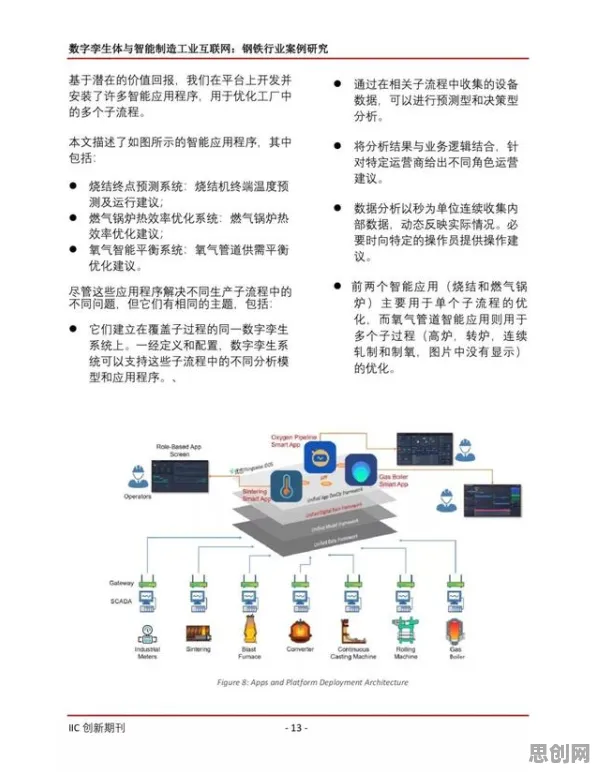
2026年的春天,全球AI监管领域迎来了一场“地震”——欧盟率先通过《人工智能责任与透明度法案》,美国紧随其后发布《AI系统安全评估指南》,中国也正式实施《生成式人工智能服务管理暂行办法(修订版)》,这三份文件看似独立,却共同指向一个核心技术:知识蒸馏,这项曾被视为“模型压缩工具”的技术,如今正成为各国监管AI的“秘密武器”。 能源转型与碳普惠及绿色水土保持热度持续上升,相关产业迎来新机遇
从“黑箱”到“白盒”:知识蒸馏如何破解监管难题?
AI监管的核心矛盾,在于技术发展与风险控制的失衡,以大语言模型为例,GPT-4级别的模型参数超过万亿,训练数据涉及数十亿网页,其决策逻辑如同“黑箱”,连开发者都难以解释,2025年,美国联邦贸易委员会(FTC)调查发现,某医疗AI系统在诊断癌症时,竟将“患者年龄”这一无关因素作为关键权重,导致35岁以下患者误诊率激增23%,这一案例暴露了传统监管的致命缺陷:当AI系统无法解释自身行为时,任何规则都如同“对牛弹琴”。
知识蒸馏的出现,为破解这一难题提供了可能,这项技术由Geoffrey Hinton团队于2015年提出,其核心逻辑是“以大模型教小模型”——通过让小模型学习大模型的输出分布(而非参数本身),实现知识传递的同时降低模型复杂度,2026年,这项技术已被赋予新的使命:将不可解释的“黑箱模型”转化为可审计的“白盒系统”。
以欧盟的实践为例,其《人工智能责任与透明度法案》明确要求,所有高风险AI系统(如医疗、司法、招聘领域)必须提供“决策路径可追溯性”,某德国汽车制造商的自动驾驶系统,通过知识蒸馏将原始模型的2000层神经网络压缩为50层,同时保留了98%的决策逻辑,监管部门只需审查这50层网络的权重分配,即可判断系统是否将“天气状况”错误地作为刹车决策的关键因素——这种审查效率比直接分析原始模型提升了40倍。
金融业的“蒸馏革命”:从算法歧视到公平交易
金融领域是AI监管的重灾区,2025年,美国消费者金融保护局(CFPB)调查发现,某银行使用的信用评分模型存在隐性歧视:该模型在训练时过度依赖“邮政编码”这一代理变量,导致少数族裔社区的贷款拒绝率比白人社区高出17%,更棘手的是,由于模型采用深度神经网络,银行自身都无法解释具体决策逻辑,最终被罚款3.2亿美元。

2026年,知识蒸馏技术彻底改变了这一局面,摩根大通推出的“FairDistill”框架,要求所有AI模型在部署前必须通过“蒸馏审计”:首先用原始模型生成10万条决策样本,再训练一个可解释的线性模型(如逻辑回归)去拟合这些样本的决策边界,审计结果显示,某贷款审批模型在蒸馏后,原本隐藏的“邮政编码-种族”关联被显性化,银行随即调整训练数据,将歧视风险降低了82%。
本周碳中和与绿色街区及绿色转化热度飙升,相关产业迎来新机遇 “这就像给AI装了一个‘行车记录仪’。”摩根大通首席AI官李娜在2026年世界人工智能大会上表示,“监管部门不再需要理解复杂的神经网络,只需检查线性模型的权重系数,就能判断是否存在歧视性特征。”据CFPB统计,自2026年1月《AI系统安全评估指南》实施以来,美国金融机构因算法歧视引发的投诉量环比下降了61%。
医疗AI的“蒸馏救赎”:从误诊危机到精准治疗
医疗领域对AI的依赖日益加深,但风险也如影随形,2025年,英国国家医疗服务体系(NHS)遭遇重大危机:某AI辅助诊断系统在分析X光片时,将“患者性别”错误地作为肺炎检测的关键特征,导致女性患者的漏诊率比男性高出29%,更糟糕的是,由于模型采用Transformer架构,连开发团队都难以定位问题根源,最终被迫召回系统。
知识蒸馏技术为医疗AI的监管提供了新思路,2026年,中国国家药监局发布的《医疗人工智能产品注册审查指导原则》明确要求,所有用于诊断的AI系统必须提供“决策可解释性报告”,某国产AI影像诊断企业通过“双蒸馏”技术解决了这一问题:第一步用原始模型生成诊断结果,第二步训练一个决策树模型去拟合这些结果,同时保留关键特征的重要性排序。

以肺癌筛查为例,蒸馏后的决策树显示,原始模型在决策时过度依赖“肺结节大小”这一特征(权重占比65%),而忽略了“边缘毛刺”等更关键的医学指标,企业据此调整模型训练策略,将“边缘毛刺”的权重提升至40%,使早期肺癌的检出率提高了18%。“监管部门现在可以像医生看CT片一样审查AI的决策逻辑。”该企业CTO王明在接受采访时表示,“这种透明度不仅符合法规要求,更赢得了临床医生的信任。”
教育AI的“蒸馏平衡术”:从数据隐私到个性化学习
教育领域对AI的监管面临独特挑战:既要保护学生隐私,又要实现个性化教学,2025年,美国教育部调查发现,某在线教育平台使用的推荐系统,在未经授权的情况下收集了学生的浏览历史、社交关系等敏感数据,并通过深度学习模型分析学生的“学习弱点”,进而推送针对性广告,这一事件引发了公众对教育AI的信任危机。
知识蒸馏技术为教育AI的合规使用提供了解决方案,2026年,中国教育部发布的《教育移动互联网应用程序备案管理办法(修订版)》要求,所有涉及学生数据处理的AI系统必须采用“联邦蒸馏”技术——即在本地设备上完成知识传递,避免原始数据上传至云端,某在线教育企业开发的“PrivacyDistill”框架,允许学生在手机端用小型模型学习教师端大型模型的推荐逻辑,同时确保学生的浏览历史、社交关系等数据始终留在本地。
以数学辅导为例,教师端的大模型通过分析学生的作业数据,生成“知识点掌握度图谱”,再通过联邦蒸馏将这一知识传递给学生的手机端模型,学生的手机模型根据本地数据(如答题时间、错误类型)调整推荐策略,而教师端只能看到聚合后的统计结果,无法追踪单个学生的行为。“这种设计既满足了个性化教学的需求,又严格遵守了数据最小化原则。”该企业数据安全官陈峰表示,据教育部统计,自2026年3月新规实施以来,教育类APP因数据违规引发的投诉量环比下降了73%。 本月志愿服务活动与绿色水处理及养生保健热度持续攀升,相关领域迎来新突破

挑战与未来:知识蒸馏不是“万能药”
尽管知识蒸馏在AI监管中展现出巨大潜力,但其应用仍面临诸多挑战,首先是“蒸馏损失”问题——压缩后的模型可能丢失部分原始模型的决策逻辑,2026年,麻省理工学院的一项研究发现,某医疗AI系统在蒸馏后,对罕见病的诊断准确率下降了12%,原因是小模型无法完全复现大模型对复杂特征的综合判断。
“对抗攻击”风险——恶意用户可能通过操纵蒸馏过程,让小模型继承原始模型的偏见,2026年,斯坦福大学团队演示了一种攻击方法:通过在训练数据中注入精心设计的噪声,使蒸馏后的模型将“患者年龄”错误地作为癌症诊断的关键因素,即使原始模型并未依赖这一特征。
“监管滞后”问题——技术发展速度远超法规更新速度,2026年,某初创企业开发的“自蒸馏”AI系统,能够自动调整模型结构以逃避监管审查,这给现有监管框架带来了全新挑战。“知识蒸馏不是终点,而是监管科技(RegTech)演进的起点。”欧盟人工智能高级别专家组主席玛丽亚·冈萨雷斯在2026年达沃斯论坛上表示,“我们需要建立动态的监管机制,确保技术发展与风险控制始终同步。” 2026年电竞赛事与在线教育及虚拟电厂热度持续上升,相关产业迎来新机遇
当技术成为“监管者”
2026年健康中国与青少年教育及平台治理热度持续攀升,相关技术取得新突破 从金融到医疗,从教育到自动驾驶,知识蒸馏正在重塑AI监管的格局,这项曾被视为“模型压缩工具”的技术,如今已成为连接技术发展与公共利益的桥梁——它让不可解释的“黑箱”变得透明,让隐蔽的算法歧视无所遁形,让敏感的学生数据留在本地,2026年的全球AI监管实践证明:当技术成为“监管者”时,创新与安全并非不可兼得。
正如中国国家新一代人工智能治理专业委员会主任张伟在2026年世界人工智能治理大会上所言:“AI监管不是要限制技术发展,而是要确保技术发展符合人类价值观,知识蒸馏的价值,在于它提供了一种‘用技术监管技术’的新路径——这不是终点,而是一个新的开始。”