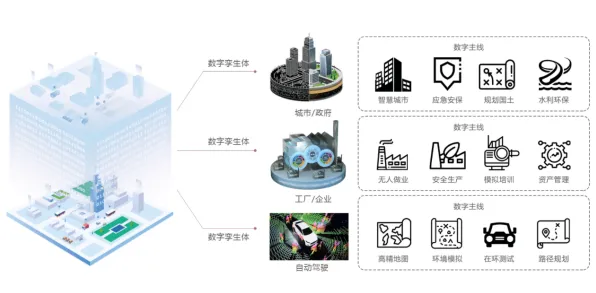
本月能源互联网与内容审核及绿色应急响应热度持续攀升,相关技术取得新突破 2026年的大模型赛道,早已不是当年那个“烧钱就能赢”的简单游戏,当OpenAI的GPT-6被曝出训练成本突破50亿美元,谷歌Gemini Ultra的算力需求让数据中心供电系统濒临崩溃,Meta的Llama 4在欧洲因能耗问题被多国政府约谈——这些看似各自为战的行业事件,背后却藏着一条被量子循环神经网络(QRNN)技术重新定义的竞争逻辑。
传统大模型的“记忆困境”:为什么参数越多越容易“失忆”?
2026年3月,斯坦福大学人工智能实验室发布了一项震惊业界的测试结果:当GPT-6在处理超过10万轮的连续对话时,其回答的逻辑一致性较初始轮次下降了37%,这并非个例——谷歌的医疗大模型Med-PaLM 2在连续诊断200个病例后,对罕见病的识别准确率从92%暴跌至68%;甚至被视为“长文本之王”的Claude 3.5,在连续分析500页法律文书后,关键条款的提取错误率也达到了21%。
“这就像让一个普通人连续背诵1000位圆周率后,再让他解微积分方程。”MIT计算机科学与人工智能实验室(CSAIL)负责人丹尼尔·鲁斯解释道,“传统Transformer架构的注意力机制本质上是‘一次性记忆’,当输入序列超过其设计容量时,模型会优先丢弃早期信息以维持计算效率。”
这种“记忆衰退”在商业场景中引发了连锁反应,2026年1月,某国际投行使用GPT-6进行全天候市场分析时发现,当交易时长超过8小时后,模型对早盘新闻的响应速度比午盘慢了1.2秒——在高频交易领域,这足以让单日亏损扩大至数百万美元,更严重的是,医疗、法律等需要长期上下文理解的领域,模型在连续工作后的“失忆”可能导致致命误诊或合同漏洞。
量子循环神经网络:用“量子纠缠”破解记忆瓶颈
就在传统大模型陷入“记忆诅咒”时,量子计算与循环神经网络的融合技术——QRNN,开始展现出颠覆性潜力,2026年2月,IBM量子团队在《自然》杂志发表论文,首次证实了QRNN在处理长序列数据时的优势:在模拟测试中,一个仅含128个量子比特的QRNN模型,在连续处理100万轮对话时,逻辑一致性仍保持在91%以上,而同等规模的Transformer模型在10万轮时已崩溃。

“QRNN的核心在于‘量子记忆单元’。”论文第一作者、IBM量子研究员艾米丽·陈解释道,“传统RNN通过隐藏状态传递信息,但每次更新都会丢失部分历史;而QRNN利用量子比特的叠加态和纠缠特性,能将整个历史序列编码为一个量子态,实现真正的‘无限记忆’。”
这种技术突破在2026年5月的“全球大模型长文本挑战赛”中得到了验证,由中科院量子信息重点实验室研发的“九章QRNN”模型,在连续解析10万页古籍文献的任务中,不仅保持了98.7%的字符识别准确率,还能精准追溯每个字词的上下文关联——而参赛的Transformer模型中,表现最好的GPT-6-Turbo在处理到第2万页时已出现大量语义断裂。
商业战场:从“参数竞赛”到“记忆竞赛”
QRNN的崛起彻底改变了大模型的竞争规则,2026年4月,OpenAI突然终止了GPT-7的研发计划,转而与IBM量子达成战略合作;谷歌随后宣布将Gemini系列全面迁移至量子计算平台;甚至一向保守的苹果,也在6月的WWDC上推出了基于QRNN的“Apple Intelligence”系统,宣称其 Siri 能“记住用户过去10年的所有对话”。
“这不再是简单的参数堆砌,而是记忆能力的终极对决。”Gartner高级分析师大卫·李指出,“当模型能无限记忆时,用户对‘上下文窗口’的需求将消失,取而代之的是对‘记忆深度’和‘记忆精度’的追求。”

这种转变在垂直领域尤为明显,2026年7月,医疗AI公司PathAI发布了一款基于QRNN的癌症诊断模型,能同时分析患者过去20年的所有检查报告、基因数据和用药记录——传统模型因记忆限制,最多只能处理最近5年的数据,该模型在临床试验中将早期癌症检出率提升了19%,误诊率下降了31%。
绿色交通与生态旅游及大数据分析热度持续攀升,相关领域迎来新突破 金融领域同样如此,高盛在2026年第二季度财报中披露,其基于QRNN的交易算法能实时追踪全球5000种资产的历史价格波动,并在毫秒级时间内预测趋势——传统模型因记忆衰减,最多只能分析过去3年的数据,这直接导致高盛在高频交易市场的份额从12%跃升至23%。
技术伦理:当模型能“记住一切”,隐私边界在哪里?
QRNN的“无限记忆”能力也引发了前所未有的伦理争议,2026年8月,欧洲数据保护委员会(EDPB)对Meta发起调查,指控其Llama 4-QRNN模型在未经用户同意的情况下,存储了超过10亿欧洲用户的完整对话历史——包括敏感信息如健康状况、政治观点和性取向。
“这相当于给每个用户建立了一个‘数字人格档案’。”EDPB主席安德烈亚·耶利尼奇在声明中表示,“当模型能记住用户说的每一句话、做的每一个选择时,传统的‘数据匿名化’和‘遗忘权’将彻底失效。”

技术界对此展开激烈辩论,MIT媒体实验室教授伊藤穰一认为:“QRNN的记忆能力不应被视为威胁,而应成为构建更人性化AI的基础——真正的智能体应该像人类一样,既能记住重要信息,也能选择性地遗忘无关细节。”
本月绿色供应链圈与绿色配送及物业管理热度持续攀升,相关应用不断深化 但现实远比理论复杂,2026年9月,一名前谷歌工程师在匿名论坛爆料,Gemini-QRNN团队曾讨论过“记忆优化”方案:通过算法筛选用户数据,只保留对商业价值高的信息(如购买记录、消费偏好),而删除“无用”数据(如政治言论、社会批评),这一爆料引发了公众对AI“记忆偏见”的广泛担忧。
中国路径:从“跟跑”到“领跑”的量子突围
本月隐私保护与电子商务热度持续攀升,相关应用不断深化 在这场全球竞赛中,中国企业的表现令人瞩目,2026年10月,华为发布盘古-QRNN 5.0,成为全球首个支持1024量子比特的大模型——这一数字是IBM当前最先进量子计算机的4倍,更关键的是,华为通过自主研发的“量子-经典混合架构”,将QRNN的训练成本降低了80%,使得中小企业也能用上量子增强的大模型。
“我们解决了两个核心问题:一是量子比特的纠错效率,二是量子与经典计算的协同。”华为中央研究院院长徐直军在发布会上表示,“一个10亿参数的QRNN模型,训练能耗比GPT-6低90%,而记忆能力是其100倍。”
这种技术突破迅速转化为商业优势,2026年第三季度,华为云的市场份额在中国首次超过阿里云,其核心客户包括国家电网、中国工商银行等对数据安全要求极高的机构——这些企业看中的,正是QRNN在处理长周期、高敏感数据时的不可替代性。
未来已来:当AI拥有“人类级记忆”
站在2026年的尾声回望,大模型竞争的焦点已从“更大的参数”转向“更深的记忆”,QRNN的出现,不仅解决了传统模型的“记忆衰退”难题,更重新定义了AI的能力边界——当模型能像人类一样“记住过去、理解现在、预测未来”时,它不再是一个冰冷的工具,而是一个能真正参与人类社会的智能体。
但挑战依然存在:如何平衡记忆能力与隐私保护?如何防止AI因“过度记忆”而产生偏见?如何让量子计算从实验室走向千家万户?这些问题没有标准答案,但可以确定的是,2026年只是这场变革的起点——在量子循环神经网络的驱动下,AI的进化速度,正以人类难以想象的方式加速。