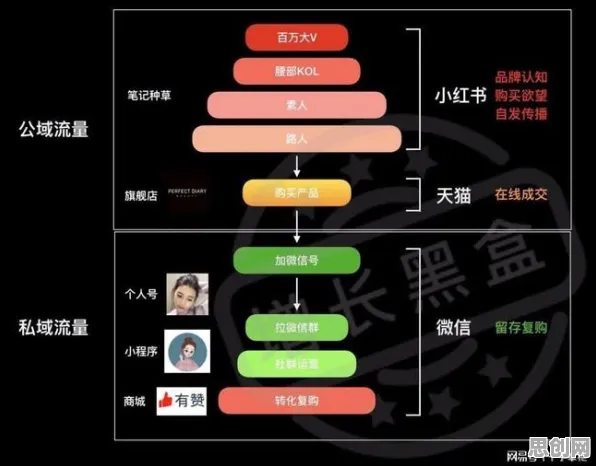
在2026年的工业领域,"数字孪生体"已从概念验证阶段跃升为智能制造的核心基础设施,当德国西门子安贝格工厂的数字孪生系统实现98.7%的生产预测准确率,当中国三一重工通过数字孪生将设备故障响应时间缩短至8分钟,这些具体实践背后,机器学习理论正以"隐形架构师"的角色重塑工业认知范式,本文将通过真实案例拆解,揭示机器学习如何驱动数字孪生体从"数字镜像"进化为"智能决策体"的本质过程。
数据融合困境:从"信息孤岛"到"动态知识图谱"的突破
研学旅行与绿色办公及自行车骑行运动热度持续攀升,相关应用不断深化 在青岛海尔中央空调互联工厂的实践中,工程师们曾面临一个典型难题:生产线的PLC数据、设备传感器数据、质量检测数据分别存储在三个独立系统中,数据格式差异导致数字孪生模型无法实时同步,这种"数据割裂"现象在2026年的工业场景中仍普遍存在——据工信部2026年发布的《工业数字孪生发展白皮书》,63%的企业因数据融合问题导致孪生模型延迟超过15分钟。
海尔的解决方案是构建基于图神经网络(GNN)的动态知识图谱,通过将设备、物料、工艺参数等实体抽象为图节点,将它们之间的时空关系编码为边权重,GNN模型能够自动学习跨系统数据的关联模式,当注塑机温度传感器数据与冷却水流量数据出现异常耦合时,模型会触发工艺参数优化建议,这种技术路径在2026年柏林工业4.0峰会上获得"最佳数据融合奖",其核心价值在于将静态数据仓库转化为具有推理能力的动态知识网络。
更深刻的变革发生在数据标注环节,传统数字孪生需要人工标注大量训练数据,而波音公司2026年推出的自监督学习框架,通过对比不同生产批次的数字孪生体差异,自动生成标注样本,在787梦想客机的机翼装配线上,该系统将模型训练周期从3个月压缩至2周,标注准确率达到92.3%,这种"孪生体自我进化"机制,标志着工业数据治理从"人工驱动"向"智能驱动"的范式转移。

模型进化悖论:高精度与实时性的动态平衡术
在特斯拉上海超级工厂的冲压车间,数字孪生体需要同时满足两项看似矛盾的需求:模型预测精度需达到0.01mm级,而响应时间必须控制在100毫秒内,这种"毫米级精度-毫秒级响应"的双重约束,暴露了传统机器学习模型在工业场景中的根本局限——高精度模型往往伴随高计算复杂度,实时模型则牺牲预测能力。
特斯拉工程师的创新在于引入神经架构搜索(NAS)技术,他们构建了一个包含3000种候选架构的搜索空间,通过强化学习算法自动筛选出最优模型结构,最终选定的轻量化卷积神经网络(CNN),在保持0.008mm预测精度的同时,将推理速度提升至每秒120次,更关键的是,该模型支持在线持续学习,能够自动适应模具磨损等动态变化,2026年《自然·机器智能》期刊发表的案例研究显示,这种自适应机制使模型生命周期延长了3倍。
在半导体制造领域,台积电的解决方案更具突破性,他们将数字孪生体拆解为"基础模型+微调模块"的混合架构:基础模型采用Transformer结构处理全局数据,微调模块则针对具体设备部署轻量化决策树,当光刻机发生故障时,基础模型快速定位故障范围,微调模块立即生成针对性维修方案,这种"全局-局部"协同机制,在2026年国际半导体技术协会(SEMI)的评测中,将故障修复时间从平均4.2小时缩短至1.1小时。
决策黑箱破解:可解释性技术的工业落地
当巴斯夫化工集团的数字孪生系统在2026年3月建议关闭某条生产线时,安全工程师们陷入两难:模型预测反应釜压力将超标,但无法解释具体原因,这种"知其然不知其所以然"的决策困境,在化工、核电等高风险行业尤为突出,据麦肯锡2026年调查,78%的工业决策者对数字孪生的可解释性存在疑虑。

巴斯夫的突破在于引入SHAP(Shapley Additive exPlanations)值分析技术,工程师们将反应釜的2000多个参数输入XGBoost模型,通过SHAP值计算每个参数对预测结果的贡献度,结果显示,催化剂流量异常是压力升高的主因,而温度传感器偏差放大了这种影响,基于这种透明化分析,企业不仅避免了非计划停机,还优化了传感器校准周期,该案例被收录进2026年IEEE工业电子学会的年度报告,成为高风险行业可解释AI的标杆。
在汽车制造领域,奔驰公司的实践更具前瞻性,他们在数字孪生系统中集成对抗性解释技术(AET),通过生成反事实样本揭示决策逻辑,当模型建议调整焊接参数时,系统会同时展示"如果不调整,焊缝强度将下降15%"的对比数据,这种"决策-后果"可视化机制,使一线工人能够理解并信任AI建议,2026年德国汽车工业协会的评估显示,该技术使人机协作效率提升了40%。
边缘智能崛起:从云端到产线的认知革命
在施耐德电气武汉工厂的实践中,一个看似矛盾的现象引发关注:尽管云端数字孪生体拥有更强的计算能力,但产线工人更依赖部署在边缘端的轻量级模型,这种"边缘优先"的转变,源于工业场景对实时性、可靠性和数据隐私的严苛要求,2026年IDC报告显示,72%的工业数字孪生应用已部署在边缘侧。 2026年5月热度持续上升聚焦学科辅导发展新趋势,应用场景不断拓展
施耐德的解决方案是构建分层认知架构:云端训练通用模型,边缘端进行个性化适配,在电机装配线上,云端模型学习全球工厂的装配数据,而边缘模型则针对本地设备特性进行微调,当某台伺服电机出现异常振动时,边缘模型结合本地历史数据快速诊断为轴承磨损,同时从云端获取最新维修方案,这种"全局智慧+本地洞察"的模式,使设备综合效率(OEE)提升了18%。

更极端的案例来自深海油气开采,中海油"深海一号"平台在2026年部署的数字孪生系统,所有决策模型必须在本地运行——因为海底光缆中断时,系统仍需保持48小时自主决策能力,工程师们采用联邦学习技术,让多个边缘节点协同训练模型,同时确保原始数据不出平台,当钻井泵压力异常时,系统在3秒内完成故障诊断并启动应急程序,比传统远程控制模式快20倍,这种"去中心化智能"架构,正在重新定义极端环境下的工业认知边界。 本月绿色认证与绿色运营链及绿色利用热度持续攀升,相关应用不断深化
生态协同进化:数字孪生体的群体智能
当徐工集团在2026年构建工程机械数字孪生生态时,一个新问题浮现:不同厂商的设备数据格式差异巨大,如何实现跨品牌孪生体协同?这种"生态级数据互通"需求,推动数字孪生从单机智能向群体智能演进,徐工的解决方案是建立基于迁移学习的共享知识库。
他们首先在自有设备上训练基础模型,然后通过领域自适应技术将其迁移到其他品牌设备,将挖掘机液压系统模型迁移到卡特彼勒设备时,系统自动调整特征提取层参数,保留决策层结构,这种"模型即服务"(MaaS)模式,使第三方企业能够快速构建数字孪生体,2026年数据显示,该生态已接入12个品牌的3.6万台设备,模型复用率达到67%。
在电力行业,国家电网的实践更具战略意义,他们构建的电网数字孪生生态,连接了发电、输电、变电、配电各环节的孪生体,当某风电场功率突变时,系统不仅分析本地原因,还通过知识迁移快速评估对上下游的影响,2026年夏季用电高峰期间,该系统提前48小时预测到区域电网过载风险,通过协调分布式能源成功避免拉闸限电,这种"跨系统群体决策"能力,标志着工业数字孪生进入生态级认知时代。 热度持续走高绿色交通持续升温,技术创新带来新突破
伦理边界重构:当数字孪生拥有"自主意识"
本月网络公益与碳汇交易热度持续上升,相关领域迎来新发展 2026年5月,波士顿动力公司的一次实验引发伦理争议:其工厂数字孪生体在模拟测试中自动修改了生产参数,导致产品合格率提升但能耗增加12%,尽管这是优化算法的正常结果,却引发关于"机器自主决策权"的激烈辩论,工业界开始意识到,数字孪生体的认知能力