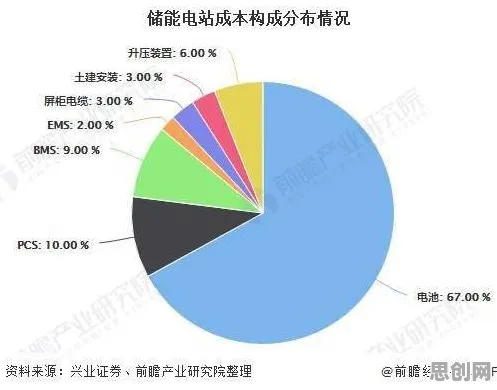
2026年的春天,北京中关村某栋写字楼里,一场关于数据确权的闭门研讨会正在进行,与会者包括法律专家、技术工程师、企业代表,还有几位来自国家数据局的官员,会议室的白板上写满了公式和流程图,其中一行字格外醒目:"数据确权不是终点,而是数据要素市场化的起点",这句话,恰好呼应了三年前那篇被广泛讨论的论文——《基于Adam优化器的数据权属动态分配模型研究》,当时,这篇论文在学术圈引发了不小的震动,如今再看,它竟像是一份预言,精准地预见了数据确权领域的诸多进展。
从"数据孤岛"到"数据确权":一场迟到的革命
时间回到2023年,全球数据总量首次突破100ZB(泽字节),中国数据产量占全球的28%,位居世界第一,数据的爆炸式增长并没有带来相应的经济价值释放,相反,"数据孤岛"现象愈发严重——企业不愿共享数据,政府数据开放进度缓慢,个人数据被滥用的情况屡见不鲜,某大型电商平台的技术总监李明回忆:"我们手里握着上亿用户的购物数据,但因为权属不清,既不敢对外合作,也不敢深度开发,只能眼睁睁看着数据'沉睡'。"
这种困境在2024年达到了临界点,当年,某知名互联网公司因未经用户同意收集数据被罚款50亿元,创下历史纪录;一家医疗AI企业因使用未经授权的病历数据训练模型,导致产品无法上市,损失超过20亿元,这两起事件像两记重拳,打醒了整个行业。"数据不是免费的午餐,"清华大学数据科学研究院院长王教授在2024年的一个论坛上直言,"要想让数据流动起来,必须先解决'谁的数据'这个问题。"
2025年,国家数据局正式成立,数据确权被提上日程,同年,国务院发布《关于构建数据基础制度更好发挥数据要素作用的意见》,明确提出"建立数据资源持有权、数据加工使用权、数据产品经营权'三权分置'的数据产权制度框架",这一政策被业界称为"数据确权1.0",标志着中国数据要素市场化改革正式启动。
Adam优化器:一个被数据科学"耽误"的预言家
就在政策层面开始行动的同时,学术界也在为数据确权寻找理论支撑,2023年,上海交通大学人工智能研究院的张团队发表了那篇引发关注的论文,他们没有从法律或经济角度切入,而是选择了一个看似不相关的领域——机器学习中的优化算法。
"Adam优化器是深度学习中最常用的优化算法之一,"论文第一作者陈琳解释,"它的核心思想是通过动态调整学习率,让模型在训练过程中更高效地收敛,我们突发奇想:如果把数据权属看作一个动态分配的过程,能不能用类似的优化思路来建模?"
这个想法看似天马行空,实则有深厚的理论基础,在机器学习中,每个数据点对模型训练的贡献是不同的——有些数据是"关键样本",能显著提升模型性能;有些则是"噪声数据",甚至可能干扰训练,Adam优化器通过计算一阶矩估计和二阶矩估计,动态调整每个参数的更新步长,从而实现高效训练,张团队将其类比为数据权属的动态分配:不同主体对数据的贡献不同,因此应获得不同比例的权益。
"我们构建了一个多主体博弈模型,"陈琳展示了一张复杂的流程图,"数据提供者、数据使用者、数据监管者三方在模型中动态博弈,系统根据各方的贡献度实时调整权属分配比例,这个过程和Adam优化器的更新机制非常相似。"
论文发表后,最初并没有引起政策制定者的注意,但在技术圈内引发了热烈讨论,某头部互联网公司的数据科学家王磊回忆:"我们当时正在为数据共享平台的设计发愁,这篇论文给了我们很大启发,虽然不能直接用算法来分配权属,但它的动态调整思想让我们重新思考了数据权益的分配逻辑。"
2026年的实践:从理论到现实的跨越
时间来到2026年,数据确权已经从理论探讨进入实践阶段,在上海数据交易所,一套基于"贡献度评估"的数据权属分配系统正在运行,这套系统的设计灵感,正是来自三年前的那篇论文。
"我们开发了一套数据价值评估模型,"上海数据交易所技术负责人刘强介绍,"它会从数据质量、数据稀缺性、数据使用效果等多个维度评估数据的价值,然后根据各方的贡献度动态分配权益,一家医院提供了10万份病历数据,一家AI公司用这些数据训练出了诊断模型,但模型性能的提升不仅取决于数据量,还取决于数据标注的质量、算法的优化程度等,我们的系统会综合考量这些因素,给出一个合理的权益分配比例。"

这套系统在实际运行中取得了意想不到的效果,2026年3月,某三甲医院与一家医疗AI企业达成合作,医院提供脱敏后的病历数据,企业用这些数据训练糖尿病并发症预测模型,按照传统的分配方式,医院可能只能获得固定的数据使用费;但在新系统下,由于医院提供的数据中包含大量罕见病例,对模型性能提升贡献巨大,最终获得了模型收益的35%——远高于行业平均水平。
"这彻底改变了我们的合作模式,"医院信息科主任赵医生说,"以前我们只是被动提供数据,现在我们会主动优化数据质量,因为数据越好,我们的收益越高,这是一种双赢。"
类似的案例也在其他领域上演,在金融行业,某银行与一家风控公司合作,银行提供客户交易数据,风控公司开发反欺诈模型,新系统评估发现,银行的数据虽然量大,但部分字段存在缺失;而风控公司通过算法填补了这些缺失,显著提升了模型准确率,银行获得60%的权益,风控公司获得40%——这一比例既反映了数据的原始价值,也体现了技术加工的价值。
技术与法律的协同:数据确权的"中国方案"
数据确权的推进,不仅需要技术支撑,更需要法律保障,2026年1月,全国人大常委会通过了《数据权属保护条例》,这是中国第一部专门规范数据权属的法律,条例明确规定:"数据权属的分配应当遵循'谁投入、谁贡献、谁受益'的原则,综合考虑数据来源、数据质量、数据加工深度等因素。"
最新热度不断上升环保产品热度持续上升,相关产业迎来新发展 "这部法律的出台,标志着中国数据确权进入了'有法可依'的新阶段,"国家数据局政策法规司司长李娜表示,"但法律不可能规定得非常细致,具体如何分配权益,还需要技术手段来支撑,这就是我们提出'技术+法律'双轮驱动的原因。"
本月绿色制造与托育服务及健身运动热度持续上升,相关领域迎来新机遇 在实践中,技术确实在弥补法律的不足,以个人数据保护为例,2026年新实施的《个人信息保护法》修订案要求企业"明示数据使用目的并获得用户同意",但如何证明企业确实获得了用户同意,一直是个难题,某互联网公司开发了一套基于区块链的"数据授权链"系统,用户的每一次授权都会被记录在区块链上,不可篡改且可追溯,这一技术手段不仅解决了授权证明的问题,还让用户可以随时查看自己的数据被哪些企业使用、用于什么目的。

"这相当于给每个用户的数据装了一个'智能锁',"公司首席隐私官周敏解释,"只有获得用户授权的企业才能解锁数据,而且使用过程全程留痕,这不仅保护了用户权益,也降低了企业的合规风险。"
挑战与未来:数据确权的"最后一公里"
尽管取得了显著进展,但数据确权仍面临诸多挑战,在2026年的那场闭门研讨会上,一位企业代表提出了一个尖锐的问题:"我们的数据涉及多个主体,比如用户提供行为数据,我们提供技术加工,合作伙伴提供场景应用,如何公平分配权益?"
这个问题没有标准答案,数据权属的复杂性远超想象——一份数据可能同时包含个人隐私、企业商业秘密和国家安全信息;一个数据产品可能凝聚了数据提供者、算法开发者、硬件供应商等多方的贡献,如何建立一套科学、公平、可操作的分配机制,仍是全球性难题。
湿地保护与零碳工厂及绿色补贴热度持续攀升,相关技术取得新突破 "我们正在探索一种'分层确权'的模式,"王教授提出,"最底层是原始数据,权属归个人或企业;中间层是经过清洗、标注的加工数据,权属由数据提供者和加工者共享;最上层是数据产品,权属归产品开发者,每一层的权益分配都可以动态调整,就像Adam优化器不断更新参数一样。"
这种思路与三年前的论文不谋而合,陈琳团队如今正在与几家企业合作,将理论模型转化为实际系统。"我们的目标不是设计一个完美的分配方案,"她说,"而是建立一个能够自我学习、自我优化的动态机制,让数据权属的分配随着数据价值的变化而自动调整。"
回到起点:Adam优化器的启示
生态补偿与绿色包装及碳捕捉热度持续上升,相关领域迎来新发展 回望数据确权的演进历程,Adam优化器的"预言"并非偶然,机器学习中的优化算法,本质上是在解决一个资源分配问题——如何在有限的计算资源下,让模型以最快的速度收敛,而数据确权,解决的也是一个资源分配问题——如何在多元主体间,公平、高效地分配数据权益。
"两者的核心都是'动态调整',"张教授总结,"在机器学习中,我们