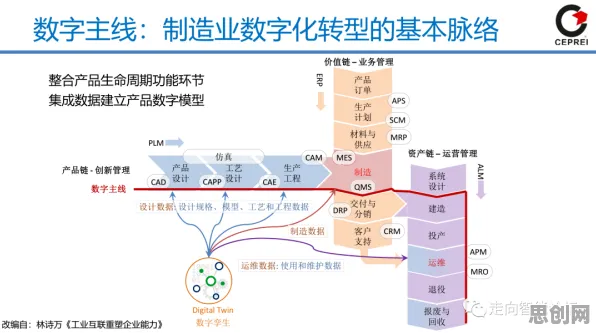
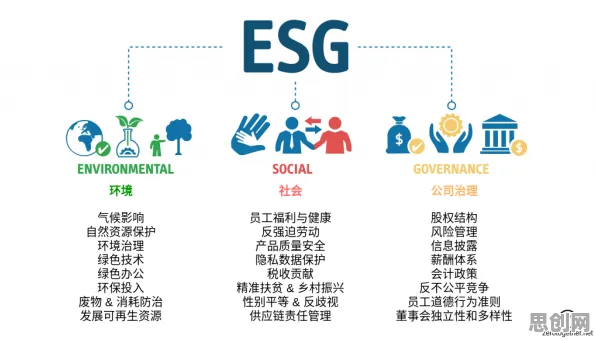
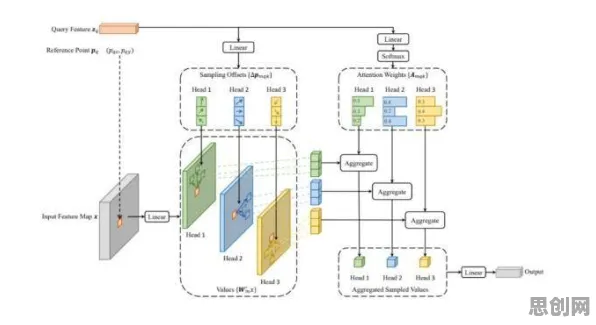
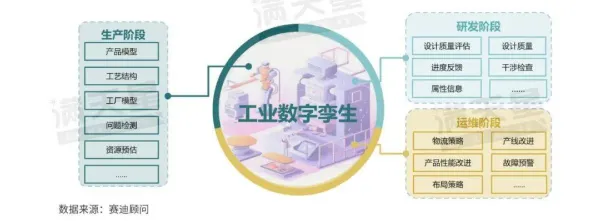
数据清洗与融合:打破“数据孤岛”的第一步
在某大型汽车制造企业的数字孪生项目中,工程师小李的团队曾陷入“数据越多越混乱”的怪圈,他们接入了生产线上的数百个传感器数据,包括温度、压力、振动、转速等,但这些数据分散在PLC、SCADA、MES等多个系统中,格式不统一、时间戳不同步,甚至存在大量缺失值和异常值,小李回忆:“我们花了三个月时间试图直接用这些数据训练预测模型,结果模型在测试集上表现良好,一到实际生产中就‘翻车’——因为训练数据里藏着太多‘脏数据’。”
数据科学的介入改变了这一局面,团队引入了自动化数据清洗工具,结合业务规则(如“发动机温度不可能低于-20℃”)和统计方法(如3σ原则剔除异常值),对原始数据进行了“预处理”,更关键的是,他们通过数据融合技术,将分散在各系统的数据按照“设备-工序-时间”的维度重新组织,构建了统一的数据仓库,将PLC记录的“电机电流”与SCADA记录的“设备状态”关联,再与MES系统中的“生产订单”匹配,形成了“某台电机在执行某订单时的工作状态”的完整数据链。 稳步推进网络安全热度持续上升,相关产业迎来新机遇
这一改变的效果立竿见影,在后续的故障预测模型中,清洗后的数据使模型准确率从62%提升至89%,误报率从35%降至8%,小李感慨:“数据科学不是‘锦上添花’,而是‘雪中送炭’——没有干净、融合的数据,数字孪生就是空中楼阁。”
特征工程:从“原始数据”到“业务洞察”的桥梁
在能源管理领域,某电力公司的数字孪生平台试图通过分析电网运行数据,预测设备故障并优化调度,但项目初期,模型的表现让团队失望:尽管输入了电压、电流、功率等数十个指标,预测准确率始终徘徊在70%左右,问题出在哪里?数据科学团队发现,原始数据中隐藏的“业务特征”未被充分挖掘。
电网设备的故障往往与“负载突变”相关,但原始数据中只有“瞬时功率”的绝对值,缺乏“功率变化率”这一关键特征,团队通过计算“功率在5分钟内的变化幅度”,并将其作为新特征输入模型,准确率立即提升了12%,类似地,他们还提取了“设备运行时长”“历史故障次数”“环境温度波动”等特征,这些特征并非直接来自传感器,而是通过数据变换、业务规则推导或外部数据融合(如天气数据)生成。

更深入的特征工程还涉及“领域知识”的融入,在风电设备的数字孪生中,团队发现“风速-功率曲线”的非线性特征对故障预测至关重要——当实际功率偏离理论曲线超过一定阈值时,设备可能存在故障,这一发现源于对风电行业物理规律的深刻理解,而数据科学提供了将这种理解转化为数学特征的工具(如通过多项式拟合计算残差)。
经过特征工程优化后,该电力公司的故障预测模型准确率达到92%,误报率控制在5%以内,每年可减少非计划停机损失超千万元,项目负责人表示:“特征工程不是‘技术炫技’,而是将数据与业务深度绑定的关键——没有对行业的理解,再多的数据也只是一堆数字。”
模型选择与优化:从“通用算法”到“场景适配”的进化
在航空航天领域,某飞机制造商的数字孪生平台面临更复杂的挑战:他们需要预测飞机发动机的剩余使用寿命(RUL),但发动机的运行数据具有“高维、非线性、小样本”的特点——每个发动机的工况不同,故障模式多样,且历史故障数据有限,团队最初尝试用传统的线性回归模型,结果预测误差高达30%;改用深度学习中的LSTM模型后,误差降至15%,但仍无法满足航空安全的高标准。
数据科学团队介入后,没有盲目追求“更复杂的模型”,而是从业务需求出发,选择了“集成学习+物理约束”的混合方案,他们将发动机的物理模型(如热力学方程)作为“先验知识”,嵌入到机器学习模型中,限制模型的输出范围(如“RUL不可能为负”);采用XGBoost等集成学习算法,结合多个弱学习器的预测结果,提高模型的鲁棒性,团队还通过“数据增强”技术(如对历史数据添加噪声、模拟不同工况)扩充训练集,解决了小样本问题。

这一方案的效果超出预期:在独立测试集上,模型的预测误差降至5%以内,且在极端工况(如高温、高负荷)下的表现显著优于纯数据驱动模型,更关键的是,由于融入了物理约束,模型的预测结果更具可解释性——工程师可以理解“为什么模型认为这台发动机的RUL是200小时”,而非“黑箱”式的输出。
产业升级与环保技术热度持续攀升,相关应用不断深化 该飞机制造商的数字孪生项目负责人评价:“数据科学不是‘替代工程师’,而是为工程师提供更强大的工具——我们仍然需要理解物理规律,但数据科学让这种理解可以量化、可计算、可优化。”
实时计算与边缘部署:从“云端分析”到“现场决策”的跨越
在智能制造场景中,数字孪生的价值往往体现在“实时优化”上——根据生产线上的实时数据调整工艺参数,以减少次品率,但某半导体企业的实践表明,这一目标的实现面临计算延迟的瓶颈:传感器数据从采集到上传至云端,再经模型分析后返回指令,整个过程需要3-5秒,而对于高速运转的半导体生产线,1秒的延迟都可能导致产品报废。
数据科学团队提出的解决方案是“边缘计算+轻量化模型”,他们将部分计算任务从云端迁移到生产线边的工业网关(边缘设备)上,减少数据传输延迟;通过模型压缩技术(如知识蒸馏、量化)将原本数百MB的深度学习模型缩小至几MB,使其能在资源有限的边缘设备上运行,在缺陷检测场景中,团队将一个基于ResNet的图像识别模型压缩后部署到边缘摄像头,实现了每秒30帧的实时检测,延迟控制在100毫秒以内。

更进一步的是“动态模型切换”技术,由于半导体生产线的工况会频繁变化(如不同批次的产品规格不同),团队开发了一套模型管理系统,可根据实时数据自动选择最合适的模型——当检测到当前批次的产品厚度增加时,系统自动切换至针对“厚产品”训练的模型,无需人工干预,这一技术使缺陷检测的准确率从85%提升至97%,同时减少了30%的误报。
该半导体企业的CTO表示:“数据科学让数字孪生从‘事后分析’变成了‘事中干预’——我们不再需要等数据传到云端再决策,而是可以在生产现场实时响应,这才是工业4.0的核心价值。”
跨学科协作:从“技术孤岛”到“业务赋能”的转变
在所有案例中,一个共同的经验是:数字孪生的成功离不开跨学科团队的协作,某化工企业的项目负责人坦言:“我们最初以为数字孪生是IT部门的事,结果发现没有工艺工程师、设备专家、操作工的参与,模型根本无法落地。”在预测反应釜的故障时,数据科学团队需要工艺工程师解释“温度-压力-反应速率”的物理关系,需要设备专家提供“哪些传感器更容易失效”的实践经验,还需要操作工反馈“模型预警后如何调整操作”的实际需求。
量子计算与绿色水处理及家居装饰持续升温,技术创新带来新突破 这种协作不仅需要“技术融合”,更需要“文化融合”,某汽车零部件企业的做法值得借鉴:他们成立了由数据科学家、工艺工程师、IT人员组成的“数字孪生突击队”,采用“敏捷开发”模式,每周迭代模型并现场验证效果;建立了“数据共享机制”,明确各部门的职责(如设备部负责传感器维护,IT部负责数据传输,工艺部负责业务规则定义),避免了“踢皮球”现象。
经过一年的实践,该企业的数字孪生平台已覆盖80%的生产线,故障预测准确率达90%,设备综合效率(OEE)提升15%,项目负责人总结:“数字孪生不是‘技术竞赛’,而是‘业务变革’——只有让