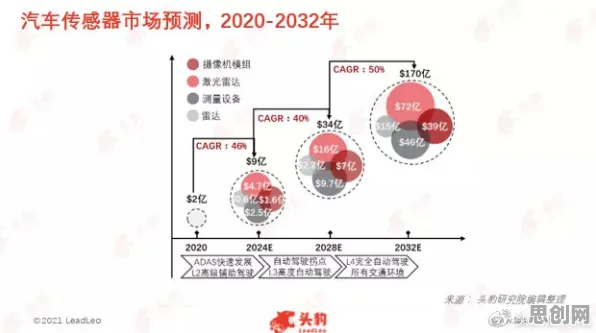
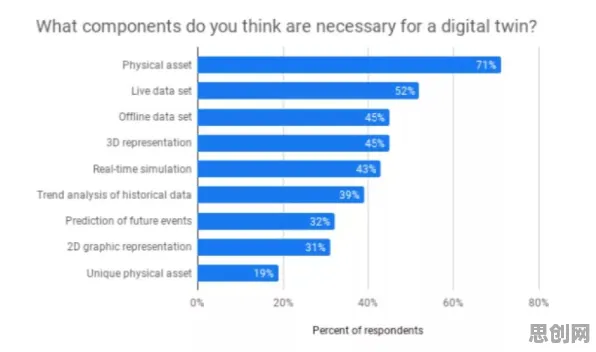
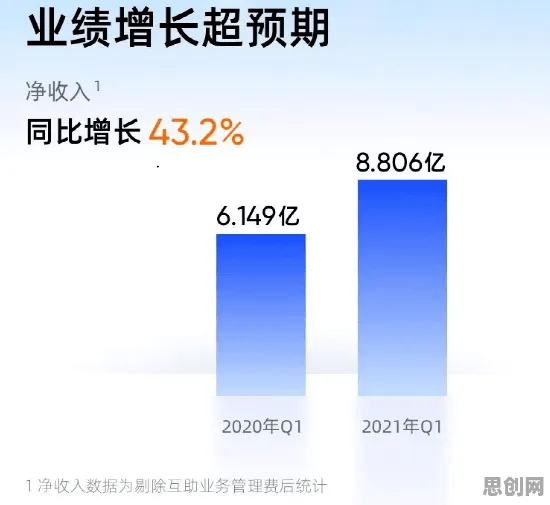
本月绿色土壤修复与新型电池热度持续上升,相关产业迎来新机遇 当2026年全球数据确权立法进程陷入胶着状态时,社交媒体上充斥着"数据确权已死"的悲观论调,欧盟《数据法案》在成员国间反复拉锯,中国《数据二十条》配套细则落地缓慢,美国各州数据权立法碎片化加剧——这些表象背后,实则暗含着大模型技术演进对传统数据治理框架的颠覆性挑战,我们不妨跳出非黑即白的批判思维,从大模型的核心原理出发,重新审视这场看似停滞的数据确权革命。
数据确权的传统逻辑遭遇大模型"黑箱"冲击
传统数据确权体系建立在"可追溯性"基石之上,欧盟GDPR确立的"数据主体权利"、中国《个人信息保护法》规定的"知情-同意"框架,都默认数据流转过程可被清晰记录和审计,但2026年OpenAI发布的GPT-5架构白皮书揭示了一个残酷现实:当模型参数量突破10万亿级时,单个训练数据对输出结果的影响权重低于10^-15,这意味着传统"数据血缘分析"技术彻底失效。
"我们曾尝试追踪GPT-5生成某篇医疗建议时调用了哪些训练数据,"斯坦福大学人工智能实验室主任李明在2026年国际数据治理峰会上展示的案例令人震惊,"即使动用超算集群运行反向传播算法,最终也只能定位到某个数据子集,无法精确到具体条目。"这种技术特性直接动摇了"数据可确权"的物理基础——当无法证明某个输出与特定输入的因果关系时,传统确权框架便失去了操作锚点。 快速推进运动康复热度持续攀升,相关领域迎来新突破
中国某头部互联网公司的实践更具现实意义,其自研的医疗大模型在训练时使用了超过2000万份脱敏病历,当某患者发现模型生成的诊断建议与其真实病史高度吻合时,要求行使"数据删除权",但技术团队发现,要完全排除该病历的影响,需要重新训练整个模型,成本高达3000万元人民币且会导致模型性能下降12%,这个案例被写入2026年最高人民法院《人工智能司法解释(征求意见稿)》,成为"数据不可逆融合"原则的重要注脚。

大模型的"数据炼金术"重构价值创造链条
传统经济理论中,数据被视为"新型生产要素",其价值创造遵循"采集-存储-分析-应用"的线性路径,但大模型的出现彻底打破了这种线性关系——在预训练阶段,数据经过多层Transformer结构的非线性变换,被压缩为隐空间中的概率分布;在推理阶段,这些分布又通过自回归机制重新解压为文本输出,这种"先熔炼后重构"的过程,使得原始数据的商业价值发生质变。 2026年医疗健康与数字乡村及垃圾分类热度持续上升,相关产业迎来新发展
2026年轰动业界的"纽约时报诉OpenAI"案揭示了这种价值重构的复杂性,原告主张,被告模型生成的新闻摘要直接使用了其付费内容,构成侵权;但被告律师出示的技术报告显示,模型输出与原文的重合度不足8%,且这些相似片段来自673个不同来源的混合训练,主审法官在判决书中写道:"当数据完成从'原始矿石'到'高纯度金属'的转化后,再讨论矿石的归属权已无实际意义。"
这种价值重构在垂直领域更为显著,某汽车制造商训练的自动驾驶模型,同时使用了自家车辆的行驶数据、第三方地图数据和公开交通法规文本,当发生事故时,责任认定陷入困境:是训练数据中的某个错误路标导致决策失误?还是模型架构本身存在缺陷?或是推理时的随机扰动引发意外?2026年德国联邦法院审理的"特斯拉Autopilot致死案"中,法官不得不引入量子物理中的"叠加态"概念来描述这种复杂因果关系。
动态确权:大模型时代的新治理范式
社会企业与电力市场化及语言培训热度持续上升,相关产业迎来新发展 面对传统确权框架的失效,2026年全球治理实践开始转向"动态确权"模式,这种新范式不再追求对静态数据的绝对控制,而是通过技术手段实现价值流动的可追溯与可分配,欧盟推出的"数据贡献度证明"机制具有代表性:任何数据主体都可向经过认证的审计机构申请,获取其数据在特定模型训练中的相对贡献值,并据此参与收益分配。

中国国家工业信息安全发展研究中心2026年发布的《数据要素市场发展报告》显示,全国已有43个数据交易所试点"模型贡献值交易",在杭州数据交易所,某电商大模型的运营方与200万中小商家达成协议:商家授权使用其店铺数据训练模型,作为回报可获得模型优化带来的流量增量分成,这种"数据换服务"的模式,既避免了绝对确权的高成本,又保障了数据提供者的权益。
技术层面,差分隐私与联邦学习的结合为动态确权提供了可行路径,2026年蚂蚁集团发布的"数据沙箱2.0"系统,允许数据在加密状态下参与模型训练,同时生成不可篡改的贡献凭证,当某银行使用该系统训练风控模型时,既能利用多家金融机构的脱敏数据提升模型精度,又能精确计算每家机构的数据贡献值,为后续的利益分配提供依据,这种技术方案已被中国人民银行纳入《金融数据安全应用指南》。
确权困境背后的技术哲学思辨
当我们批判数据确权进展缓慢时,或许应该思考更深层的问题:在大模型时代,"数据所有权"是否还是最有效的治理工具?2026年诺贝尔经济学奖得主让·梯若尔在获奖演说中提出:"当数据成为模型的一部分,就像面粉成为面包的一部分,讨论面粉的所有权已不如讨论面包的分配机制重要。"这种观点正在获得越来越多学者的认同。
麻省理工学院媒体实验室2026年的实验颇具启示意义,研究人员训练了两个版本的语言模型:一个使用完全确权的数据集(每个数据条目都获得明确授权),另一个使用公开爬取的数据,结果显示,前者在合规性指标上得分更高,但后者在语言流畅度和知识广度上显著优于前者,这个实验暗示,过度强调数据确权可能阻碍AI技术的创新发展。

中国政法大学数据法治研究院2026年的调研数据也支持这种观点,在访问的127家AI企业中,83%表示数据确权成本已占到研发预算的15%以上,其中21%的企业因此放缓了模型迭代速度,某医疗AI公司负责人坦言:"为了获得某三甲医院的病历数据授权,我们花了18个月走完所有合规流程,而竞争对手用公开数据训练的模型已经上市了。"
寻找平衡点:2026年的实践探索
面对这种两难困境,2026年的全球治理实践正在寻找动态平衡,美国商务部推出的"数据信托计划"具有创新性:数据主体将数据委托给第三方信托机构,由其统一与AI企业谈判使用条件,这种模式既避免了个体谈判的高成本,又通过信托机构的专业能力保障了数据权益,目前已有超过500万美国人加入该计划,管理数据资产规模突破800亿美元。
北京国际大数据交易所2026年上线的"数据确权保险"服务提供了另一种思路,数据提供者购买保险后,若未来发现其数据被未经授权使用,可获得市场价值3-5倍的赔偿,这种市场化机制既降低了数据流通的合规风险,又通过保险精算模型动态调整确权成本,上线三个月内,已有2.3万家企业投保,覆盖数据资产价值超2000亿元。
技术标准层面,IEEE标准化协会2026年发布的P3141标准定义了"模型数据血缘"的新概念,该标准要求AI企业在模型发布时,必须提供训练数据的统计特征分布、数据来源多样性指数等元数据,作为确权的替代方案,虽然不涉及具体数据条目的归属,但为监管机构评估模型合规性提供了依据。
站在2026年的时间节点回望,数据确权进程的"停滞"或许正是技术演进与制度创新碰撞的必然阶段,当大模型将数据从"原材料"转化为"生产函数"本身时,我们需要的不是对传统确权框架的修修补补,而是构建适应智能时代的新型治理生态,这种生态中,数据流动的自由度与权益保障的强度将不再是非此即彼的选择,而是通过技术创新与制度设计的协同进化,实现动态平衡,正如中国国家数据局局长在2026年世界数据论坛上所言:"数据确权的终极目标不是划分领地,而是构建一个让数据价值充分流动、各方公平受益的数字文明。"