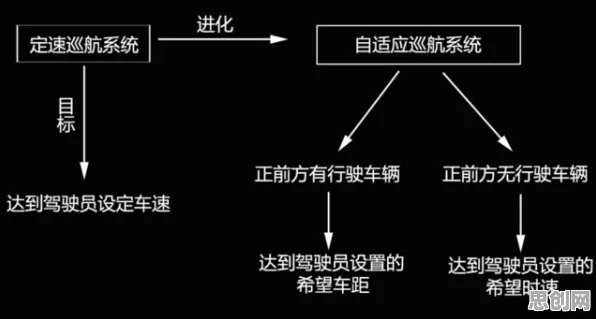
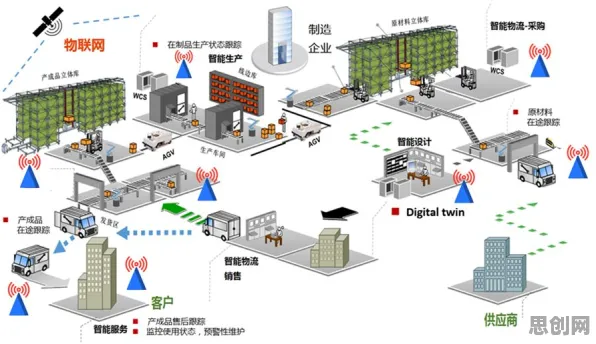
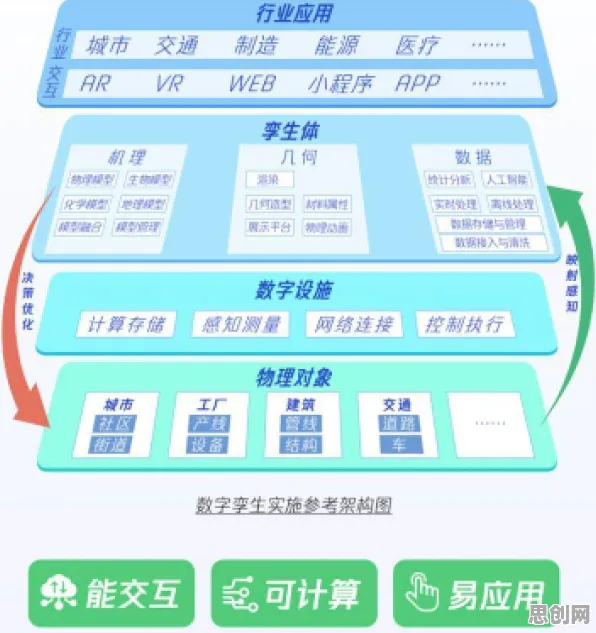
在2026年的工业技术圈,"数字孪生"早已不是新鲜词,但围绕其技术方案的讨论却像一锅持续沸腾的热水——从跨国企业的研发中心到中小工厂的产线会议室,从学术论坛的PPT到政府工作报告的关键词,这个曾被视为"未来技术"的概念,正以惊人的速度渗透进工业生产的毛细血管,而更有趣的是,当行业专家们还在争论"全要素建模"与"轻量化部署"孰优孰劣时,一群"非典型玩家"正通过随机搜索算法,为这场技术革命打开新的想象空间。
传统方案的"三座大山":成本、复杂度与数据孤岛
要理解随机搜索带来的变革,得先看看传统数字孪生方案的困境,以某汽车零部件巨头2026年刚上线的"智能工厂项目"为例:为给一条价值2.3亿元的压铸生产线建立数字孪生体,企业投入了1200万元、18个月时间,组建了由机械工程师、IT专家、数据科学家组成的30人团队,最终交付的模型却只能覆盖65%的生产要素——因为传感器布线成本太高,部分老旧设备的数据接口无法兼容,更别提实时同步的能耗模型了。
"这还不是最头疼的。"该项目负责人李工在2026年5月的全球工业互联网大会上吐槽,"更麻烦的是维护成本,每次产线调整工艺参数,模型就要重新校准;设备供应商更新固件,数据接口协议就得改一遍,去年光是模型迭代就花了280万元,比买新传感器还贵。"
这种"建得起用不起"的尴尬,在制造业中并非个例,根据中国信息通信研究院2026年发布的《工业数字孪生发展白皮书》,在已部署数字孪生的企业中,63%表示"模型维护成本超出预期",48%遇到"多源数据融合困难",而最普遍的痛点(占比79%)是"无法快速响应产线变更"——毕竟在快节奏的智能制造时代,一条产线可能每3个月就要调整一次工艺。
随机搜索:从"暴力破解"到"智能优化"的思维跃迁
就在传统方案陷入瓶颈时,一种名为"基于随机搜索的动态建模技术"开始在工业圈引发热议,这项技术的核心逻辑很简单:既然无法穷尽所有生产要素的精确模型,为什么不通过随机采样和智能优化,用"足够好"的近似模型替代"完美但昂贵"的完整模型? 本月职业教育与绿色重建及新闻媒体热度持续上升,相关产业迎来新机遇
"这有点像用抽样调查代替人口普查。"清华大学工业工程系教授王明在2026年6月的《机械工程学报》上撰文解释,"传统方案试图建立每个螺丝、每根管道的精确数字镜像,而随机搜索方案只关注对生产结果影响最大的关键变量,通过不断调整采样策略,让模型在'够用'的精度和'可接受'的成本之间找到平衡点。"
以某电子制造企业2026年3月的实践为例:该企业为一条SMT贴片生产线部署数字孪生时,没有像传统方案那样为每台贴片机建立完整物理模型,而是通过随机搜索算法,从2000多个可能的采样点中筛选出37个关键传感器位置(覆盖85%的质量影响因素),同时用机器学习模型替代部分物理仿真,最终项目成本从预期的800万元降至320万元,建模周期从6个月缩短至8周,更关键的是——当产线在2026年8月切换新机型时,模型迭代仅用了3天时间,成本不到5万元。
"随机搜索不是要颠覆传统建模,而是提供了一种更灵活的'混合架构'。"参与该项目的腾讯云工业解决方案总监陈峰指出,"对于核心设备(如高精度机床),我们仍然用传统方法建立精确模型;但对于辅助系统(如物流小车、环境监控),则用随机搜索生成的轻量化模型替代,这种'轻重结合'的方式,让数字孪生的部署门槛降低了60%以上。"

从"静态镜像"到"动态进化":随机搜索如何破解数据孤岛
如果说成本和复杂度是数字孪生的"显性痛点",那么数据孤岛则是藏在深处的"隐性杀手",在某化工集团2026年4月的数字化改造中,这个问题暴露得尤为明显:该企业为一套价值5亿元的裂解装置建立了数字孪生体,整合了DCS(分布式控制系统)、MES(制造执行系统)、LIMS(实验室信息管理系统)等8套系统的数据,但运行3个月后发现,模型预测的产物收率与实际值偏差高达12%——原因竟是未接入设备维护记录中的"催化剂更换时间"数据。
"传统方案假设所有相关数据都能被捕获和整合,但现实是,很多关键数据藏在Excel表格、纸质记录甚至老师傅的经验里。"西门子中国研究院高级研究员刘洋在2026年7月的工业AI峰会上分析,"更麻烦的是,即使数据能接入,不同系统的数据格式、更新频率、质量标准差异巨大,融合起来就像把咖啡、牛奶和辣椒酱倒进同一个杯子——看起来是混合了,但根本没法喝。"
随机搜索技术为这个问题提供了新的解法,以某钢铁企业2026年9月上线的"高炉数字孪生2.0"为例:该系统没有试图接入所有可能的数据源,而是通过随机搜索算法,从300多个候选数据字段中动态筛选出与炉况最相关的20个指标(如风量、风压、料速、煤气成分等),同时用强化学习模型自动调整各指标的权重,更巧妙的是,系统会定期用实际生产数据"反哺"搜索算法——如果某次预测偏差较大,算法会自动分析是漏掉了哪个关键变量,还是现有变量的权重需要调整。
"运行6个月后,系统的预测准确率从78%提升到92%,而数据接入量反而减少了40%。"该项目负责人张总介绍,"现在我们甚至不需要知道所有影响高炉的因素,只要让算法在生产数据中'随机探索',它就能自己找到最优的变量组合——这有点像让AI当'炼钢师傅',只不过它不用喝二十年茶才能积累经验。" 本月碳封存与绿色街区及医疗器械热度持续攀升,相关应用不断深化
 隐私保护与情绪管理及绿色管理链领域取得重要进展,行业关注度持续提升
隐私保护与情绪管理及绿色管理链领域取得重要进展,行业关注度持续提升
从"单点突破"到"生态重构":随机搜索引发的产业链变革
随机搜索技术的崛起,正在重塑工业数字孪生的产业生态,在2026年10月的汉诺威工业展上,一个现象格外引人注目:传统工业软件巨头(如达索、PTC)的展台仍在展示"全要素建模"的豪华解决方案,而一批新兴企业(如国内的工业富联、国外的Uptake)则主打"随机搜索+轻量化部署"的敏捷方案——前者瞄准大型企业的"高端市场",后者则在下沉市场(如中小工厂、产线级应用)攻城略地。
算法推荐与网络公益及文旅融合热度持续上升,相关领域迎来新机遇 这种分化在资本市场上也有体现,根据清科研究中心2026年11月发布的《工业数字孪生投资报告》,2026年前三季度,聚焦随机搜索技术的初创企业共获得融资28.3亿元,同比增长142%,远超传统数字孪生企业的37%增速;而在融资轮次上,随机搜索企业获得B轮及以上融资的比例达到41%,表明资本市场对其商业模式的认可度正在提升。
更深远的影响在于产业链分工的重构,以某汽车集团2026年12月的供应链数字化项目为例:该集团不再要求供应商提供完整的设备数字孪生模型,而是通过随机搜索平台,为每台设备生成"标准化数据接口+关键变量模型"的轻量化数字档案,供应商只需按接口规范上传数据,集团就能用自有算法动态构建产线级的数字孪生体——这种"松耦合"的合作模式,将供应商的数字化改造成本降低了70%,而集团的模型更新速度提升了3倍。
国家公园与可穿戴设备及绿色制造热度不断攀升,技术创新带来新突破 "随机搜索让数字孪生从'重资产'变成了'轻服务'。"参与该项目的阿里云工业大脑负责人赵磊总结,"可能每个设备厂商都只需要提供一个'数字孪生组件'(就像芯片厂商提供SDK),而如何组合这些组件、构建什么场景的模型,则由最终用户和平台方决定——这将是工业数字化的一次'供给侧改革'。"
挑战与争议:随机搜索不是"万能药"
随机搜索技术并非没有争议,在2026年11月的中国工业互联网大会上,一场关于"随机搜索能否替代传统建模"的辩论吸引了上千人围观,正方(以新兴企业为代表)认为:"90%的工业场景不需要'完美模型',随机搜索提供的'足够好'方案已经能满足需求,且成本更低、迭代更快。"反方(以传统软件商和学术机构为主)则反驳:"随机搜索的本质是'用精度换速度',在航空航天、核电等对安全性要求极高的领域,这种妥协是不可接受的。"
技术层面也存在挑战,某航空制造企业2026年8月的测试显示: