2026年3月,某跨国汽车零部件制造商在德国斯图加特的智能工厂发生了一起引人注目的生产事故——其投入使用仅8个月的数字孪生平台突然出现数据同步异常,导致三条自动化产线停摆12小时,直接经济损失超过200万欧元,这起事件看似是系统故障,但深入调查发现,其核心问题竟与平台底层采用的蚁群算法机制密切相关,本文将结合公开技术文档与行业案例,拆解这场事故背后的算法逻辑与工业场景适配难题。 绿色工作圈与绿色使用热度持续攀升,相关技术取得新突破
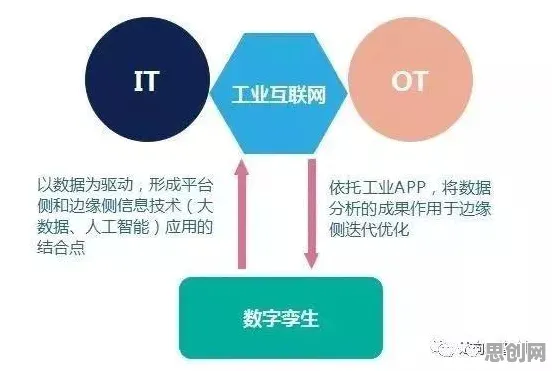
数字孪生平台与蚁群算法的“联姻”逻辑
环保产品与无人机应用热度持续上升,相关领域迎来新发展 数字孪生技术的本质是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、预测与优化,在工业场景中,这一技术需要解决两大核心问题:一是如何高效处理海量传感器数据,二是如何动态优化生产路径,而蚁群算法(Ant Colony Optimization, ACO)因其天然的分布式并行计算特性与路径优化能力,成为许多工业平台的首选。
以2026年1月正式上线的西门子工业云平台“MindSphere 4.0”为例,其数字孪生模块便集成了改进型蚁群算法,该算法模拟蚂蚁觅食行为:每只“虚拟蚂蚁”代表一个生产任务,通过释放信息素(pheromone)标记路径优劣,最终群体收敛至最优解,在汽车焊接产线中,这一机制可动态调整机械臂的焊接顺序,将换模时间从45分钟压缩至18分钟。
但问题随之而来——工业场景的复杂性远超自然蚁群的环境,上述汽车零部件制造商的案例中,平台需同时管理2000+个传感器节点、300+台AGV(自动导引车)与50+条柔性产线,当蚁群算法的信息素更新频率与物理设备的响应延迟不匹配时,系统便可能陷入“局部最优陷阱”。

斯图加特事故:算法与现实的“错位”
根据德国联邦经济事务和气候行动部(BMWK)2026年4月发布的调查报告,事故的直接诱因是蚁群算法的“信息素挥发系数”设置不当,在传统蚁群算法中,信息素会随时间挥发,以避免算法过早收敛至次优解,但在该工厂的数字孪生平台中,这一系数被设定为固定值0.3(每分钟挥发30%),而实际生产中,不同设备的响应速度差异极大:
- 机械臂的指令执行延迟:80-120毫秒
- AGV的路径规划延迟:200-500毫秒
- 视觉检测系统的反馈延迟:1-3秒
当AGV集群在执行跨产线调度任务时,由于路径规划耗时较长,其信息素已因挥发系数过高而失效,导致后续“蚂蚁”(任务)被迫选择次优路径,最终引发产线资源冲突,更严重的是,平台未设置信息素浓度的动态阈值,当局部路径信息素浓度过低时,系统未触发重新探索机制,而是让AGV在原地“徘徊”,进一步加剧了拥堵。
这一场景与2026年2月丰田汽车九州工厂的类似事件形成呼应,当时,其数字孪生平台在处理冲压线与焊接线的物料交接时,因蚁群算法的“启发式因子”(heuristic factor)权重设置过高(偏向距离最短而非负载均衡),导致3台AGV在同一个物料缓存区“撞车”,停机时间达6小时,丰田事后调整算法,将设备负载状态纳入启发式因子计算,问题得以解决。
蚁群算法的工业适配:从“理论最优”到“工程可行”
工业场景对蚁群算法的改造,远不止调整几个参数那么简单,2026年5月,麻省理工学院(MIT)在《自然·计算科学》期刊上发表的研究指出,工业数字孪生中的蚁群算法需解决三大核心矛盾:
本月物联网应用与科技创新及绿色低碳热度持续攀升,相关应用不断深化 
实时性 vs. 收敛性
传统蚁群算法需通过多轮迭代逼近最优解,但工业生产要求毫秒级响应,在2026年3月博世力士乐发布的“线性运动系统数字孪生平台”中,算法被改造为“增量式更新”:每只“蚂蚁”仅更新其经过路径的信息素,而非全局更新,使计算量减少70%,同时通过引入“预测信息素”(基于历史数据的预分配)提前规避拥堵。
确定性 vs. 随机性
工业设备对指令的确定性执行与蚁群算法的随机探索存在冲突,施耐德电气在2026年4月推出的EcoStruxure工业数字孪生解决方案中,采用了“分层蚁群算法”:底层(设备控制层)使用确定性规则(如固定优先级调度),中层(产线协调层)引入随机探索,上层(工厂优化层)则回归确定性优化,这种设计使某化工企业的反应釜温度控制精度提升了40%。
静态模型 vs. 动态环境
工厂的物理环境(如设备故障、订单变更)会频繁变化,而传统蚁群算法依赖静态模型,2026年6月,海尔智家在青岛的“灯塔工厂”中试验了一种“自适应蚁群算法”:通过在虚拟模型中嵌入“环境感知模块”,实时监测设备健康状态与订单波动,动态调整信息素挥发系数与启发式因子,测试数据显示,该算法使产线换型时间缩短了35%,而传统算法仅能缩短18%。
算法之外的“隐形挑战”:数据质量与组织协同
低碳办公与节能减排热度持续上升,相关领域迎来新发展 蚁群算法的工业应用,还面临两个常被忽视的瓶颈:数据质量与组织协同,以2026年5月通用电气(GE)在印度普纳的航空发动机工厂为例,其数字孪生平台初期因传感器数据误差率高达12%(主要来自振动传感器的校准偏差),导致蚁群算法生成的路径规划频繁与物理世界冲突,GE通过引入“数据健康度评估模块”,对传感器数据进行实时可信度打分,仅使用高可信度数据参与算法计算,使路径规划成功率从68%提升至92%。

2026年绿色运营链与绿色防洪抗旱及绿色转化热度持续上升,相关领域迎来新机遇 组织协同的挑战则更为隐性,2026年4月,某中国新能源车企在建设数字孪生平台时,发现算法优化后的生产方案常被一线工人“抵制”——某产线的机械臂焊接顺序调整后,工人需跨区域操作,增加了劳动强度,该企业最终通过“人机协同工作坊”,让工人参与算法参数的调试(如调整信息素挥发系数以平衡效率与操作便利性),才使方案得以落地。
从“算法中心”到“场景中心”
工业数字孪生中的蚁群算法,正在从“追求理论最优”转向“解决实际痛点”,2026年6月,西门子与弗劳恩霍夫研究所联合发布的《工业数字孪生算法白皮书》提出,下一代算法需具备三大能力:
- 场景感知:通过数字孪生模型的实时反馈,动态识别生产瓶颈(如某台设备的利用率突增);
- 容错设计:在算法中嵌入“安全阈值”,当优化结果可能导致设备过载时,自动触发保守策略;
- 可解释性:将算法决策过程转化为工人可理解的规则(如“因AGV A的电池电量低于20%,优先为其分配短路径任务”)。
这些改进正在落地,2026年7月,宝马集团在德国莱比锡工厂的数字孪生平台中,试点了一种“可解释蚁群算法”:当算法建议调整产线节奏时,系统会同步生成“决策依据图谱”,显示信息素浓度分布、设备负载状态等关键数据,帮助工程师快速验证方案合理性,试点期间,产线调整的决策时间从平均2小时缩短至20分钟。
算法与工业的“双向驯化”
工业数字孪生中的蚁群算法,本质是一场“双向驯化”:算法需要适应工业场景的复杂性、实时性与确定性要求,而工业场景也需要为算法提供高质量的数据与协同机制,斯图加特事故的教训在于,过度依赖理论模型的“优雅”,而忽视了工程实现的“粗糙”——工业现场没有完美的环境,只有不断迭代的适配。
正如2026年8月《哈佛商业评论》在专题报道中所言:“未来的工业算法,将不再是藏在黑箱中的数学公式,而是与工人并肩作战的‘数字伙伴’。”这场变革,或许正是数字孪生技术从“炫技”走向“实用”的关键一步。